
Zookeeper学习记录
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务linux上安装:官网下载地址:Apache Downloads1.下载下来选择自己的目录解压,tar -zxvf 压缩包2.解压以后,直接在bin的目录下执行 ./zkServer.sh 启动会失败,因为conf下缺少zoo.cfg文件3.将conf下的zoo_sample.cfg改为zoo.cfg# zookeeper时间配置的
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务
应用场景
统一命名服务(域名服务)
统一配置管理(一个集群中的所有配置都一致,且也要实时更新同步)
将配置信息写入ZooKeeper上的一个Znode,各个客户端服务器监听这个Znode。一旦Znode中的数据被修改,ZooKeeper将通知各个客户端服务器
统一集群管理(掌握实时状态)
将节点信息写入ZooKeeper上的一个ZNode。监听ZNode获取实时状态变化
服务器节点动态上下线
软负载均衡(根据每个节点的访问数,让访问数最少的服务器处理最新的数据需求)
linux上安装:
官网下载地址:Apache Downloads
1.下载下来选择自己的目录解压,tar -zxvf 压缩包
2.解压以后,直接在bin的目录下执行 ./zkServer.sh 启动会失败,因为conf下缺少zoo.cfg文件

3.将conf下的zoo_sample.cfg改为zoo.cfg
# zookeeper时间配置的基本单位
tickTime=2000
# follower允许初始化连接leader的最大时长,表示ticktime的时间倍数
# synchronization phase can take
initLimit=10
# follower与leader的数据同步的最大时长,表示ticktime的时间倍数
# sending a request and getting an acknowledgement
syncLimit=5
# 数据目录
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect默认端口
clientPort=2181
# the maximum number of client connections.
# 单个客户端与zookeeper的最大并发连接数
maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# 保存数据快照额数量之外的将被清除
autopurge.snapRetainCount=3
# Purge task interval in hours
# 自动触发清除任务的时间间隔,小时为单位,为0 ,表示不清除
autopurge.purgeInterval=1
4.采用指定配置文件的方式启动 ./zkServer.sh start ../conf/zoo.cfg,
启动失败注意:防火墙未关闭、端口8080被占用了
简单命令
服务端:
启动zookeeper: ./zkServer.sh start ../conf/zoo.cfg
查看状态zookeeper: ./zkServer.sh status ../conf/zoo.cfg
停止zookeeper: ./zkServer.sh stop ../conf/zoo.cfg
客户端:
进入客户端:./zkCli.sh
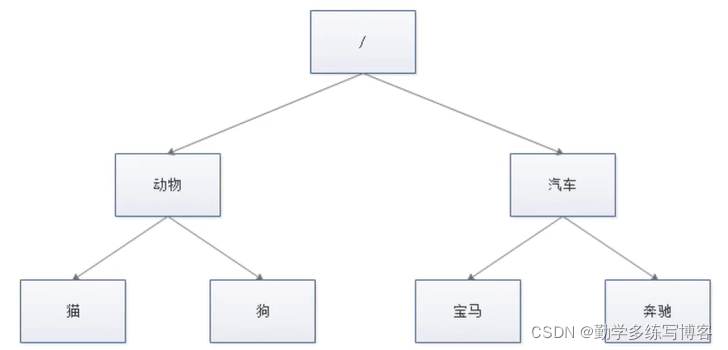
查看内容: ls /zookeeper 内部数据模型
zookeeper如何保存数据的:
有点类似一个树形结构,节点就是znode,多个znode组成一个树的目录结构,不同于树形结构,znode的引用方式是路径引用,类似文件路径,每一个 ZNode 默认能够存储 1MB 的数据
命令比较简单,随便输入不合法的命令,会有提示
znode的结构包含四部分:
data: 保存数据
acl: c:创建 w:写的 r:读的 d:删除 a:admin
stat:描述当前znode的元数据
child:当前节点的子节点
znode节点的类型:
持久节点:创建出来的节点,会话结束依然存在
持久序号节点:创建出来的节点,根据先后顺序会在节点之后带上一个数值,越往后执行顺序越大,适合分布式锁的应用场景
临时节点:会话结束后,会被删除,通过这个特性zk可以实现注册与发现。
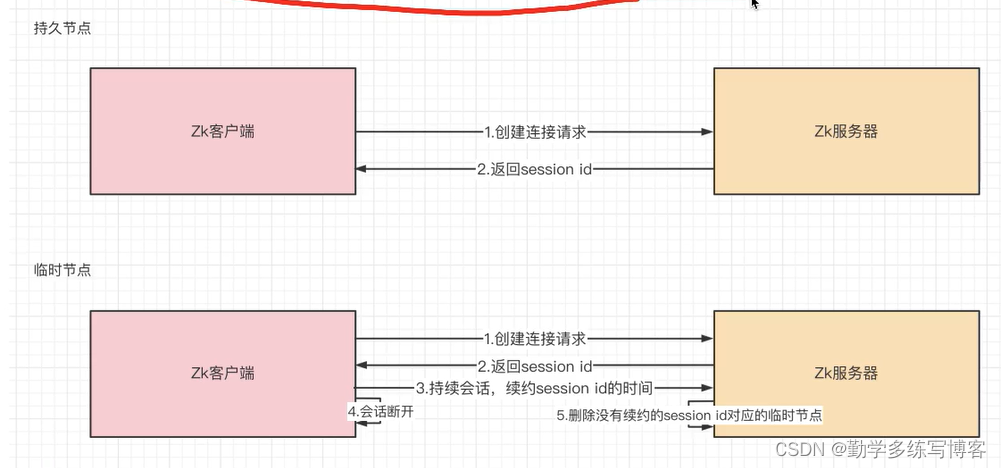
临时序号节点:跟持久序号节点相同,适合临时的分布式锁
container节点:容器节点,当容器中没有子节点,会被zk定期删除
TTL节点:可以指定节点的过期时间,过期被zk自动删除,只能通过系统配置zookeeper.extendedTypesEnabled开启
zookeeper数据持久化:
zk的数据是存在内存里面的,zk提供了两种持久化机制。
事务日志:
zk把执行的命令以日志的形式保存到dataLogDir指定的路径中的文件中,如果没有指定的dataLogDir,则按dataDir指定的路径
数据快照:
zk会在一定时间间隔内做一次内存数据快照,把当前的内存数据存到快照文件里
zk通过两种消息的持久化,恢复数据时先恢复快照文件中的数据到内存,再用日志文件中的命令做增量恢复,这样恢复更快
节点命令:
查询节点信息:get -s 节点

删除节点:
delete 节点
delete -v (数据版本) 节点
权限命令:
addauth digest yang:123456
create /test-node abcd auth:yang:123456:cdwra
zk的分布式锁:
读锁:获取读锁,必须要之前没有写锁
写锁:获取写锁才可以写,之前没有任何锁
zk如何上读锁:
创建一个临时节点序号,节点的数据是read,表示读锁
获取zk中序号比自己小的所有节点
判断最小节点是否是读锁:
不是读锁,加锁失败,为最小的节点设置监听,阻塞等待,zk的watch机制会当最小节点发生变化时,通知当前节点,再执行第二步的流程
是读锁,上锁成功
zk如何上写锁:
创建一个临时节点序号,节点的数据是write,表示写锁
获取zk中的所有子节点
判断自己是否是最小的节点
如果是,则上写锁成功。
如果不是,说明前面还有锁,则上锁失败,监听最小的节点,如果最小的节点有变化,回到第二步。
羊群效应:上述的上锁方式,只要节点发生变化,就会触及其他节点的监听事件,这样的话对zk的压力非常大,可以调整为链式监听,每个只监听上一个节点
ZK的watch机制:
watch可以理解成注册在特定Znode上的触发器,当这个znode发生改变,也就是调用了create,delete,setData将会触发znode上对应的注册事件,请求Watch的客户端将会收到异步通知。
watch命令:
create 节点
监听某个节点:get -w 节点
监听目录:ls -w 节点
监听目录的子目录:ls -R -w 节点
zookeeper集群:
zookeeper集群角色:
Leader:处理集群中的所有事务请求,集群中只有一个leader
Follower:只能处理读请求,参与leader的选举
Observer:只能处理读请求,提高集群读的性能,不参与leader的选举
集群配置:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/zookeeper/zk1
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
#quorumListenOnAllIPs=true
#admin server 默认8080
admin.serverPort=8081
#注:集群的当前服务器地址必须为0.0.0.0 ,由于一台服务器所以都设置为0.0.0.0
#2001这类是通信端口,3001是选举端口
server.1=0.0.0.0:2001:3001
server.2=0.0.0.0:2002:3002
server.3=0.0.0.0:2003:3003
server.4=0.0.0.0:2004:3004:observer1、编写myid文件,为一个数字,不可重复,在配置文件的datadir指定目录
2、编写多个配置文件,如上配置,修改dataDir,serverPort,clientPort,采用配置文件方式启动
命令:./zkServer.sh start 配置文件
客户端连接集群:
好处:一个节点崩溃,会尝试连接其他地址
./zkCli.sh -server 集群地址
ZAB协议:
解决了zookeeper崩溃恢复和主从数据同步问题
ZAB四种协议节点状态:
Looking:选举状态
Following:从节点所处的状态
Leading:主节点所处的状态
Observing:观察者节点所处的状态
zookeeper选举过程:
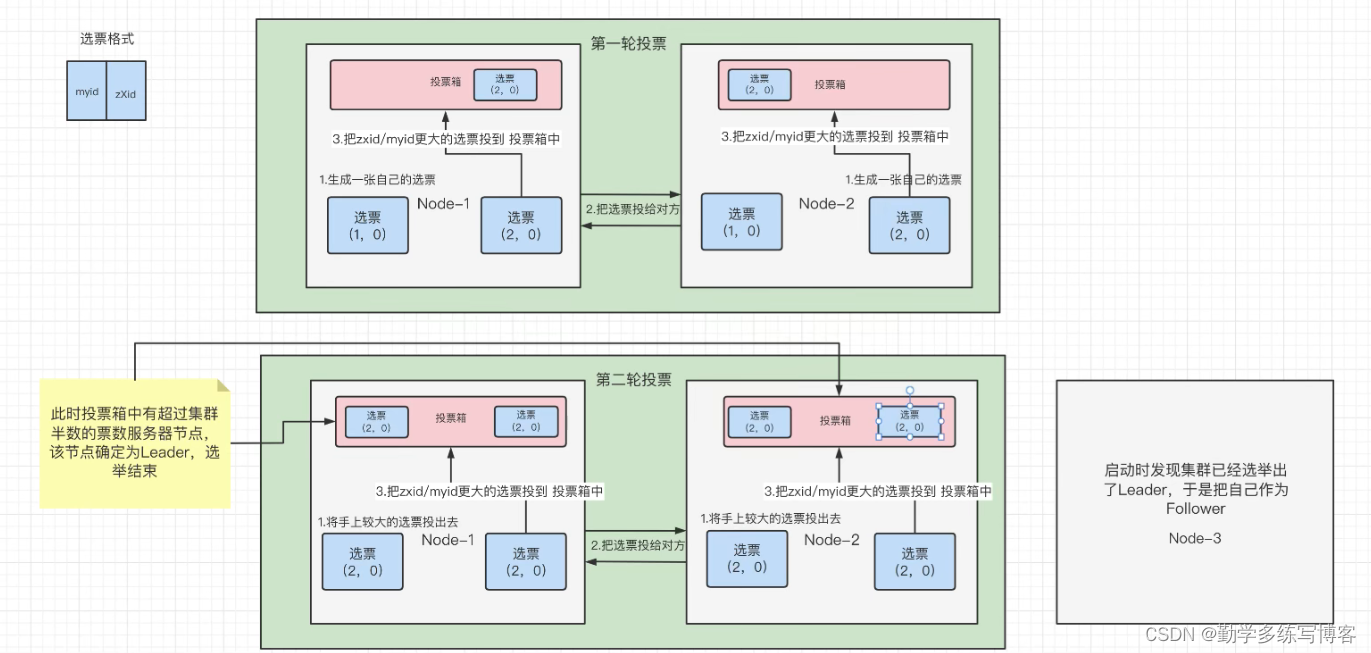
myid:配置文件id zXid:事务id
zXid比较大的会被优先放入投票箱;
zXid相同,myid比较大的放入投票箱;
投票箱超过半数的节点,被选作Leader节点,节点数在配置文件中配置可见,奇数节点更容易判断超过半数


崩溃恢复时的leader选举:
Leader建立完成后,Leader周期性的向Follower发送心跳(ping命令,没有内容的socket),Leader崩溃以后,Follower发现socket通道关闭,Follower的状态从Following变成Looking,重新回到Leader选举状态,此时集群不对外提供服务
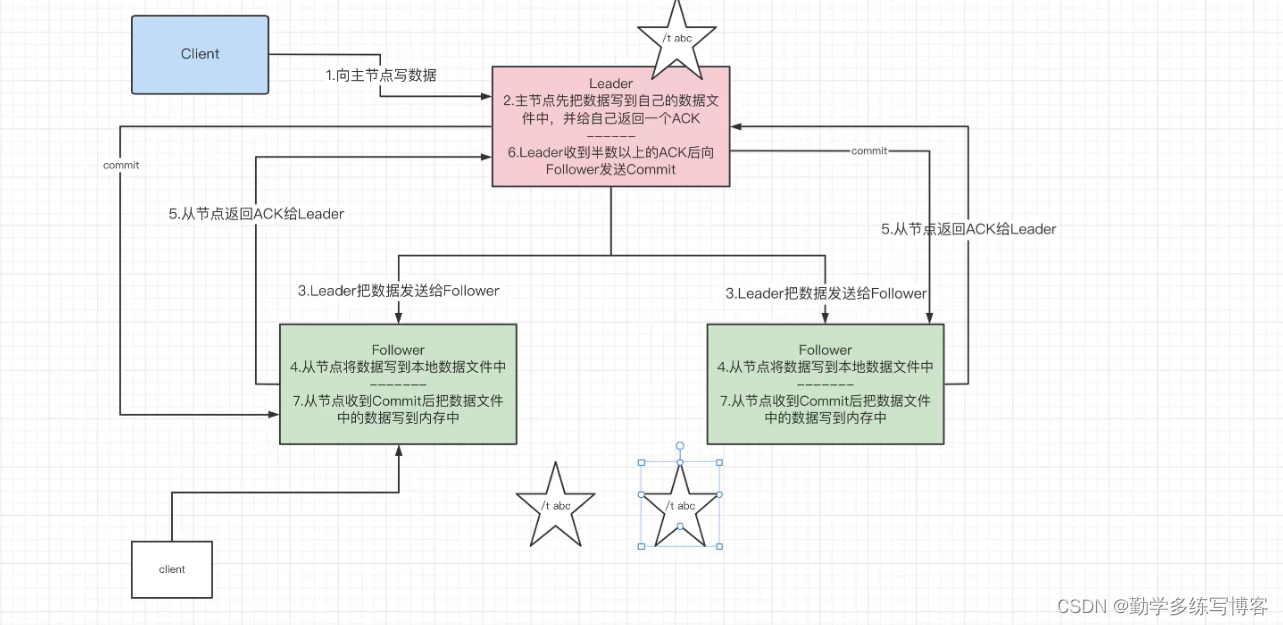
主从服务器之间的数据同步:
zookeeper中的NIO和BIO:
BIO:集群选举时,多个节点的投票通信端口,采用BIO
NIO:被客户端连接的2181端口,使用的是NIO模式与客户端连接
客户端开启watch时,也使用的NIO,等待zookeeper服务器的回调
BASE理论:基本可用,软状态,最终一致性
zookeeper追求的一致性:数据同步时,不要求强一致,而是顺序一致性,因为事务id递增,可以保证
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)