登录社区云,与社区用户共同成长
邀请您加入社区
暂无图片
Smokescreen作为一款简单的HTTP代理工具,能够有效过滤不良URL,保障网络访问安全。然而,在高并发场景下,代理效率可能成为瓶颈。本文将分享10个实用的Smokescreen性能优化技巧,帮助你充分发挥这款代理工具的潜力,提升代理速度与稳定性。## 1. 合理配置连接超时时间连接超时设置是影响Smokescreen性能的关键因素之一。通过调整超时时间,可以有效避免因网络延迟或目标
KBFS(Keybase Filesystem)作为一款分布式文件系统,为用户提供了安全、高效的文件存储与共享解决方案。它将文件加密、版本控制和分布式存储完美结合,重新定义了现代分布式文件系统的标准。本文将深入剖析KBFS的架构设计与实现原理,带您全面了解这一创新技术的核心魅力。## 一、KBFS核心架构概览 📊KBFS采用分层架构设计,主要由客户端层、协议层和存储层构成。客户端层负责用
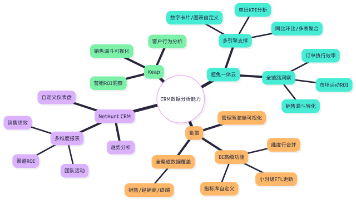
在中小企业数字化转型进程中,客户关系管理(CRM)系统已成为串联销售、运营、售后全链路的核心枢纽。不同品牌的CRM在核心业务环节的设计逻辑与能力覆盖差异显著,直接影响企业运营效率与客户体验。本文选取超兔一体云、NetHunt CRM、Streak CRM、华邦云、勤策、OnePageCRM、Keap七款主流产品,从线索抓取、订单跟踪、数据分析、预算管控、售后工单五大核心维度展开深度横向对比,为企业
本文深入探讨了企业级SSD从U.2向EDSFF标准升级的实战避坑指南。面对PCIe 5.0/6.0带来的带宽与散热挑战,EDSFF提供了更优的信号完整性、散热设计和形态灵活性。文章聚焦于兼容性、供电散热等核心难点,并结合金融、医疗等行业场景,提供了平滑过渡的混合部署策略与分阶段实施方案,助力数据中心实现稳定高效的存储升级。
Scrapy-Cluster是一个基于Redis和Kafka构建的分布式按需抓取集群项目,它将Scrapy框架的强大抓取能力与分布式系统的高可用性和可扩展性完美结合。本文将深入解析Scrapy-Cluster的核心组件,揭秘Redis与Kafka如何协同工作,构建高效稳定的分布式抓取架构。## 一、Scrapy-Cluster整体架构概览 📊Scrapy-Cluster的架构设计充分体现
本文详细介绍了在PyTorch分布式训练中启用TORCH_DISTRIBUTED_DEBUG环境变量的三种实用方法:终端设置、单行命令和Python脚本内动态控制。通过实战案例解析了不同调试级别(INFO/DETAIL)的输出差异,并指导如何解读日志以诊断通信超时、性能下降及梯度同步等常见问题,是提升分布式训练调试效率的必备指南。
AI与低代码的深度融合,并非简单的技术叠加,而是软件开发范式的根本性变革。它彻底打破了技术对企业数字化建设的壁垒,让业务人员真正参与到系统开发中,实现了“业务驱动开发”的核心目标;同时突破了传统低代码的能力边界,让低代码平台能承接企业核心业务系统的开发,成为企业数字化建设的核心引擎。从行业发展来看,低代码不再是“玩具工具”,而是经过AI技术重构的企业级智能开发平台,正在成为企业数字化转型的标配。
本文针对传统羊场养殖数据管理效率低、信息化不足的问题,设计开发了一套基于SpringBoot框架的羊场养殖数据管理与分析系统。系统采用B/C模式,使用Java和MySQL技术,实现了员工信息、饲料供给、生产报表、养殖环境等核心模块。通过划分管理员和员工两种角色权限,确保了系统的安全性和易用性。系统设计注重高内聚低耦合原则,具备良好的扩展性和稳定性,为羊场养殖提供了高效、便捷的信息化管理解决方案,为
CRUSH算法是Ceph分布式存储系统的核心数据分布机制,它通过ClusterMap、数据分布策略和随机数共同决定数据存储位置。算法考虑存储设备的权重(基于容量和性能)、集群拓扑结构(如机架、服务器、磁盘层级)以及管理员配置的故障域(如Host或机架级别)和冗余策略(副本或纠删码)。计算过程包括对对象ID进行哈希运算,结合PoolID和OSD数量确定PG(Placement Group)ID,确保
本文深入剖析了Transformer模型训练缓慢的核心原因——其注意力机制带来的O(N²)时间复杂度。通过详细的数学推导,解释了序列长度N的平方项如何成为计算瓶颈,并探讨了其对显存和分布式训练的影响。文章还提供了从算法创新(如稀疏注意力)到工程优化(如算子融合)的实战策略,帮助开发者有效应对这一挑战。