
OpenClaw Gateway大揭秘:不止是API网关,更是智能体系统的神经中枢!
* Gateway 的整体定位与生命周期* 全渠道接入:插件化与适配器模式* 消息路由:精准投递到 Agent 会话* Agent 装配:构建知识与能力上下文* 分布式架构:给 Agent 配备远程“手脚”* 配置热重载:不停机的“换引擎”
本篇解读 OpenClaw Gateway 以下方面的设计:
- Gateway 的整体定位与生命周期
- 全渠道接入:插件化与适配器模式
- 消息路由:精准投递到 Agent 会话
- Agent 装配:构建知识与能力上下文
- 分布式架构:给 Agent 配备远程“手脚”
- 配置热重载:不停机的“换引擎”
PART 01
Gateway 的整体定位与生命周期
看到 Gateway 这个词,第一反应往往是 API 网关。但 OpenClaw 的 Gateway 更接近 Kubernetes 的 Control Plane — 它不仅负责转发请求,还承担着调度、安全控制、状态管理甚至运维治理等一整套系统级职责:
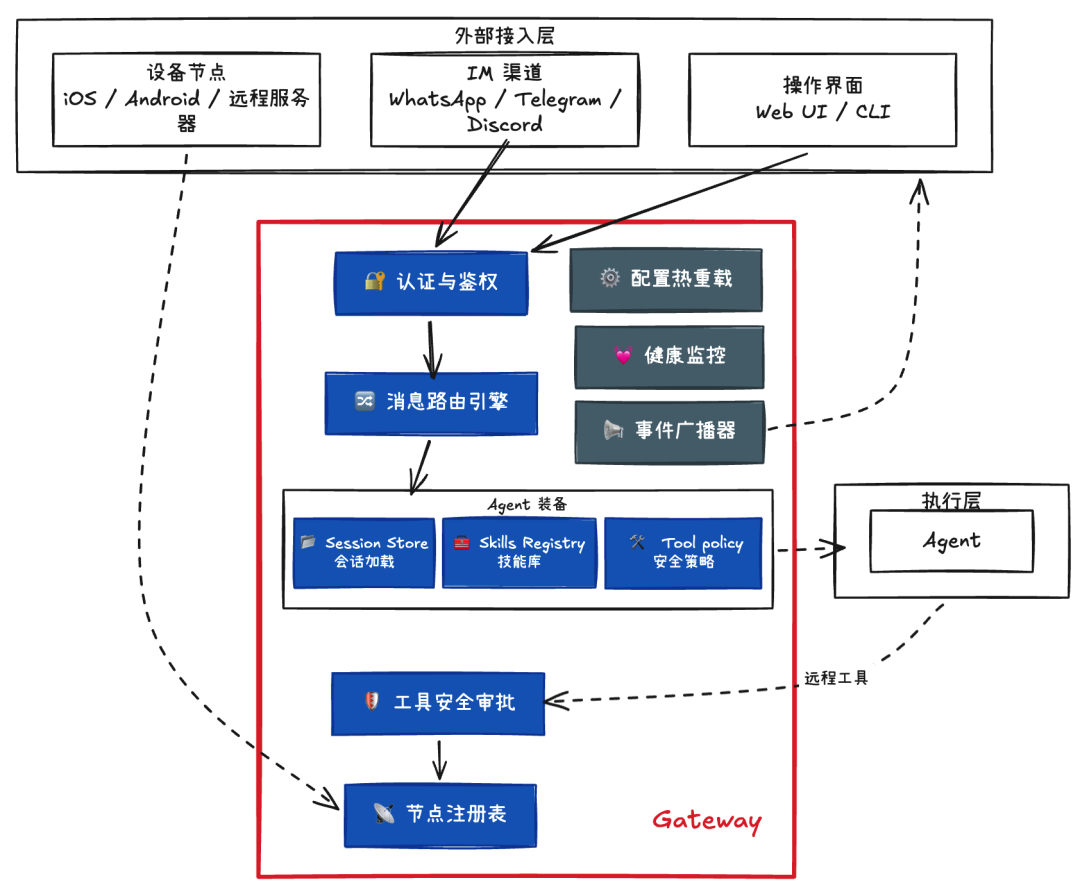
从运行流程上看,Gateway 对 Agent 的主要管控大致有:
- 接入与路由
所有消息(IM 渠道、Web UI、CLI 等)都会先进入 Gateway。系统在这里统一完成身份认证与权限校验,随后由路由引擎分发到正确的 Agent。
- Agent 装备与调用
在任务真正交给 Agent 之前,Gateway 会完成一些准备工作:
加载历史 Session(注入状态)、查找可用 Skills(注入技能)、计算当前可用的工具集合(执行 Tool Policy)。
经过这一阶段后,Agent 才会获得一套已经准备好的运行上下文。
- 远程 Agent 工具执行
当 Agent 需要调用远程节点工具(例如在手机上触发拍照)时,会先回调 Gateway 进行安全审批。审批通过后,Gateway 再将命令下发到对应节点。
Gateway 的核心职责可以归纳为:
| 职责 | 说明 |
|---|---|
| 统一接入 | 全渠道(Channel)消息统一接入 |
| 消息路由 | 将消息精准投递到正确的 Agent + Session |
| Agent 装备 | 注入 Session 状态、Skills、可用工具集 |
| 远程工具安全 | 命令白名单 + 人工审批双重管控 |
| 设备(节点)管控 | 远程节点注册、配对、命令下发 |
| 运维治理 | 配置热重载、健康监控、事件广播等 |
【关键解读】
在 OpenClaw 中,Gateway 并不是一个简单的透明转发层:消息进入系统 → 交给 Agent → 在运行过程中进行工具拦截或限制。
OpenClaw 的做法是把 Agent 的控制逻辑上提到 Gateway。也就是说,不是等 Agent 运行时再进行限制,而是在任务开始前就完成安全边界的装配。Agent 本身只需要专注于推理与执行。
这种“关注点分离”的架构思想,是整个 Agent 系统能够在复杂企业环境中实现可运维、可扩展和可治理的基础。
PART 02
全渠道接入:插件化与适配器模式
OpenClaw 支持大量消息渠道 — 包括 Telegram、WhatsApp、飞书、iMessage 等。不同渠道的 API、消息格式、认证方式以及功能集差异极大。那么问题来了:它是如何优雅地接入这些渠道,并保持系统持续可扩展的?
答案是:插件化 + 适配器模式。
渠道(Channel)插件
在 OpenClaw 中,每一个渠道都被实现为一个独立的插件包:必须实现一套统一接口 ChannelPlugin。
需要注意的是,它不是通过继承一个 BaseChannel 基类的方式,而是通过一组适配器(Adapters)接口来组合能力。每个适配器负责一个独立的关注点:
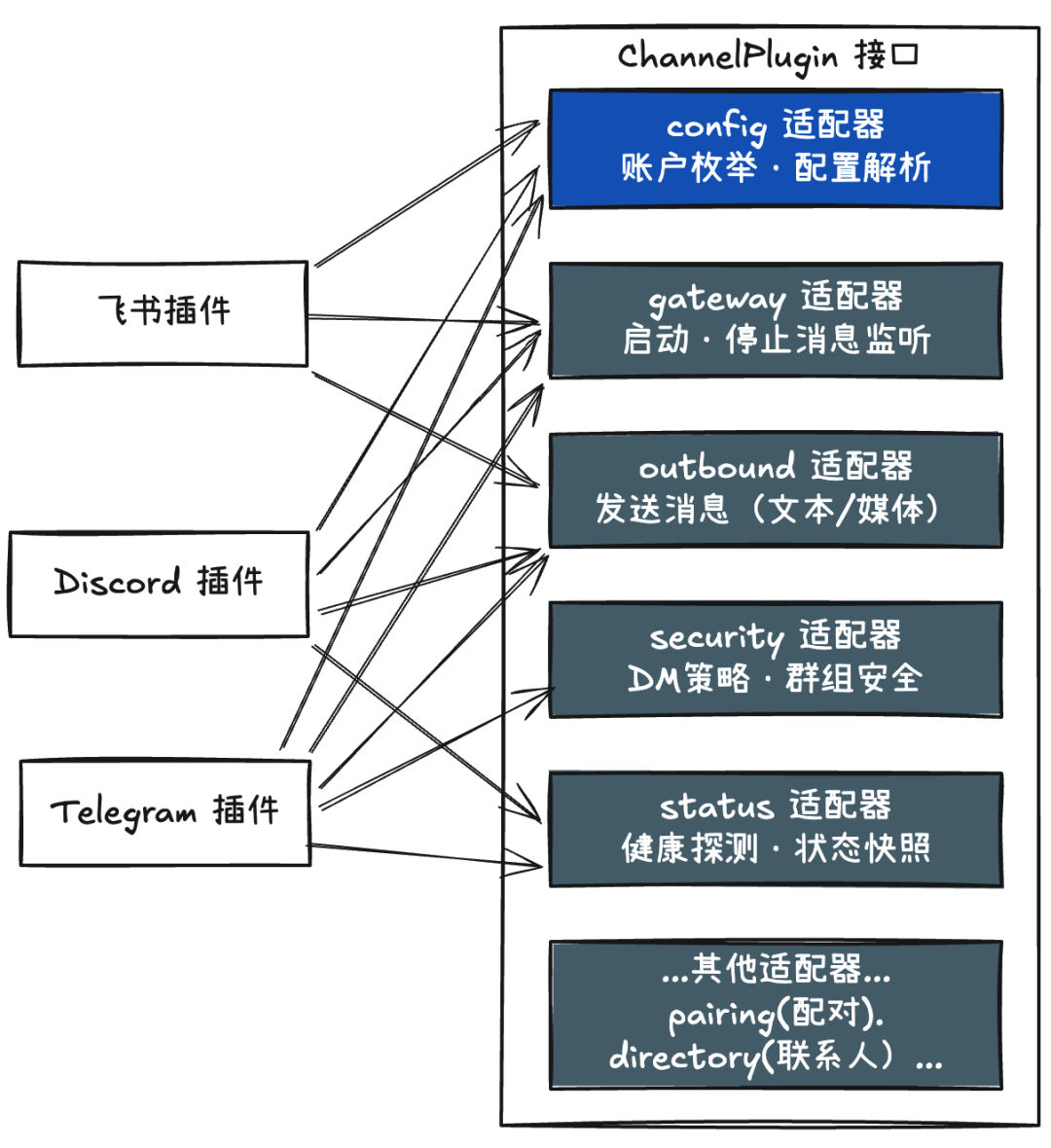
核心思想是:只有少量适配器必须实现,其余是可选能力。比如:
- 简单渠道只需实现配置解析 + 消息发送的能力
- 复杂渠道可以实现更多适配器,例如线程回复、群组管理等
插件通过register方法进行注册,以飞书插件为例:
const plugin = { id: "feishu", name: "Feishu", description: "Feishu/Lark channel plugin", configSchema: emptyPluginConfigSchema(), register(api: OpenClawPluginApi) { setFeishuRuntime(api.runtime); api.registerChannel({ plugin: feishuPlugin }); ...... },};
其中 feishuPlugin 会实现 config、gateway、status、outbound 等多个适配器,把飞书的 Bot API 调用、Webhook、群组策略等封装在插件内部。
OpenClaw 的每种渠道支持多账户。比如你可以同时运行两个 Telegram Bot(对内+对外),每个 Bot 有独立的启停控制和状态管理。
能力声明:让 Gateway 适应渠道差异
不同渠道的功能集差异很大 — Telegram 支持投票和线程,WhatsApp 不支持;Discord 有服务器和角色概念,而iMessage 没有。如何让核心消息处理逻辑适配这些差异?
OpenClaw 的做法是让渠道通过 capabilities 声明告知自己支持什么功能:
exportconst feishuPlugin: ChannelPlugin<ResolvedFeishuAccount> = { id: "feishu", ...... capabilities: { chatTypes: ["direct", "channel"], polls: false, threads: true, media: true, reactions: true, ...
核心代码检查 capabilities.threads/polls 等属性来决定行为 — 不需要知道当前是 Telegram 还是 Discord。
WebSocket:统一的通信层
所有客户端(CLI、Web UI、移动端、远程节点)都会通过 WebSocket 与 Gateway 建立连接。协议基于三类 JSON 帧:
| 帧类型 | 方向 | 用途 |
|---|---|---|
| RequestFrame | 客户端 → Gateway | RPC 调用(如chat.send) |
| ResponseFrame | Gateway → 客户端 | RPC 响应 |
| EventFrame | Gateway → 客户端 | 事件推送(如健康状态、审批请求) |
客户端在建立连接时会进行一次握手。Gateway 会告知客户端当前支持的 RPC 方法与事件列表,客户端据此动态渲染 UI 或执行操作。
作为生产级 WebSocket 通信系统,OpenClaw 设计了完善的容错机制,以应对 Agent 场景中的复杂交互,例如:
- 事件序列号管理与断线检测
- 慢客户端保护(防止发送缓冲区堆积)
- 基于指数退避的自动重连机制
- 流式输出控制(管理持续发送的 Delta 流)
【关键解读】
对于企业级 Agent 系统,如需要支持多渠道接入,可以参考的一些设计有:
- 适配器组合优于继承层次。通过一组可选适配器让渠道按需组合能力,这种组合式架构比继承体系更加灵活。
- 核心代码的可扩展性。新增渠道时,只需要导入插件,并在入口调用注册方法即可,核心代码与配置无需修改,插件管理器(OpenClaw的ChannelManager)通过插件注册表自动发现并管理新渠道。
- 最后是通信机制。在 Agent 系统中,网络通信容易被忽视(往往更关注 Agent 的推理)。但如果系统涉及流式输出、多客户端、远程设备,那么从一开始就需要设计好协议格式、重连策略以及流数据控制等机制。
PART 03
消息路由:精准投递到 Agent 会话
当一条消息从 WhatsApp 或飞书进入系统时,Gateway 需要先回答一个看似简单、实际很关键的问题:
这条消息应该交给哪个 Agent 的哪个 Session?
消息的 Agent 绑定
这并不是查一个简单的路由表那么容易。现实场景往往复杂得多:
- 飞书群组 A 使用 “研究助手” Agent
- 飞书群组 B 使用 “运维机器人” Agent
- 同一个用户在私聊中使用 “默认助手”
- Discord 某个角色组的成员拥有 专属 Agent
为了处理这些复杂情况,OpenClaw 设计了一套 分层优先级消息绑定机制:
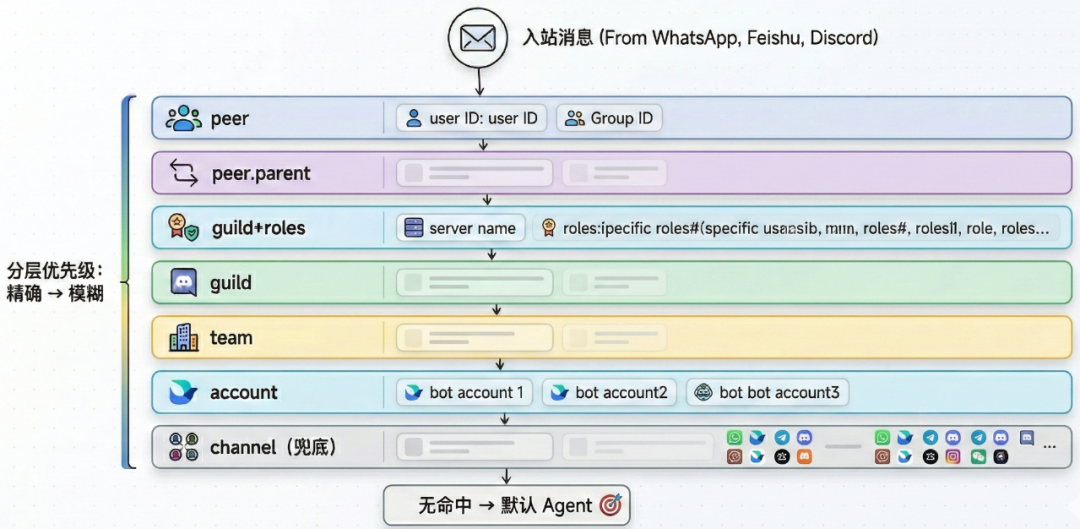
系统会从最精确的规则开始匹配,如果没有命中,再逐级回退到更宽泛的规则,这里通过一些直观场景来理解每一层的含义(Guild/guild+roles层为Discord专属,此处不介绍):
- peer:精确绑定到某个群组或用户。
例如:某个 Telegram 或飞书群 ID 的消息 → 绑定到指定 Agent
- peer.parent:线程消息继承父消息的绑定关系。
例如:Discord 某条消息下的回复 → 自动继承该对话所绑定的 Agent
- team:团队 / 组织级规则。
例如:某个 Slack 租户下所有未匹配的消息 → 统一绑定到某个 Agent
- account:Bot 账号级规则(同一平台可能有多个 Bot)。
例如:来自飞书运维 Bot(app_id: xxx)的消息 → 绑定到运维 Agent
- channel:通道级兜底规则。
例如:所有飞书渠道未命中的消息 → 统一交给该渠道兜底的 Agent
如果一条消息在所有层级都未匹配,则交给默认 Agent进行处理。
Session 隔离策略
路由解决的是 “交给哪个 Agent” 的问题,但还需要解决另一个问题:
这条消息应该在哪个会话上下文中处理?
OpenClaw何时会生成新的会话?
- 全新的渠道、或全新用户的首次使用
- 会话过期:每天凌晨重置或者空闲超时(默认1小时)
- 用户主动发送命令:/new 或者 /reset
一个 Agent 可能同时服务多个用户,因此 Session 的隔离粒度会直接影响用户体验。例如:同一个 Agent 同时服务 100 个用户时,是共享一个上下文,还是每人独立一份?OpenClaw 支持多种隔离策略:
| 模式 | 行为 |
|---|---|
| main | 所有私聊共享一个会话 |
| per-peer | 对话人隔离 |
| per-channel-peer | 渠道+对话人隔离 |
| per-account-channel-peer | 渠道+bot账号+对话人隔离 |
OpenClaw的默认策略是 main — 很显然这是单用户、个人使用优先的默认选择。如果你是在多用户场景下,建议修改成 per-channel-peer策略。
根据 Session 的隔离策略,OpenClaw 会判断消息应该在哪个会话中处理。
此外,OpenClaw 还支持跨平台身份链接。比如,同一个用户在 Telegram 与 WhatsApp 上的身份可以被绑定到同一个用户 ID,从而把两端的消息合并到同一个 Session 中,实现跨平台的上下文连续对话。
【关键解读】
消息路由看起来只是一个技术细节,但它实际上决定了 Agent 系统最基础的用户体验:
消息是否被送到了正确的 Agent?对话上下文是否能够连续?
在简单的个人工具场景中,一般只需要一个默认 Agent 就足够了。但在企业环境中,往往会涉及多群组、多角色、多部门、多机器人等复杂情况,这时就需要更加精细的控制能力。OpenClaw 的分层优先级很好地解决了这个问题:
简单场景可以由默认 Agent 自动兜底,而复杂场景则可以在高优先级层进行精确绑定,两者可以同时存在,互不干扰。
PART 04
Agent 装备:构建知识与能力上下文
在 OpenClaw 中,Agent 本质上是一个ReAct 循环 — 它不知道自己处于哪个会话、该使用哪些工具、能访问哪些能力。所有这些“装备”,都由 Gateway 在交给 Agent 任务前完成组装:
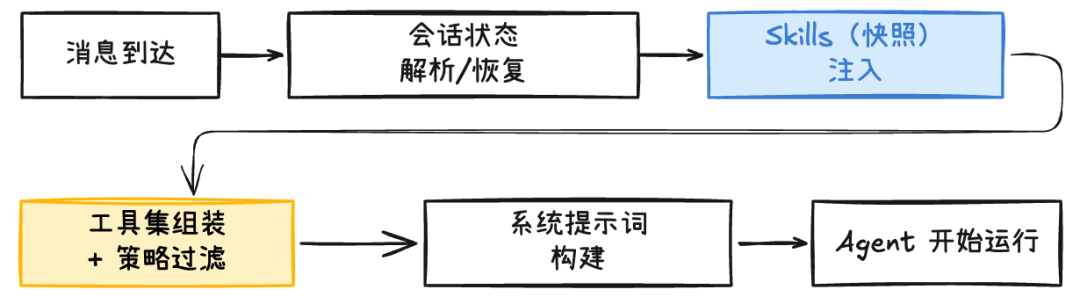
Skills 注入:一次快照,多轮复用
Skills 本质上是一组放在工作区中的 Markdown 文件,用来描述某个领域的操作流程、知识要点或最佳实践。
Agent 启动时会扫描工作区的 Skills,并构建一个技能“快照”,其中包含:
- 过滤后的技能列表
- 格式化后的文本片段(用来注入系统提示词)
- 相关的环境变量覆盖(Skill 可以声明自己依赖的命令路径等)
一些工程上的细节包括:
-
会话内一致性 :Skill 快照只会在新会话的第一轮构建,之后的多轮对话都会复用,不会再次扫描。
-
主动裁剪 :Skill 可以声明自己的平台要求、是否仅限本地等条件。 还支持按 Agent ID 配置白名单,让不同 Agent 看到不同的技能子集。
Skills 最终以格式化文本块注入系统提示词,成为 Agent 的知识上下文。
工具装备:多层过滤取交集
Gateway 在创建 Agent 会话前还需完成另一项关键工作:Tools 的组装与过滤 —系统会先准备一个原始工具集,然后通过一条策略管道(Tool-policy)进行多层过滤。每一层策略都只能收窄能力范围,而不会放宽权限:
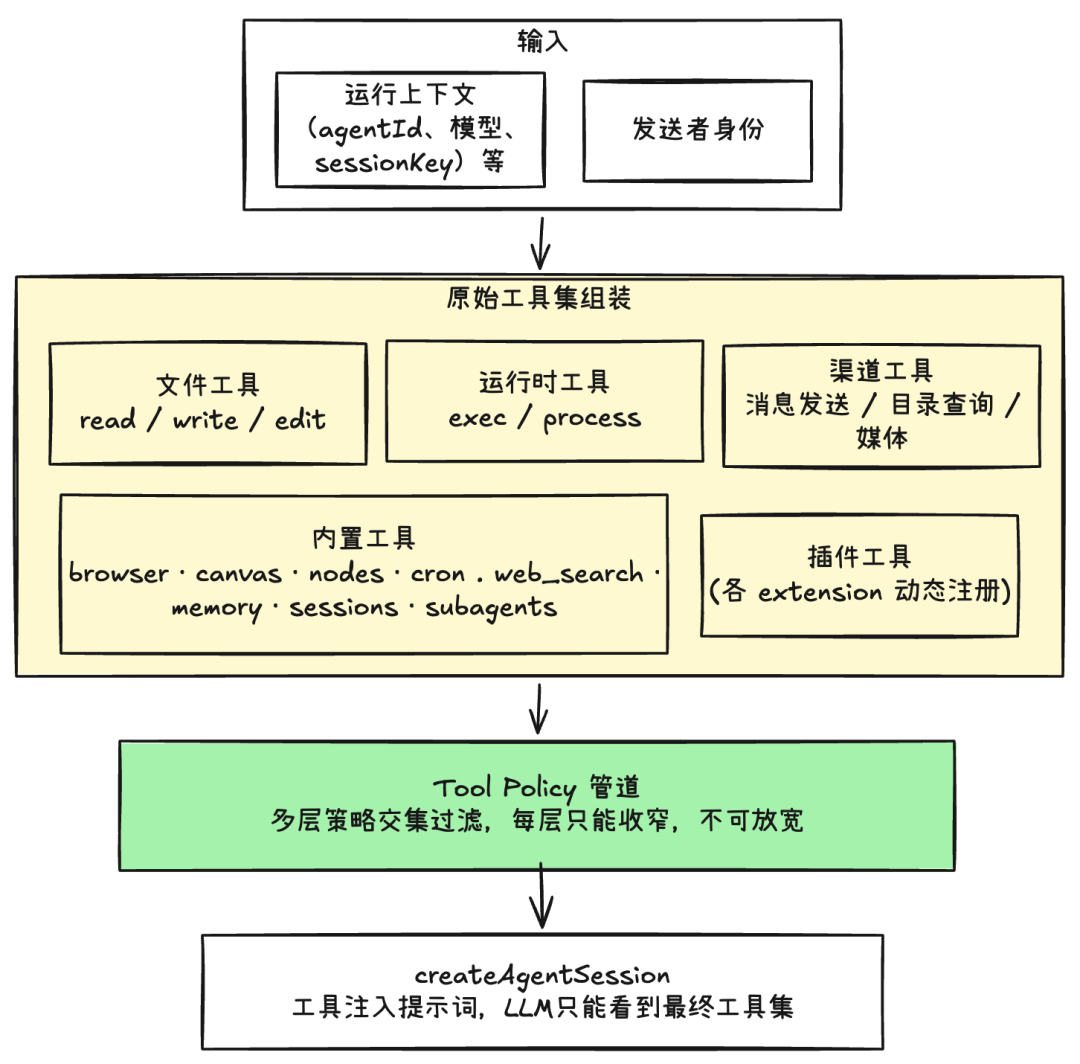
这些过滤层可以理解为一组逐级收紧的安全边界:
-
Owner 门控:身份级别门槛,在进管道之前就隔绝某些高危操作。比如:某些 tool 仅能由渠道的Owner调用
-
Profile:角色模板,定义某类 Agent 的基本能力边界。比如:一个Coding Agent 可能不允许使用web_search工具。
-
Provider Profile:同一 Agent 根据不同模型供应商调整能力边界。比如:切换到 Gemini 时某个工具要被移除。
-
全局策略:组织级别统一规则,所有 Agent 都受约束。比如:组织内所有 Agent 都不能操作远程设备(Nodes)。
-
Agent 策略:精细化到单个 Agent 的工具权限定制。比如:某个分析 Agent 只能读文件和搜索,但不能调用 exec 工具。
-
群组/渠道策略:同一 Agent 在不同渠道/群组中有不同的工具能力。比如:公司公告群里的请求不允许用 exec 工具;但研发群可以。
-
Sandbox 策略:安全隔离环境的硬边界,不可被上层绕过。比如沙箱环境只允许 read 工具,但不允许使用 write 工具。
-
Subagent 策略:框架层面防“递归爆炸”的系统性保护。比如:subagent 不允许使用 spawn 工具再递归产生 subagent。
这些层之间始终是取交集关系。
因此,即使某一层配置错误,也只会进一步收窄权限,而不会意外扩大能力。这种设计允许不同团队独立管理策略,而不会引入权限放大的风险。
Gateway 层还有一个重要职责:远程工具的安全管控。
本地工具会在 Agent 模块内部直接执行,但如果涉及远程 Nodes,则必须通过 Gateway。系统会采用两道关卡:
- 白名单(例如某个 iOS 节点只允许 camera.snap 工具)
- 人工审批(例如调用 sms.send 时需要人工确认)
只有通过这两道检查后,命令才会被下发到远程设备。
【关键解读】
Agent 装备机制的核心思想是:
在 Agent 看到任务之前,就完成最关键的上下文裁剪。
其中Skills 决定的是知识边界;Tools 决定的是能力边界。
OpenClaw 在工具控制上采用了非常清晰的分层安全模型。
第一层是静态管控。
能力过滤在 Agent 启动前完成。Agent 拿到的只是一个已经筛选好的工具集合,它甚至不知道那些被过滤掉的工具存在。
第二层是运行时管控。
在执行过程中跨越信任边界时,Gateway 才会介入。例如,当目标是远程 Node 时,系统才启动审批与安全策略。
这种分层方式避免了两个极端:
- 过度管控:每次工具调用都走安全控制,导致性能与体验下降
- 安全真空:所有工具一视同仁,某些危险操作(远程)缺乏保护
这种根据信任边界动态调整安全管控力度的策略,对于企业级 Agent 系统的设计具有借鉴意义。
PART 05
分布式架构:给 Agent 配备远程“手脚”
在真实使用场景中,你可能会希望:
- Agent 能操控远程服务器(执行部署脚本、查看日志)
- Agent 能调用手机能力(读取日历、获取位置、拍照)
- Agent 能跨设备协同工作
为了解决这些需求,OpenClaw 引入了 **Node(远程节点)**的概念。
可以把 Node 理解为 OpenClaw向外延伸的“四肢”。
远程的 Mac 笔记本、Linux 服务器、iPhone、Android 设备等,都可以作为 Node 接入系统,并向 Agent 提供不同的能力。比如小编将一台 Android 设备通过App接入了Gateway:
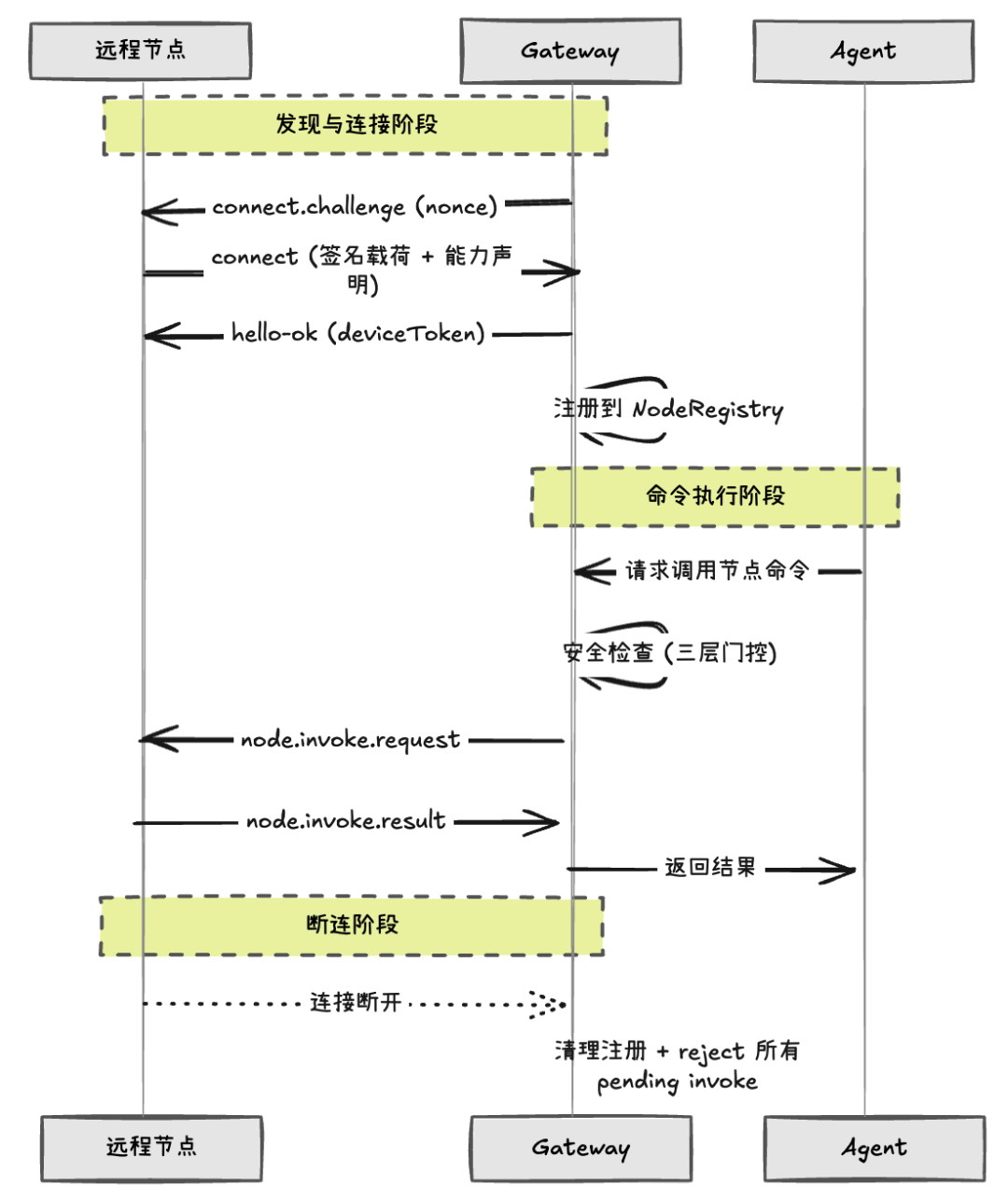
节点的完整生命周期
从设备发现到建立连接,再到执行远程工具,交互流程如下:
一些设计要点:
-
能力声明:新 Node 首次连接时,需要人工审批才能被信任;连接时必须告诉 Gateway 自己支持哪些命令和能力 — 也是后续工具安全的校验依据
-
断连清理 :当 Node 断开连接时,Gateway 会自动拒绝所有尚未完成的远程调用,防止 Agent 的工具请求长时间挂住
-
超时机制 :每次远程调用默认 30 秒超时,超时后自动失败并清理
其他部署形态
除了“本机 Gateway + 远程 Node”的模式,OpenClaw 还支持:
-
远程 Gateway + 本地客户端 :Gateway 与 Agent 部署在 VPS 或企业内网服务器,本地通过 CLI 或 Web UI 远程管理。这种模式适合团队共享
-
远程 Gateway + 本地 Node:Gateway 在云端,本机既是操作者也是Node。Agent 的决策在云端,但工具回到本机执行(访问本地资源)
【关键解读】
远程 Node 架构的核心价值在于能力延伸与聚合。一个 Agent 可以同时调用:
- Linux 服务器上的 system.run 执行部署脚本
- iPhone 上的 calendar.events 查看日程
- Mac 上的 browser.proxy 操作浏览器
这些能力分散在不同设备上,但对于 Agent 来说,它们只是伸出去的“工具”。Agent 并不需要关心命令究竟在哪台设备上执行。
在企业场景中,这种模式也有一定的参考价值。例如:通过运维 Agent 管理多台远程服务器等。
当然,新的挑战是:远程调用的延迟与稳定性会受到网络影响,同时每个 Node 都可能成为潜在的攻击入口。你需要配合一些配对机制、能力声明、白名单等安全措施,来降低风险。
PART 06
配置热重载:不停机的“换引擎”
生产系统中,让人头疼的事情之一是:改个配置就必须重启系统。OpenClaw 为此设计了一套精细的配置热重载机制,核心原则是:
能热更新的就热更新,必须重启的才重启。
Gateway 提供四种重载模式(通过 gateway.reload.mode 配置):
| 模式 | 行为 |
|---|---|
| off | 完全禁用,任何变更都忽略 |
| hot | 仅热重载,需要重启的变更被忽略(不会自动重启) |
| restart | 任何变更都触发 Gateway 重启 |
| hybrid(默认) | 能热更新就热更新,需要重启就重启 |
变更监听与判定
当配置文件发生变化时,Gateway 并不会简单地“全部重载”,而是对每一个配置路径逐一判断应该如何处理:
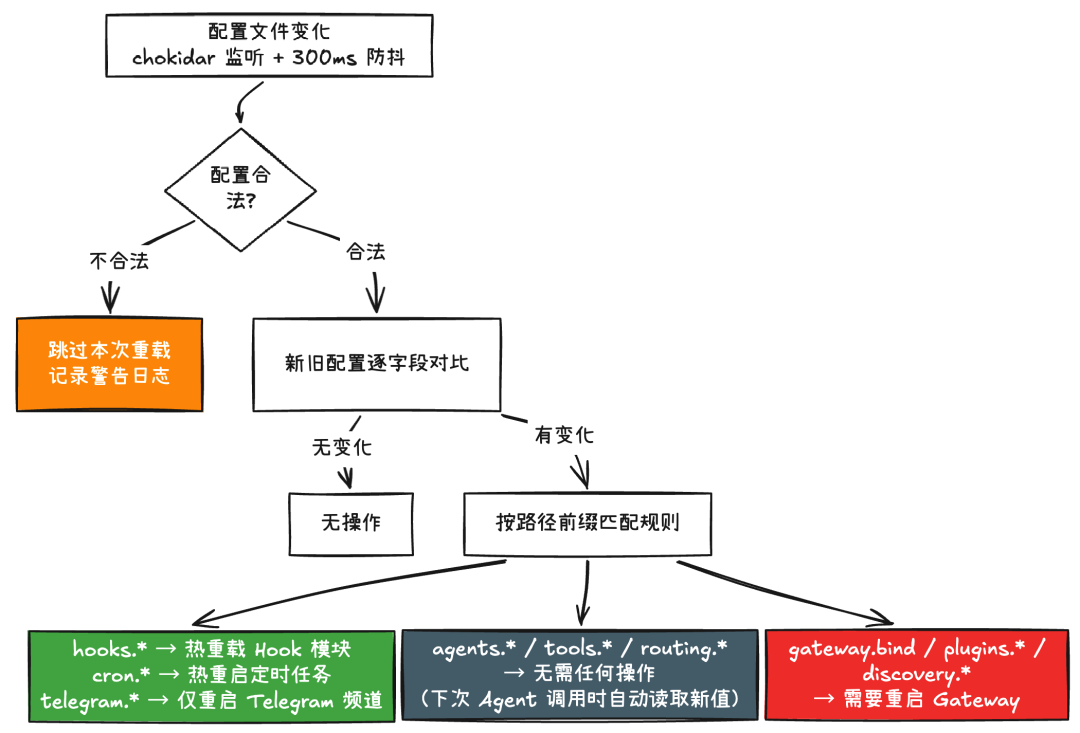
每条规则指定两个属性:kind(热更新 / 需重启 / 无需处理)和 actions(具体的热更新动作,如重启某个模块)。比如:
{ prefix: "hooks.gmail", kind: "hot", actions: ["restart-gmail-watcher"] },// → 改了 hooks.gmail.model,只重启 Gmail 监听器{ prefix: "hooks", kind: "hot", actions: ["reload-hooks"] },// → 改了其他 hook 配置,重载 hook 模块{ prefix: "cron", kind: "hot", actions: ["restart-cron"] },// → 改了定时任务配置,只重启 cron 调度器
这里如果修改了定时任务配置,则只会重启 cron 调度器。
此外,各个 Channel 插件也可以注册自己的重载规则。例如,当 Telegram 的配置发生变化时,只会重启 Telegram 渠道,而不会影响其他渠道。
系统还考虑了一些实际运行中的边界情况。
例如,有些编辑器在保存文件时会先删除旧文件再写入新文件,导致存在一个配置文件短暂消失的“窗口”。Gateway 会对此进行最多两次延迟重试(150ms),并对配置进行校验— 无效配置只会记录警告,而不会让系统进入错误状态。
【关键解读】
OpenClaw 使用声明式规则来实现精细化的热重载。每个模块只需要声明自己关心的配置路径,以及变更后的处理方式,而不需要修改核心重载逻辑。在一个真实的 Agent 系统中,这种机制可以让大部分配置变更对用户几乎无感知。
当然,也需要注意一个问题:如果系统的多个配置之间存在依赖关系时,可能会短暂出现不一致。例如,你只修改了路由规则,但对应的 Agent 配置尚未更新。可以结合一致性检查、审批流程或灰度发布来进一步降低风险。
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
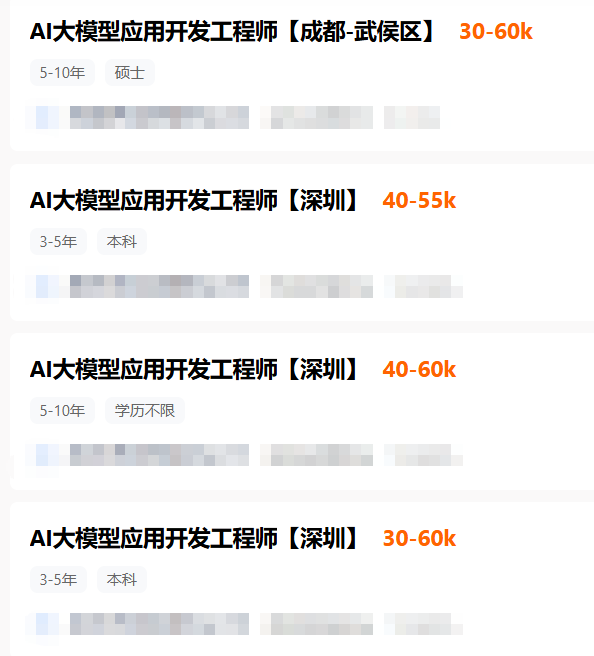
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)