
一口气搞懂 Apache Storm:驾驭实时数据流的分布式引擎
前言
在当今这个数据驱动的时代,批处理“过去的数据”已远远不够,我们需要的是驾驭“现在的数据”。而Apache Storm,正是大数据领域一把锋利的实时计算瑞士军刀。本文将带你深入Storm的核心,揭秘其如何以分布式、高容错的方式处理海量数据流。
一、什么是Apache Storm?
Apache Storm是一个开源的、分布式的、高容错的实时流处理计算框架。
可以把它想象成一个永不停止的实时数据流水线。它被设计用来处理无界的、源源不断的数据流,并以极低的延迟(毫秒级)给出结果。与Hadoop的MapReduce(处理静态的、存储好的数据集)不同,Storm是为永不停歇的实时数据而生的。
核心设计目标:简单、高效、可靠。你可以使用任何编程语言来定义处理逻辑,并将其扩展到数百台机器上稳定运行。
二、Storm的核心概念与主要组件
要理解Storm,首先需要掌握它的几个核心抽象概念。
1.拓扑(Topology)
Topology是Storm中最高级别的抽象,是一个实时流处理的应用程序。它定义了数据从来到去的完整处理逻辑。
-
关键特性:一个Topology一旦提交到Storm集群,就会永远运行,直到你手动终止它。
-
类比:类似于Hadoop的MapReduce Job,但MapReduce Job会结束,而Topology是“永生”的。
2.流(Stream)
Stream是Storm中的核心数据结构,一个无边界的、连续到达的元组(Tuple) 序列。整个Topology就是围绕着一个或多个流来构建的。
3.元组(Tuple)
元组是流的基本数据单元,是一个包含了一个或多个字段的命名值列表。它可以包含任何类型的对象(整数、字符串、字节数组等)。
4. 数据源(Spout)
Spout是Topology的数据来源,是流的“水龙头”。它负责从外部数据源(如Kafka、消息队列、日志文件、API等)读取数据,并将数据封装成元组的形式发射到Topology中。
5. 处理器(Bolt)
Bolt是Topology中的所有处理逻辑的承担者,是数据的“处理器”或“工人”。所有数据处理,如过滤、聚合、连接、查询数据库等,都在Bolt中完成。一个Bolt处理完数据后,可以发射新的流给下一个Bolt。
-
常见的操作:
-
过滤(Filter):只保留感兴趣的数据。
-
聚合(Aggregation):如计数、求和、求平均。
-
连接(Join):将数据流与外部数据源(如数据库)进行关联。
-
函数处理:执行自定义的业务逻辑。
-
数据流向全景图:
一个典型的Topology就是由Spout和Bolt通过流连接而成的有向无环图(DAG)。
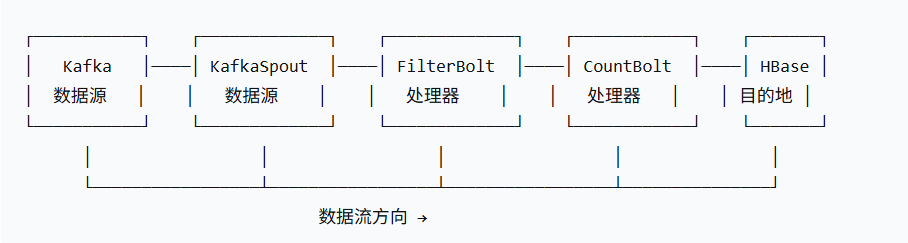
三、Storm的工作环境(集群架构)
一个Storm集群遵循主从(Master/Slave)架构,主要由以下两类节点组成:
1. 主节点(Nimbus)
-
角色:集群的“管理者”或“调度者”。
-
职责:
-
分发代码(Topology的JAR包) across the cluster。
-
为每个Worker分配任务。
-
监控集群状态,并在故障发生时重新分配任务。
-
-
特点:类似于Hadoop中的JobTracker。它的无状态设计使得它失效后重启不会影响现有Topology的运行。
2. 从节点(Supervisor)
-
角色:集群的“工人管理者”。
-
职责:
-
监听Nimbus分配的任务。
-
启动和停止自己机器上的Worker进程。
-
管理本机的物理资源。
-
-
特点:每个从节点上可以运行多个Worker进程。
3. 协调者(ZooKeeper)
-
角色:Storm集群的“神经系统”。
-
职责:
-
协调Nimbus和多个Supervisor之间的状态。
-
存储所有的集群状态和配置信息。
-
实现Nimbus和Supervisor的故障恢复。当Nimbus或Supervisor挂掉时,ZooKeeper能帮助它们快速恢复状态,而不是让整个集群崩溃。
-
四、核心部件工作机制与并发模型
这是Storm最精妙的部分,理解它就能明白Storm为何如此强大。
在Storm的并发模型中,有三个层层包含的关键概念:
1.Worker(进程):
-
一个Worker是一个独立的JVM进程。
-
一个Supervisor节点可以运行一个或多个Worker。
-
一个Topology会分配到一个或多个Worker上运行(跨多个节点)。
2.Executor(线程):
-
一个Executor是一个运行在Worker进程内的独立线程。
-
一个Executor负责执行一个Spout或Bolt的实例。
-
一个Worker进程内可以运行多个Executor线程。
3.Task(任务实例):
-
Task是Spout或Bolt的实际实例,是真正执行数据处理逻辑的实体。
-
在代码中,
Spout或Bolt类本身就是一个Task的蓝图。 -
默认情况下,一个Executor线程只运行一个Task。但你可以通过配置,让一个Executor线程运行多个同类型的Task实例(这在处理CPU密集型操作时很有用,可以避免线程上下文切换的开销)。
Storm提供了7种内置的分组策略,最常用的有:
-
随机分组(Shuffle Grouping):随机、均匀地将Tuple分发到所有下游Bolt的Task上。保证每个Task处理的数据量大致相同。
-
字段分组(Fields Grouping):根据指定的一个或多个字段的值进行分组。相同字段值的Tuple一定会被发往同一个Task。这是实现“按Key聚合”的关键。
-
全部分组(All Grouping):将每一个Tuple复制并发送给所有下游Bolt的Task。常用于广播信号。
-
全局分组(Global Grouping):将所有Tuple发往同一个Task(通常是ID最小的那个)。这会将全局结果集中到一个节点上。
示例场景:
假设我们有一个统计单词数量的Topology:SentenceSpout -> SplitBolt -> CountBolt
-
SplitBolt将句子拆分成单词,并发给CountBolt。 -
为了正确计数,同一个单词必须总是被发往同一个
CountBolt的Task。因此,从SplitBolt到CountBolt的分组策略必须使用 Fields Grouping,分组的字段就是“word”字段。
总结
Apache Storm以其简单明了的编程模型、毫秒级的低延迟、出色的可扩展性和强大的容错能力,成为了实时流处理领域的经典之作。尽管后来出现了如Flink、Spark Streaming等更先进的框架,但Storm的设计思想至今仍深刻影响着流处理技术的发展,并且在许多对延迟极其敏感的生产系统中依然扮演着不可替代的角色。
通过理解其Topology、Spout、Bolt的核心概念,掌握其Nimbus-Supervisor-ZooKeeper的集群架构,并深入剖析Worker-Executor-Task的并发模型与数据分组策略,你就能真正驾驭这只实时计算的“猛兽”,构建出稳定高效的大数据实时处理应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)