
Hadoop3.3.4分布式集群搭建
Hadoop集群的构建大致可以分为三大步:1.ssh的免密配置是为了简化操作流程、提高安全性和效率。2.JDK的部署是因为Hadoop是基于Java语言开发的,其运行环境依赖于Java虚拟机(JVM)。3.1 hadoop-env.sh:这个脚本文件用于设置Hadoop的环境变量,这些环境变量对于Hadoop的正常运行至关重要。3.2 core-site.xml:这个配置文件包含了Hadoop的核
Hadoop3.3.4完全分布式集群搭建【鸣潮版】
文章目录
- 项目背景:
- 一、Hadoop的起源:
- 二、Hadoop系统搭建准备:
-
- 【君·拂】软件的准备及对应版本
- 三、Linux系统免密搭建步骤:
-
- 1.创建三台虚拟机(新手建议装带GUI界面的)
- 2.查看虚拟机的网络配置
- 3.配置三台虚拟机的网络
- 4.进行免密配置
- 四、安装JAVA环境:
-
- 1. 在三台虚拟机上创建文件夹:
- 2. 将JDK安装包和Hadoop包传入虚拟机:
- 3. 查看安装包
- 4. 解压JDK包:
- 5. 添加环境变量
- 6. 使环境变量生效:
- 7. 测试是否生效:
- 8.分发Java环境及环境变量文件:
- 9.使Slave1和Slave2环境变量生效:
- 五、部署Hadoop分布式集群:
-
- 1.解压hadoop安装包:
- 2.修改Hadoop配置文件:
- 3.配置Hadoop的bin和sbin的环境变量:
- 4.分发Hadoop软件包和环境变量文件:
- 5.启动Hadoop集群:
- 6.在Windows上查看Hadoop集群:
- 六、总结:
- 七、后日谈:
项目背景:
你作为今州的令尹,近日收到上级要查今州近10年的税收情况的命令,要你汇报今州的税收财政情况,但税收种类繁多,需要整理的数据太多了,且各级人员调度协调又需要许多时间。可你的上级却只给你三天时间,这可把你愁的连跟漂泊者约会的时间都没了。
第二日,你在今州城中遇到了你的师傅长离和漂泊者,见两人又说有笑的,你顿时十分不爽,于是你向他们走去。走进一瞧,你发现你的师傅竟然在牵着漂泊者的手,你顿时内心警铃大作,你心想我为了税收的情况在忙前忙后的,师傅她居然偷自己的家,你顿时心里就醋意大发,然后就此事问了师傅有何高见,你的师傅向你推荐了一个人,还跟你说他能解你的燃眉之急。
你听说居然还有如此人才,便问此人名字是谁?【君·拂】你的师傅淡淡道。见你等等师傅如此胸有成足,而且眼下此事也确实着急,于是你心想赶紧找这个人【君·拂】来解决此事,然后好腾出时间来跟漂泊者约会,以免夜长梦多。
一、Hadoop的起源:
你回到府尹,连忙找到了【君·拂】,然后问他有没有解决之法,然后【君·拂】就开始了他的长篇大论,他说可以建立一个分布式的集群系统,这个集群系统建立后将拥有以下优势:
扩容能力(Scalable):这个集群在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计的节点中。
成本低(Economical):这个集群通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
高效率(Efficient):通过并发数据,这个集群可以在节点之间动态并行的移动数据,使得速度非常快。
可靠性(Rellable)/高容错性:这个集群能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。
这样就可以在短时间内,对海量的数据进行整理和统计出想要的结构。虽然你啥也听不懂,但你觉得他说得十分厉害,于是就着手安排他全权去做此事,并给了许多支持给他。
他又说如果这个系统真的做出来了,日后必定声名远扬,而你就是提出建造这个系统的主人,日后你的名声必然也会响彻环宇,因此他想让你给这个系统起个名字。你思来想去觉得他说得十分有理,但却又一时间想不出给这个系统应该起什么名字,这时你看到桌子上的一个一个大象,一个名字突然在你的脑海中诞生了——Hadoop!
二、Hadoop系统搭建准备:
【君·拂】软件的准备及对应版本
- VMware版本 【VMware® Workstation 17 Pro】(必需)VMware下载及安装的教程
- xshell 【xshell7】(不是必需) xshell官网下载
- xftp 【xftp7】(不是必需)xftp官网下载
- Linux系统的搭建【使用的镜像源为Centos7】(必需)阿里云Centos7镜像源
- Java环境搭建包【 jdk-8u212-linux-x64.tar.gz】(必需)Java对应的Linux包–官网下载
- Hadoop完全分布式集群搭建所需包 【hadoop-3.3.4.tar.gz】(必需)Hadoop国内镜像源下载地址 Hadoop百度网盘下载地址
【君·拂】PS:hadoop-3.3.4.tar.gz对应的java版本是java8和java11,但java11要在运行时才支持Hadoop,故此【君·拂】采用java8。
三、Linux系统免密搭建步骤:
1.创建三台虚拟机(新手建议装带GUI界面的)
第一台命名为Master:
克隆当前虚拟机,然后重名为Slave1:
重复上一步,然后重命名为Slave2:
2.查看虚拟机的网络配置
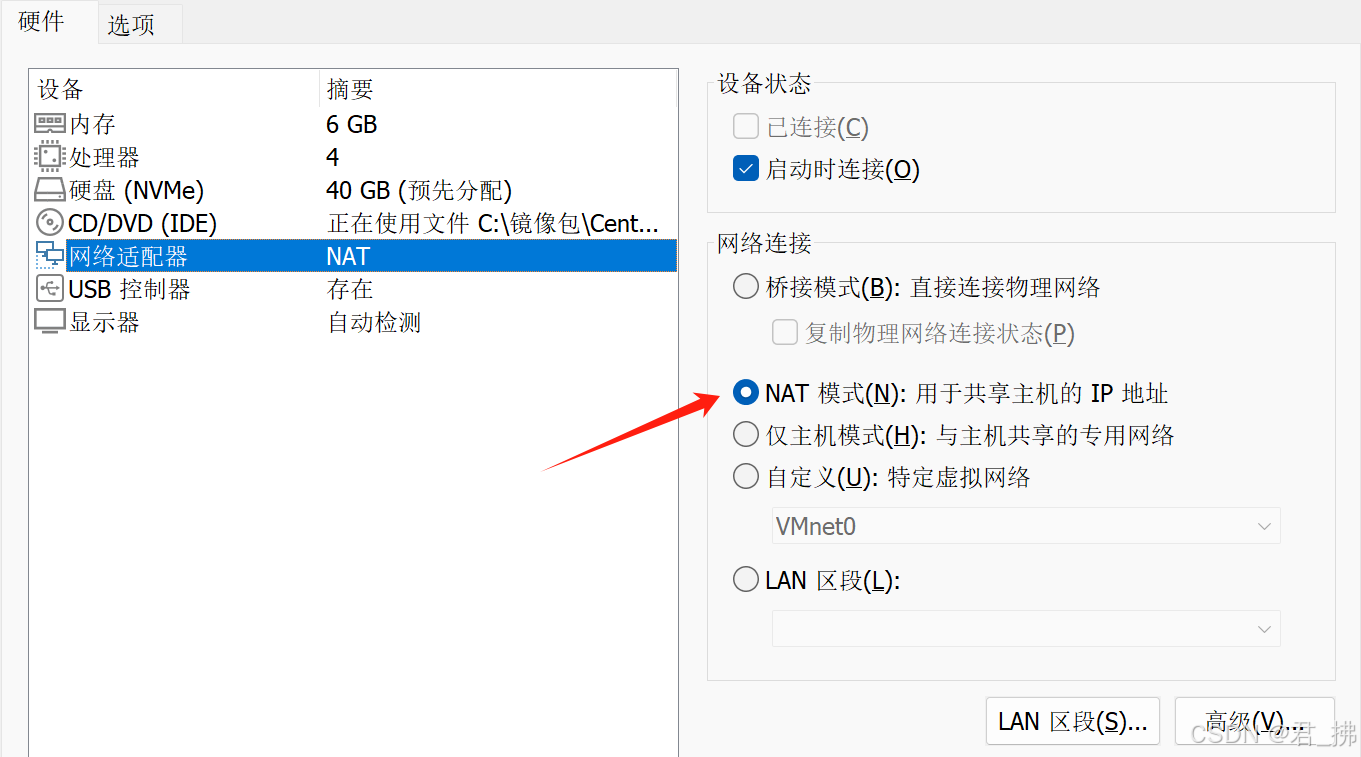
编辑虚拟机选设置:
将网络适配器设置为NAT模式:
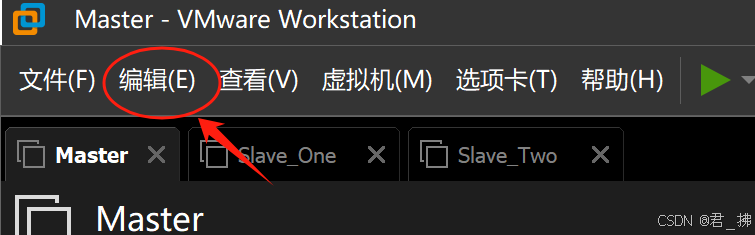
选择导航栏中的编辑,然后选择虚拟网络编辑器:
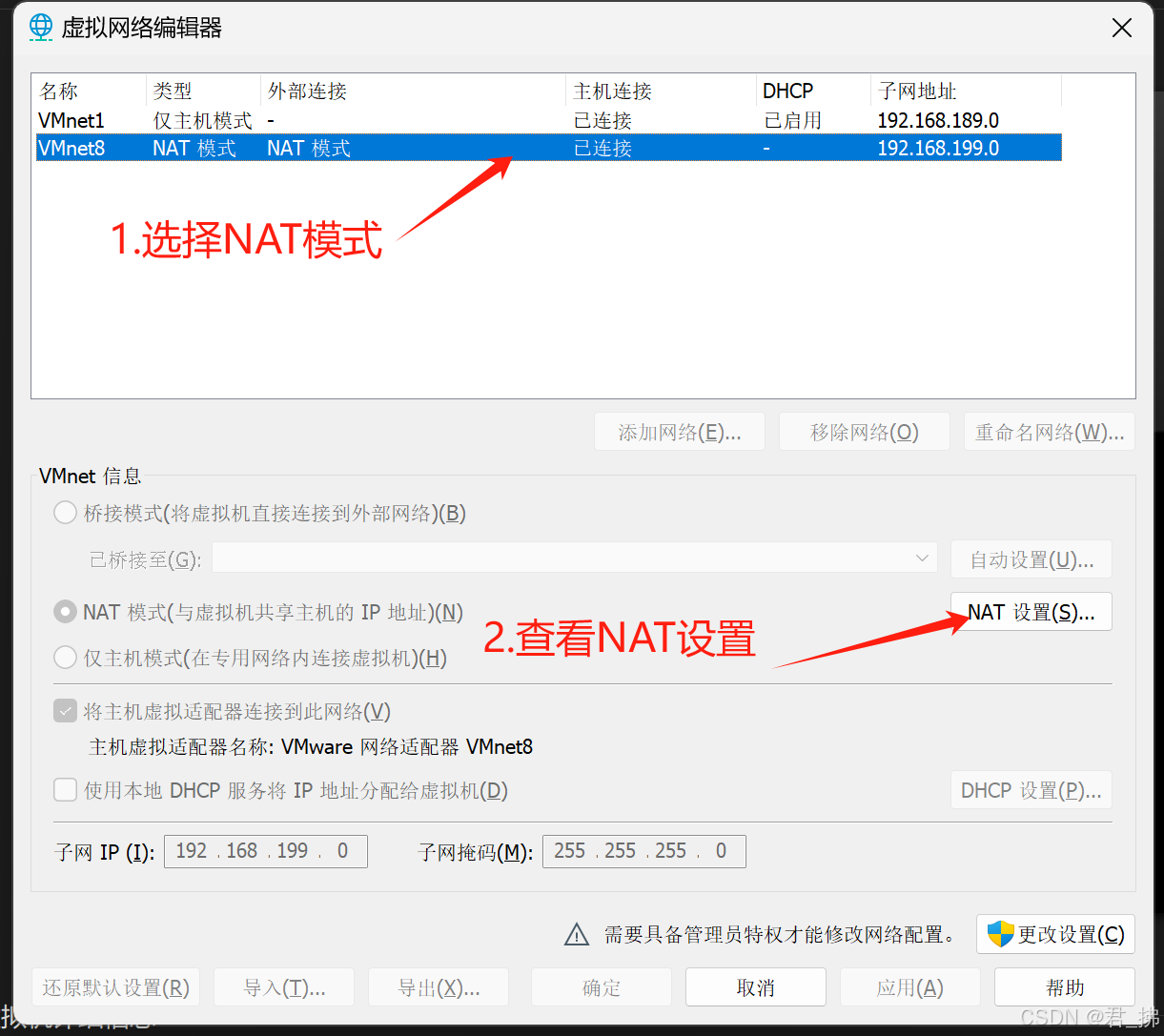
在网络编辑器中选择NAt模式,并且查看NAT设置:
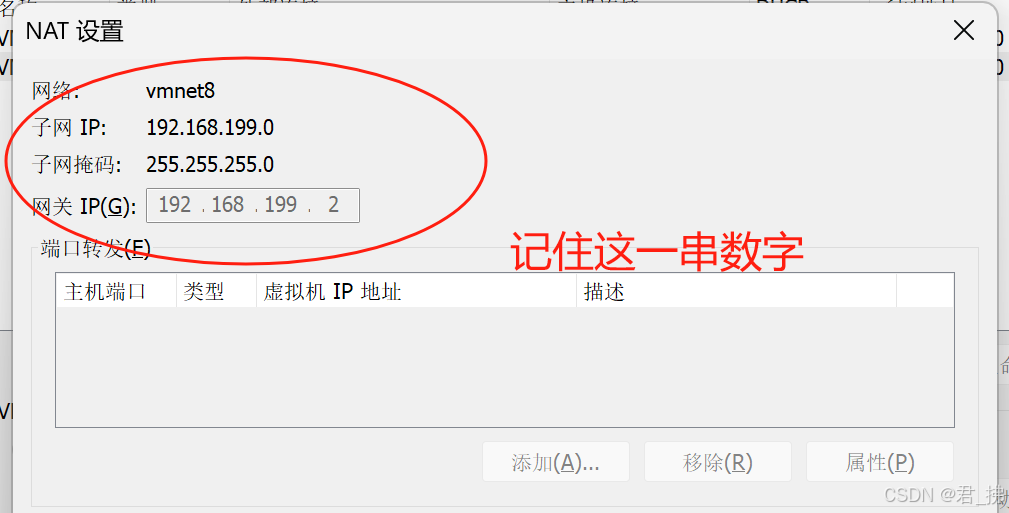
如果你有一定的网络基础,可以自己设置子网以及网关
3.配置三台虚拟机的网络
1. 启动三台虚拟机
2. 查看当前虚拟机的ip地址,命令:ip a:
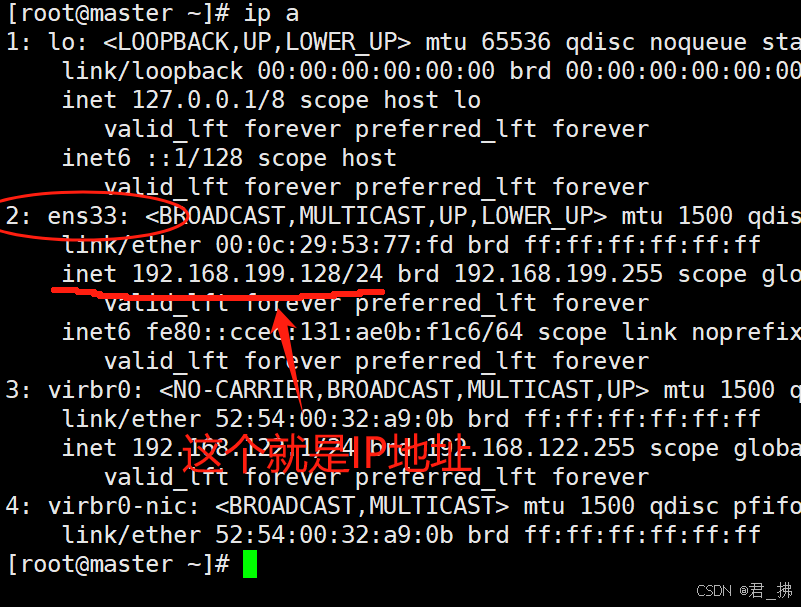
3. 让你的虚拟机IP跟子网保持在同网段:
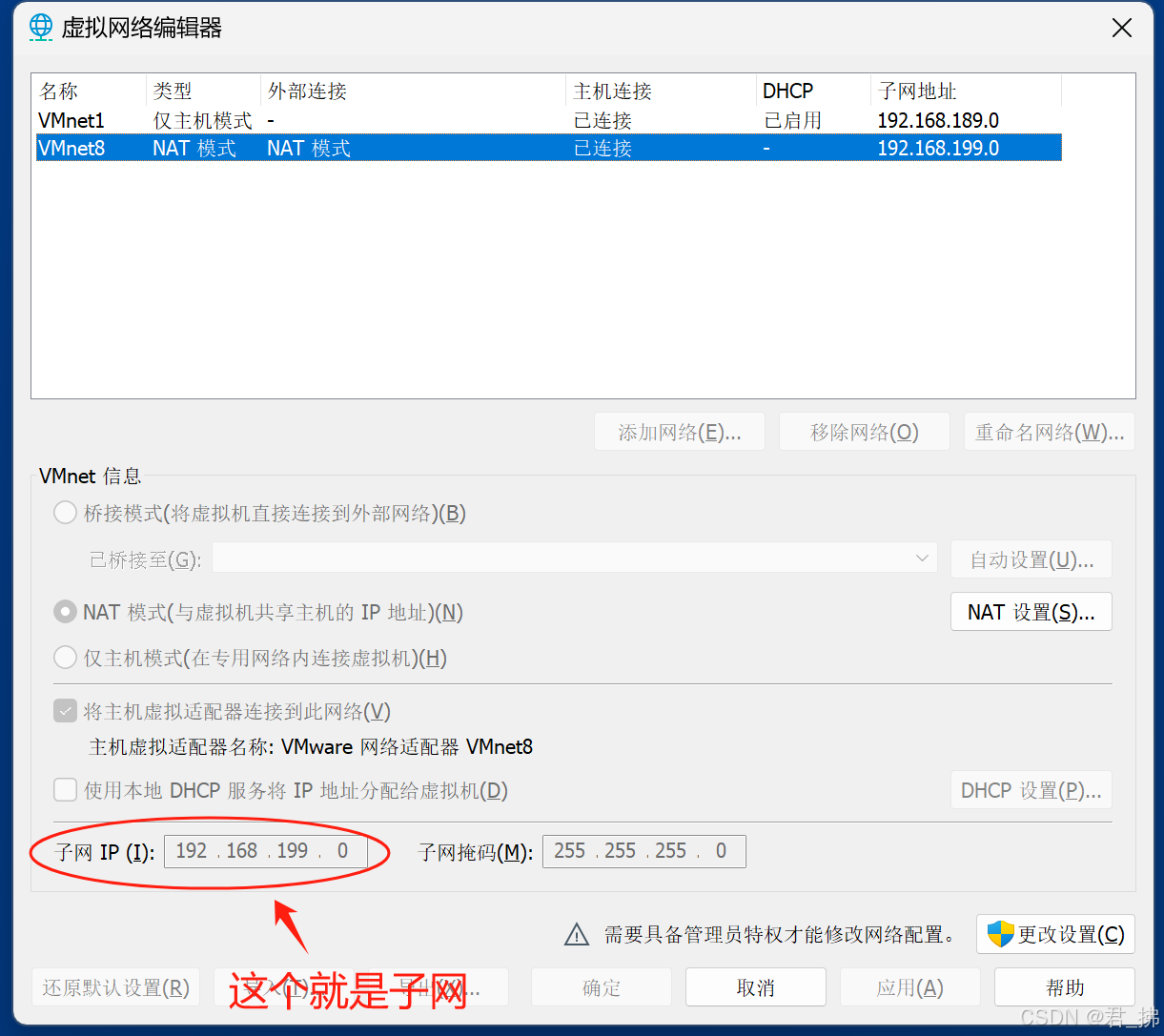
我的虚拟网络编辑器的子网是192.168.199.0,因此我要给我的虚拟机设置IP地址,且IP地址要跟子网保持在同一网段。(如上上图中)我虚拟机的IP地址就是192.168.199.128,只要前三位数字(即192.168.199)跟子网的网段保持一致,最后的一位可任意取值,但不能有重复。(范围是1~255,但2不能取,因为网关占用了)
4.修改三台虚拟机的IP地址:
如果是GUI图像界面,(如图操作)然后 选择有线设置 选项:
接着如图操作:
如果你更改了你的NAT网关,请以你的NAT网关为准,否则,一般设置虚拟机的网关都是子网的前三位和最后一位为2作为虚拟机网关地址:
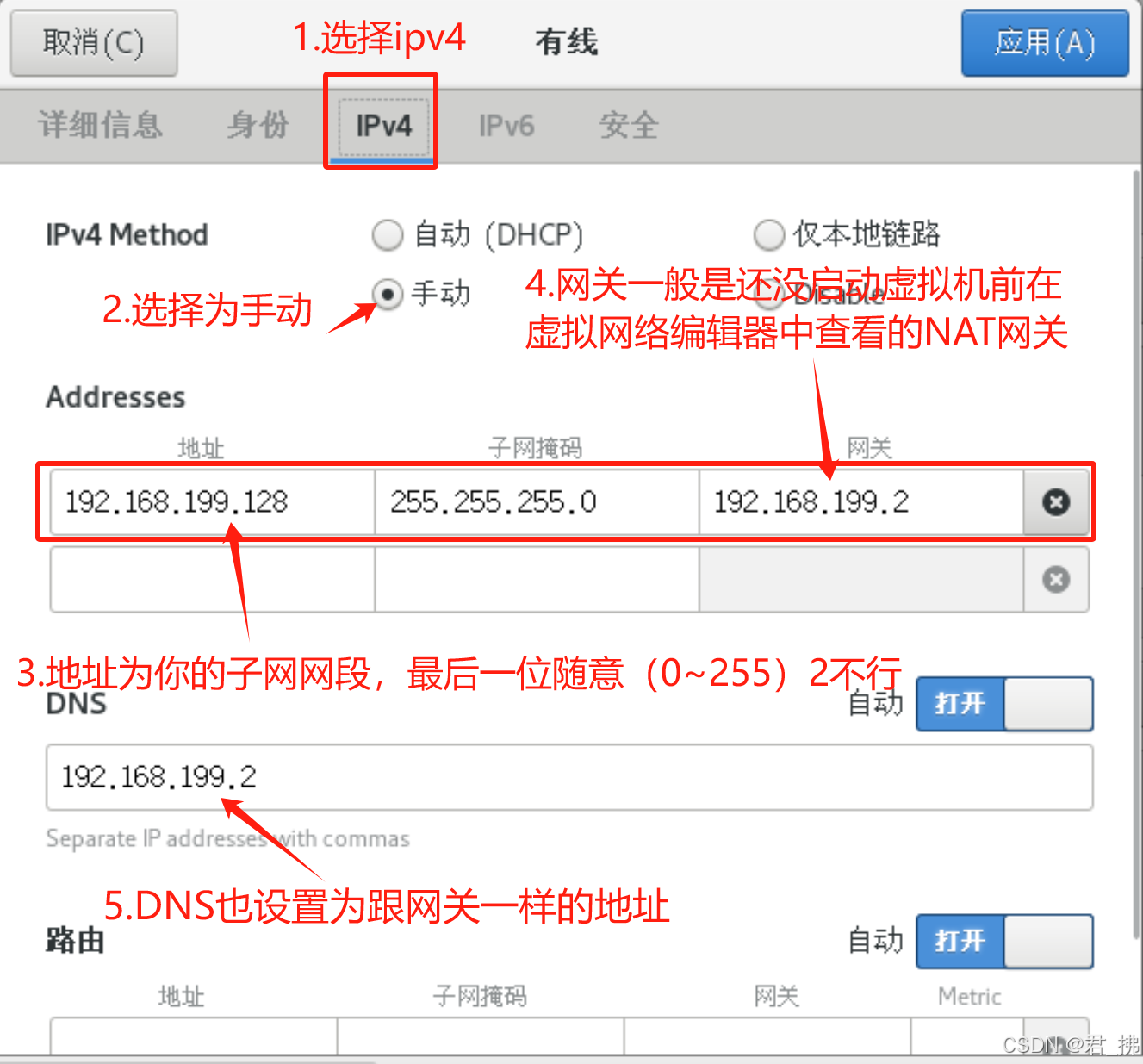
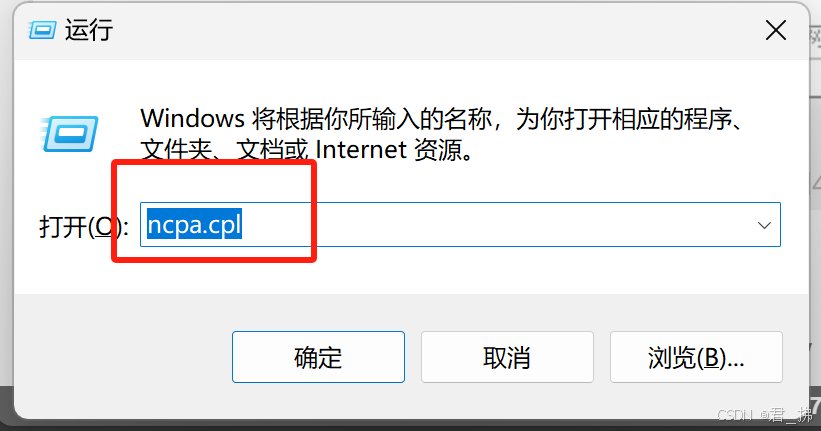
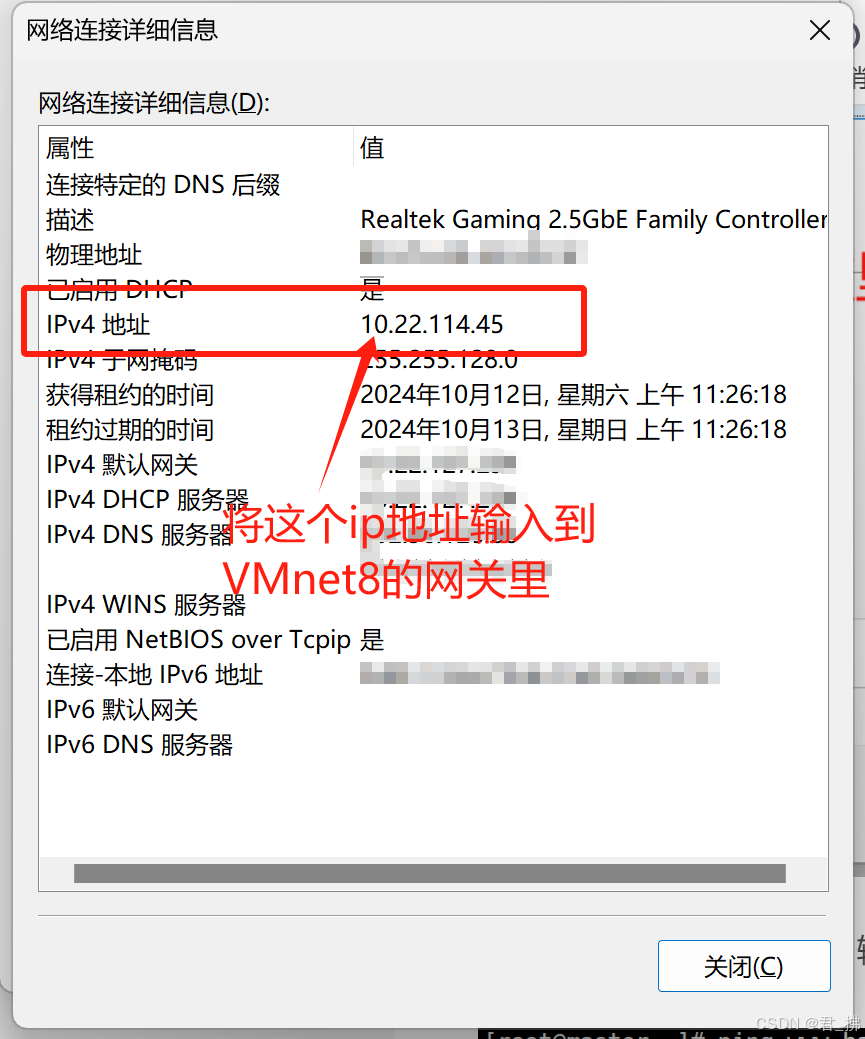
4.按下win+r键,在终端处输入ncpa.cpl:
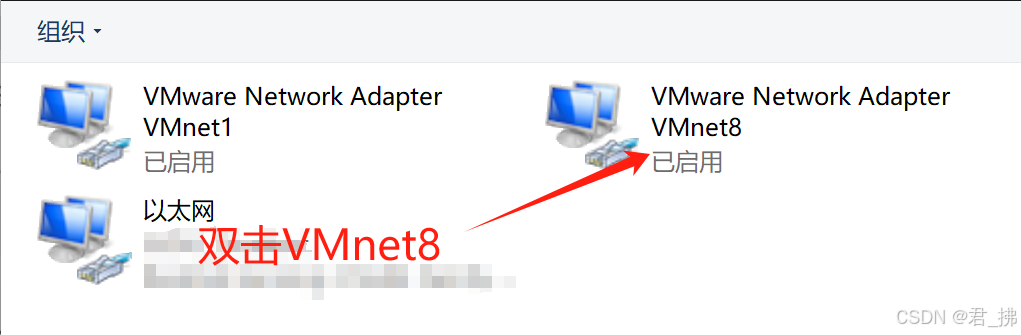
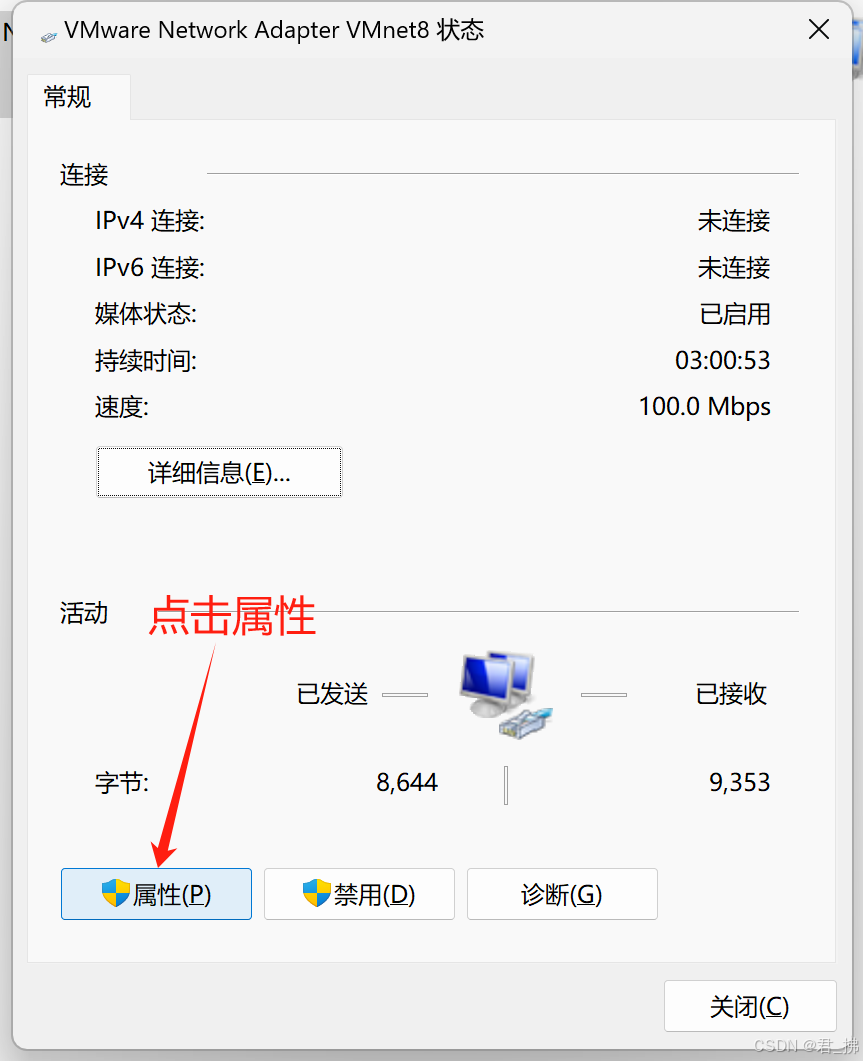
5.打开VMnet8,然后打开属性,找到ipv4:
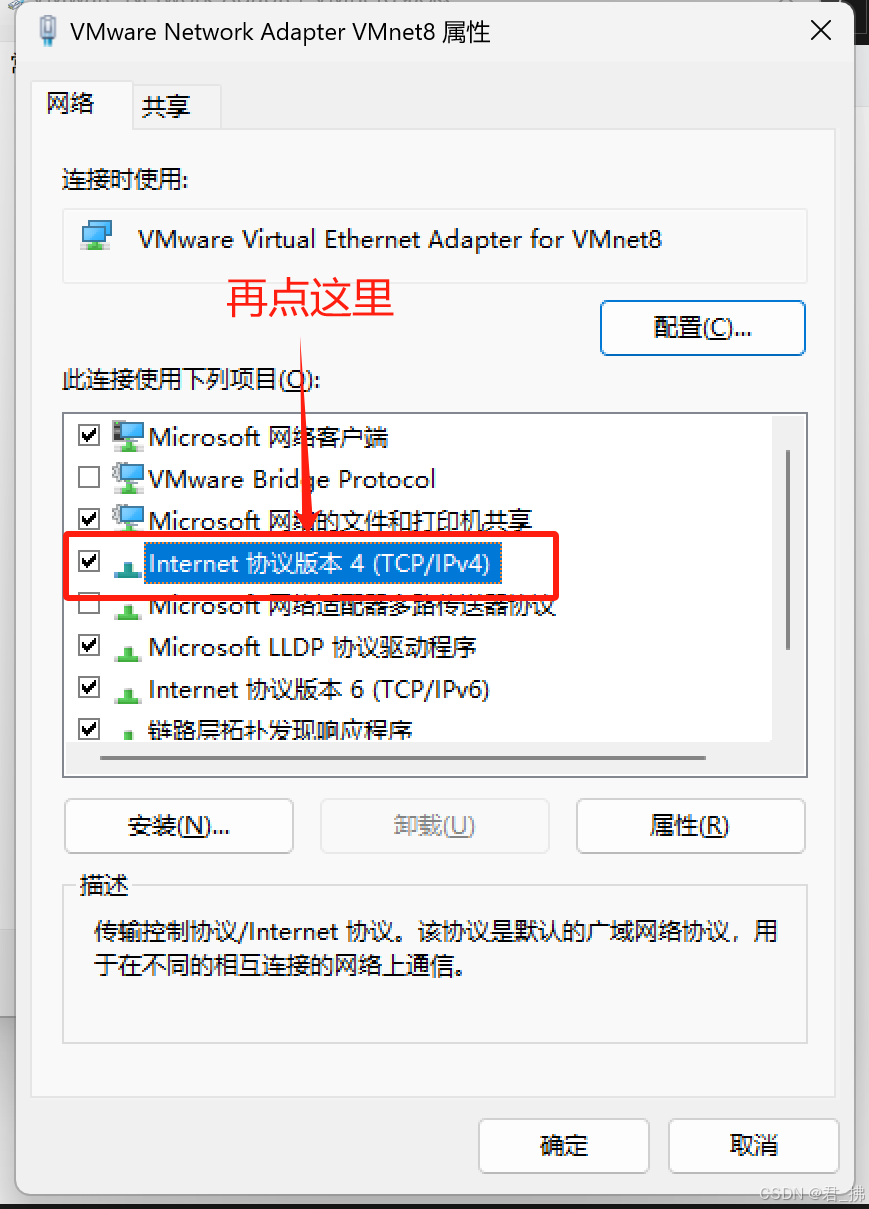
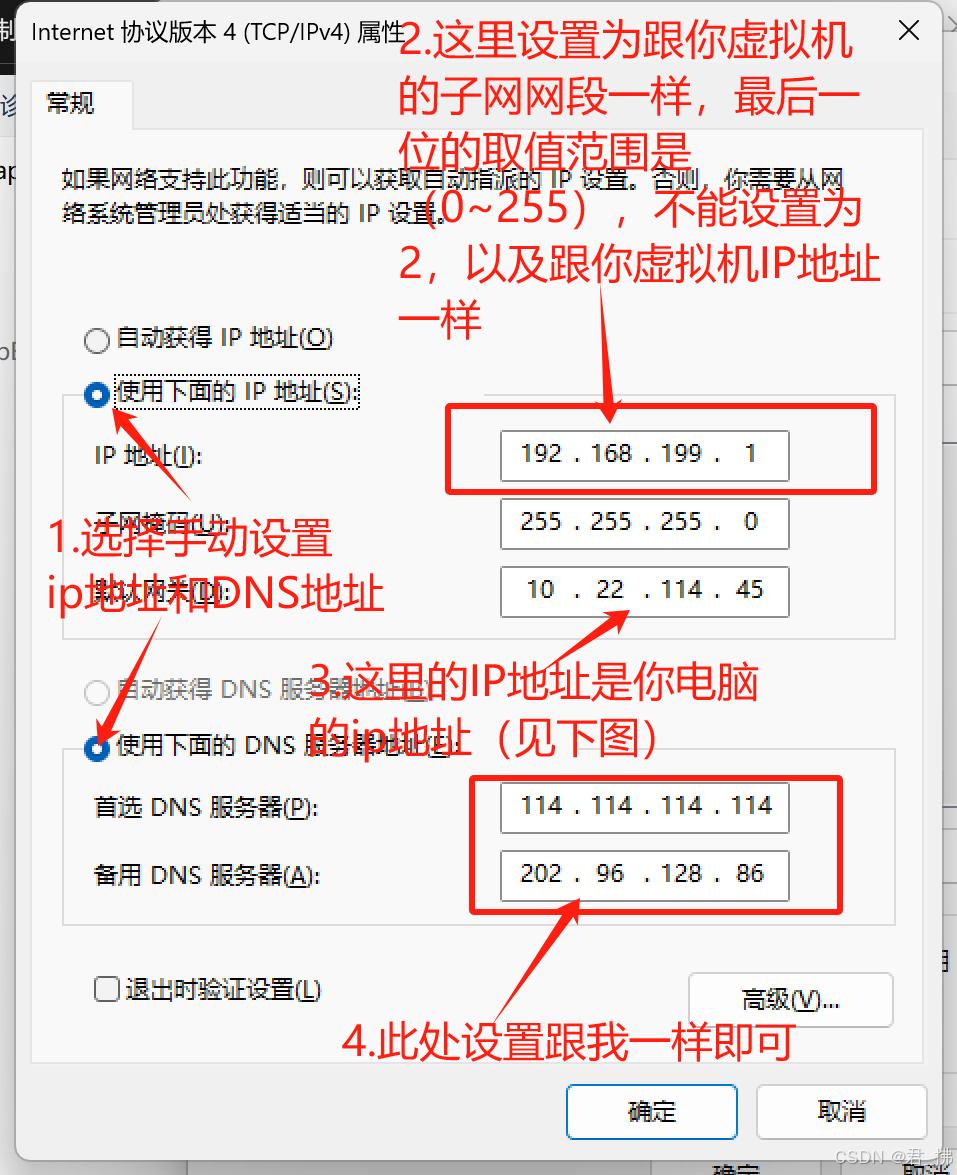
6.查看你电脑的IP地址:
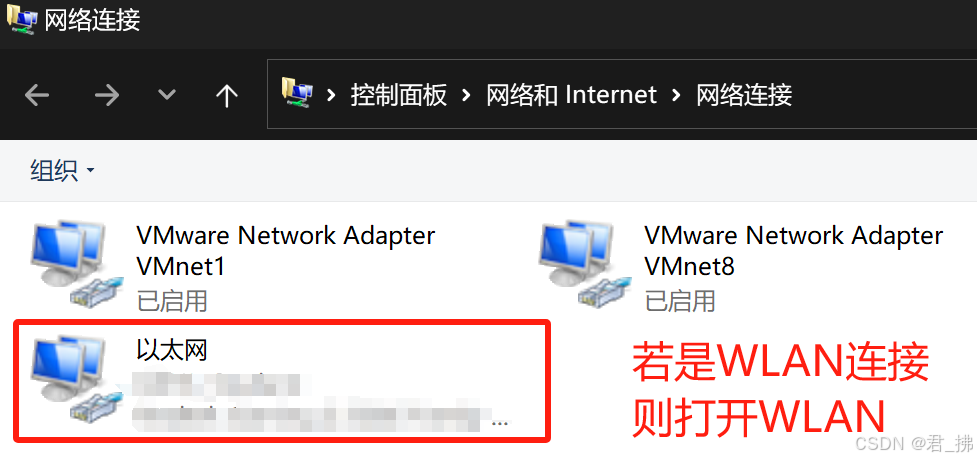
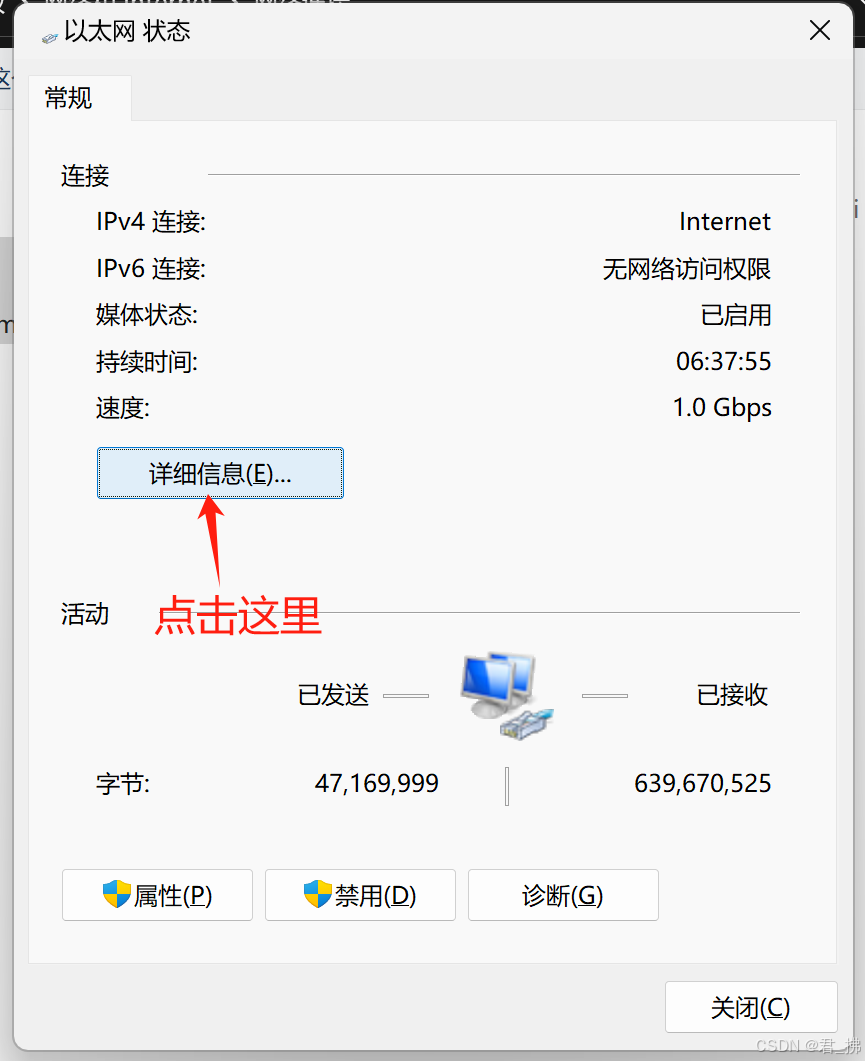
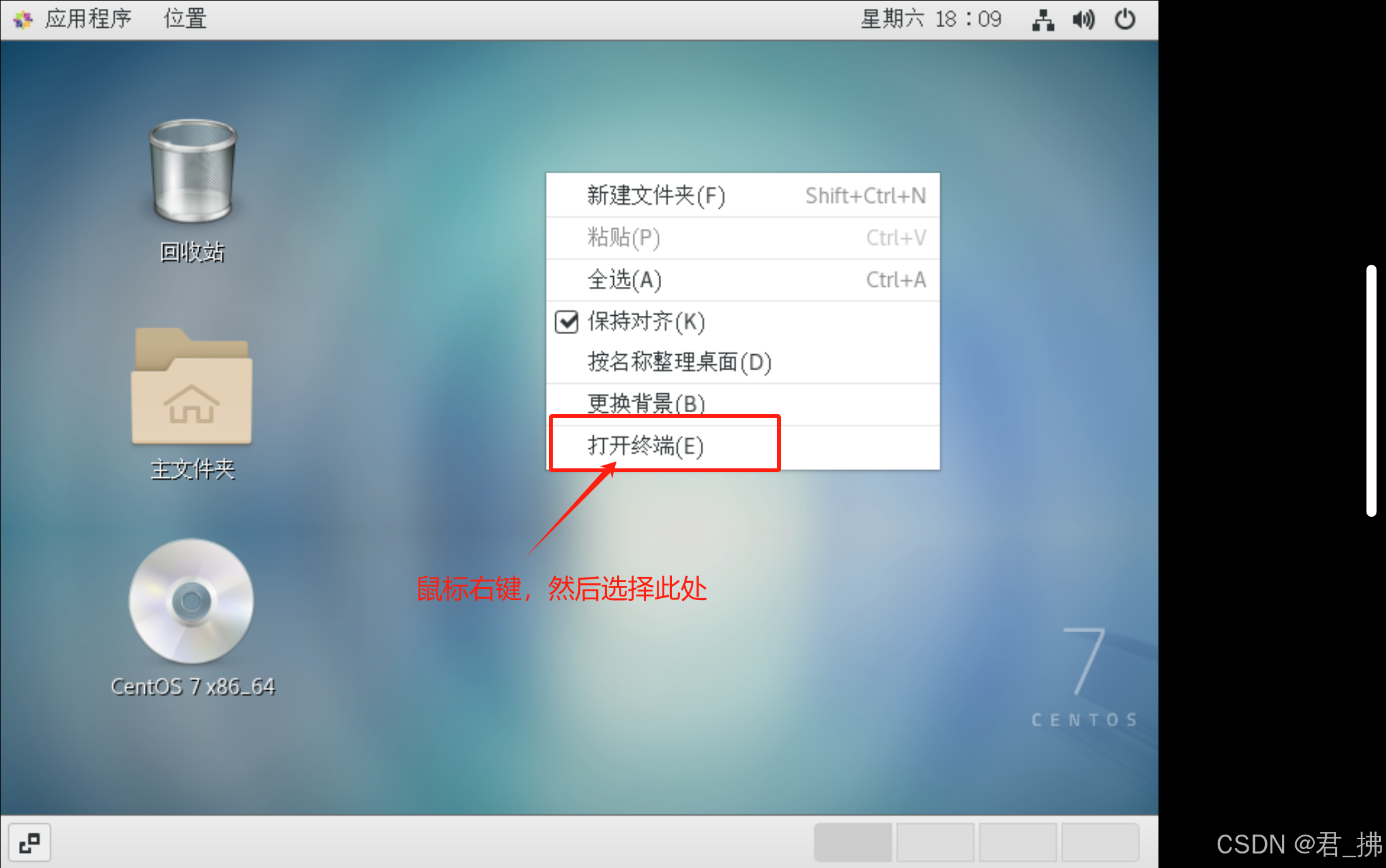
7.按上述步骤配置完后,打开虚拟机的终端,输入命令ping www.baidu.com,若出现下图情况,则代表能正常连接到外网。
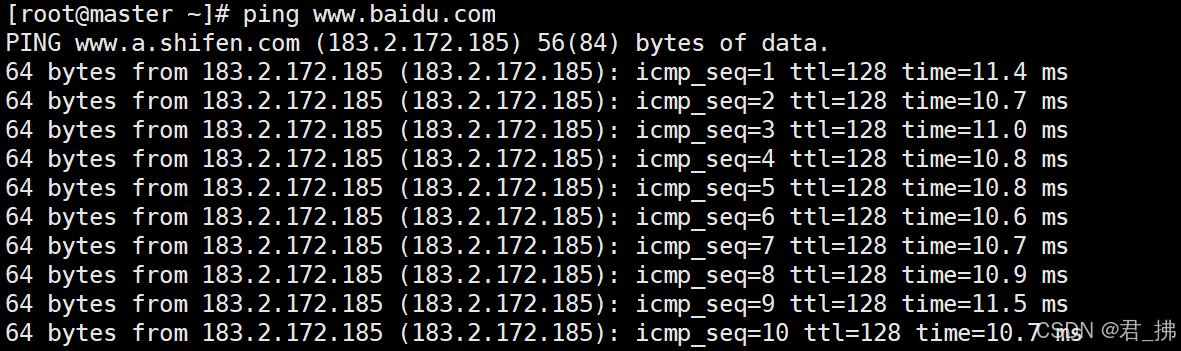
出现下图所示,则代表能ping通外网:
8.然后将另外两台虚拟机Slave1和Slave2也按上述步骤进行配置,使其也能ping通外网!(必需)
【君·拂】PS:若你的虚拟机是最小化安装,没有GUI界面,要修改IP地址和网关地址的话请在虚拟机终端输入该命令:vi /etc/sysconfig/network-scripts/ifcfg-ens33 然后按图中所示,并结合上文进行配置。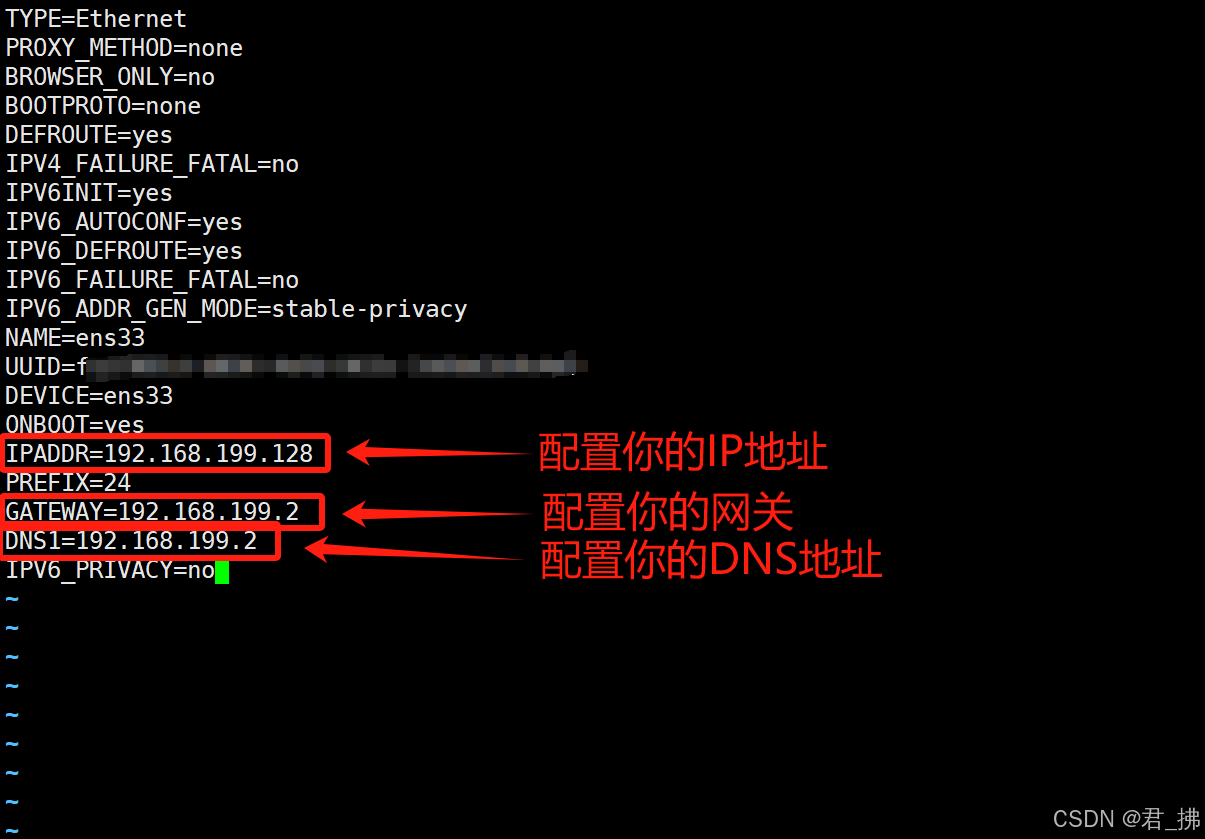
4.进行免密配置
【君·拂】PS:以下操作都在root用户下进行的,且防火墙是关闭的模式下。
请在Master、Slave1、Slave2上都输入以下命令:
#停止firewalld服务并禁用开机启动
systemctl stop firewalld
systemctl disable firewalld
将三台虚拟机都重启:reboot
重启后,查看当前防火墙状态:firewall-cmd --state
1. 修改虚拟机的主机名
在Master上输入命令:hostnamectl set-hostname Master (Master为主节点)
然后输入重启命令:reboot
在Slave1上输入命令:hostnamectl set-hostname Slave1 (Slave1为次节点)
然后输入重启命令:reboot
在Slave2上输入命令:hostnamectl set-hostname Slave2 (Slave2为次节点)
然后输入重启命令:reboot
2. 修改配置/ect/hosts 文件
输入命令:vim /etc/hosts
按图所示进行配置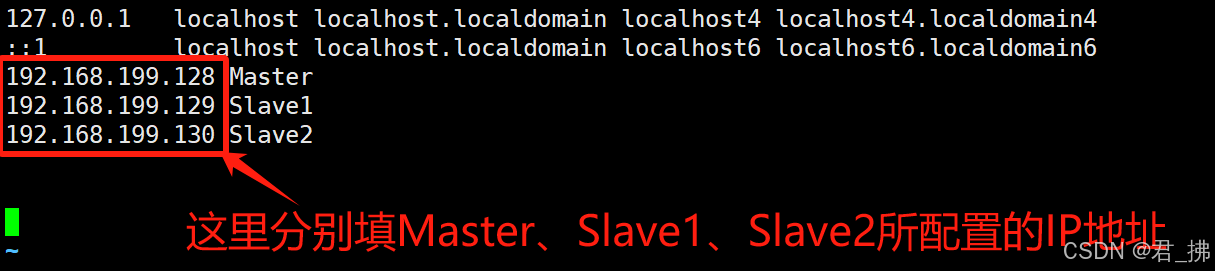
3.配置完后,通过Ping主机名测试网络的连通性,依次执行以下命令:
在Master上:ping Master
在Slave上:ping Slave1
在Slave2上:ping Slave2
4. 使用ssh-keygen命令生成ssh公钥认证所需的公钥和私钥文件:
Master、Slave1、Slave2均需生成公钥和私钥文件。默认生成到家目录下的.ssh/目录下,使用rsa就会生成私钥id_rsa和公钥id_rsa.pub两个文件。
在Master输入命令:ssh-keygen (PS:Slave1和Slave2也需要执行该命令!)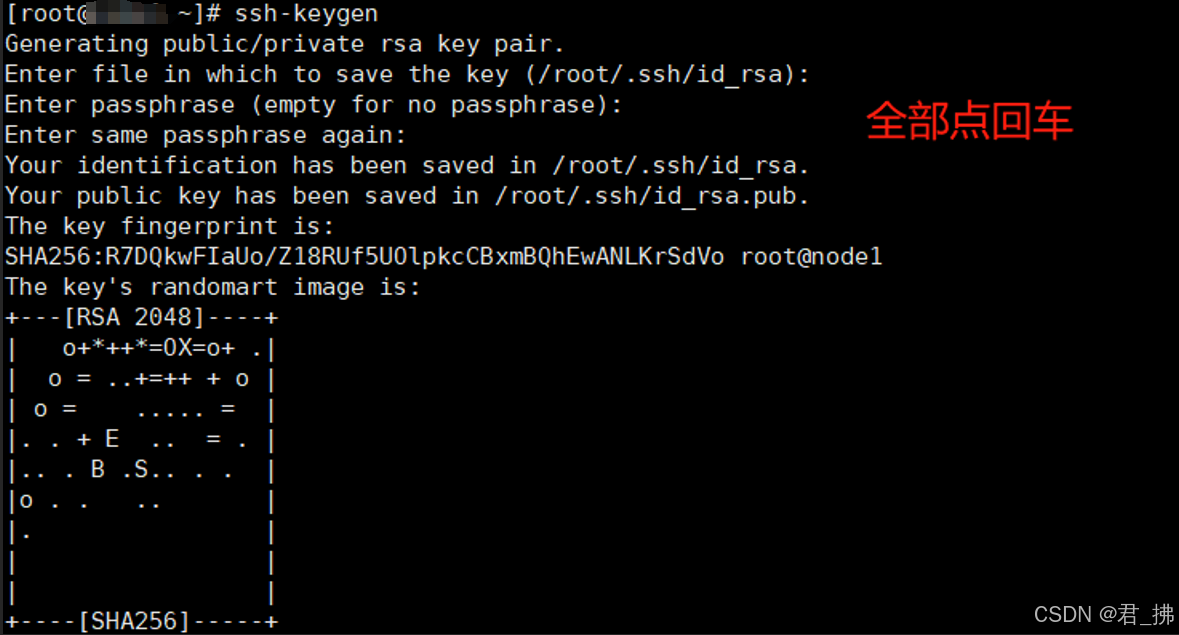
5. 分发Master公钥到Master、Slave1、Slave2上:
在Master上输入该命令:ssh-copy-id Master ssh-copy-id Slave1 ssh-copy-id Slave2 (PS:以上三条命令也要在Slave1、Slave2上执行!)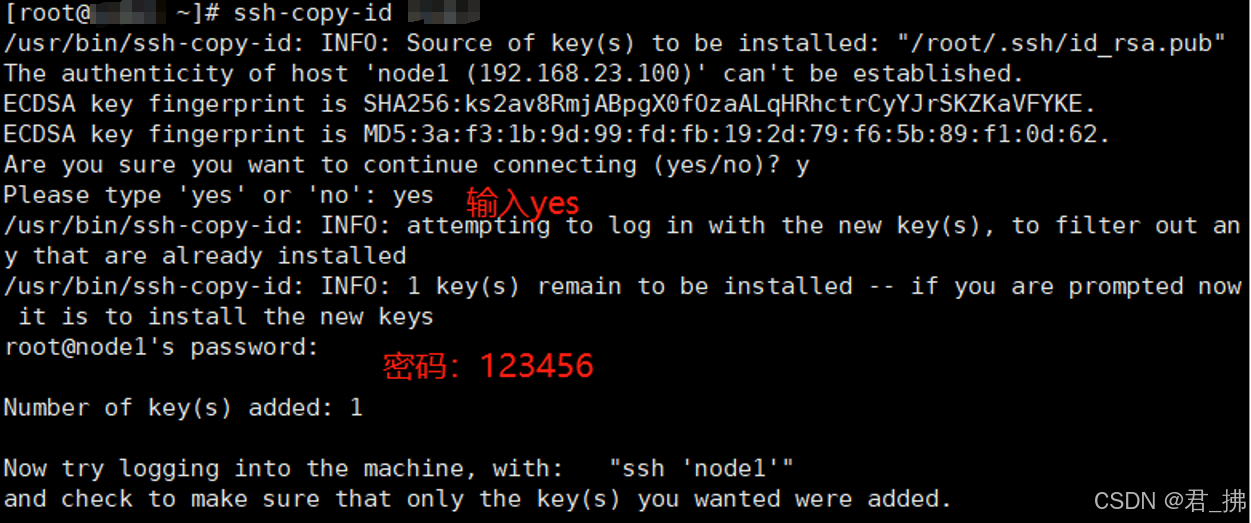
6.测试三台虚拟机之间是否能使用ssh进行免密登入:
在Master上输入:ssh Slave1
在Slave1上输入:ssh Slave2
在Slave1上输入:exit退出Slave2登入
然后再在Slave1上输入:ssh Master
在Slave2上输入:ssh Master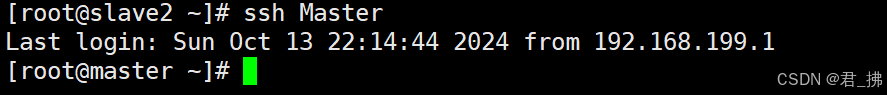
在Slave2上输入:exit退出Master登入
然后再在Slave2上输入:ssh Slave1
至此,三台虚拟机之间的免密配置登入完成!
四、安装JAVA环境:
1. 在三台虚拟机上创建文件夹:
在Master、Slave1、Slave2上分别输入:mkdir -p /opt/servers mkdir -p /opt/softwears
2. 将JDK安装包和Hadoop包传入虚拟机:
打开xftp,从xftp上传输到Master的/opt/softwears路径下,操作如图所示:
(【君·拂】PS:你也可以传入到你自己指定的目录下)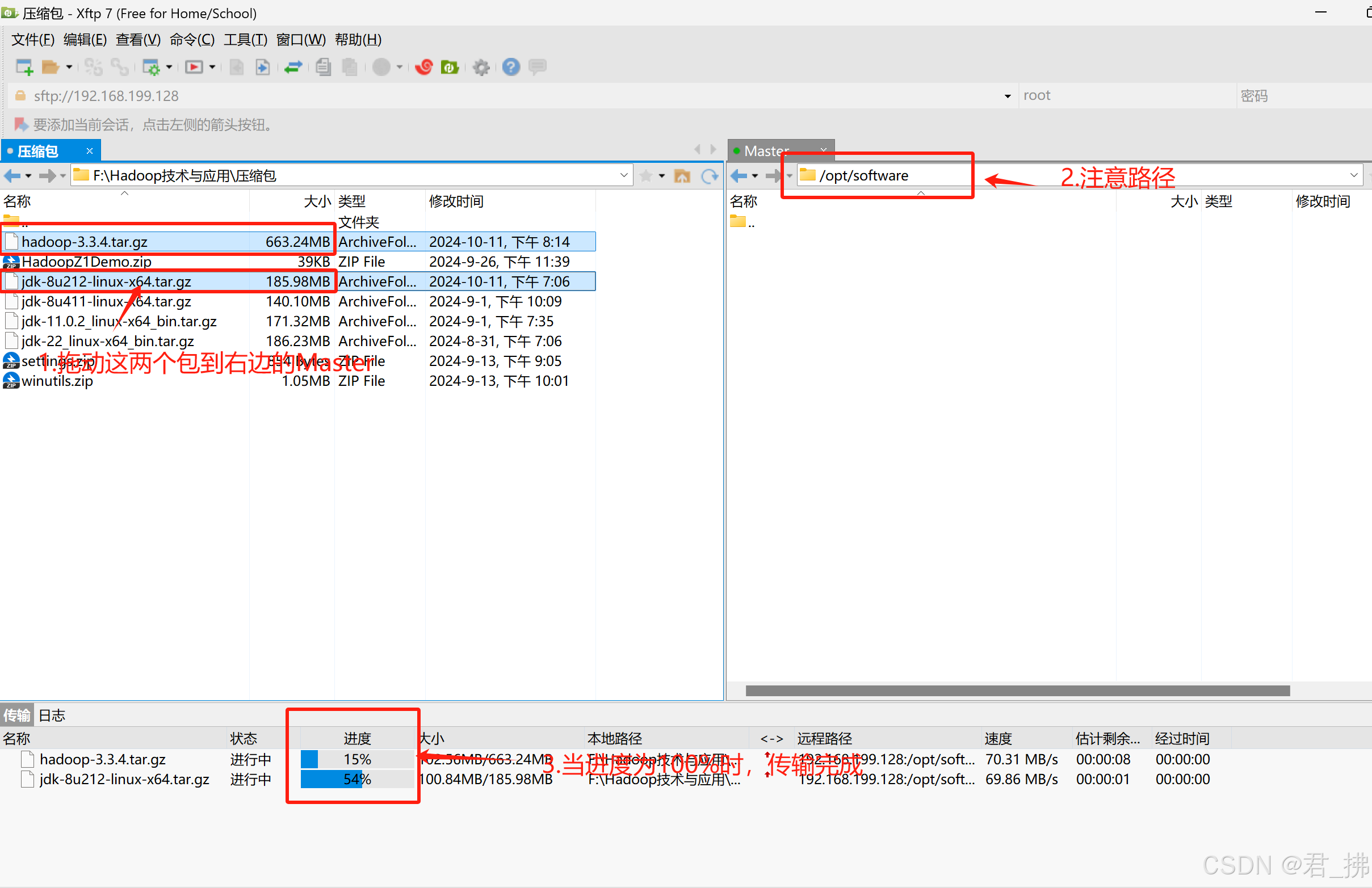
3. 查看安装包
在Master上输入命令:cd /opt/softwares/ 和ll
再输入命令:du -sh jdk-8u212-linux-x64.tar.gz 查看上传的安装包大小与原安装包大小是否一致,避免安装包在上传中有损坏。(最好也查看一下Hadoop的包大小是否一致)
4. 解压JDK包:
在Master上输入命令:tar -zxvf jdk-8u141-linux-x64.tar.gz -C ../servers/
解压完后,再输入命令:cd ../servers和ll 查看一下
5. 添加环境变量
将Java执行路径加入到环境变量。编辑/etc/profile文件,在文件最后添加Java的路径。
在Master上输入命令:vim /etc/profile
输入以下内容后,按ESC键,再输入“:wq”保存退出:
export JAVA_HOME=/opt/servers/jdk1.8.0_212
export PATH=:$JAVA_HOME/bin:$PATH
如图: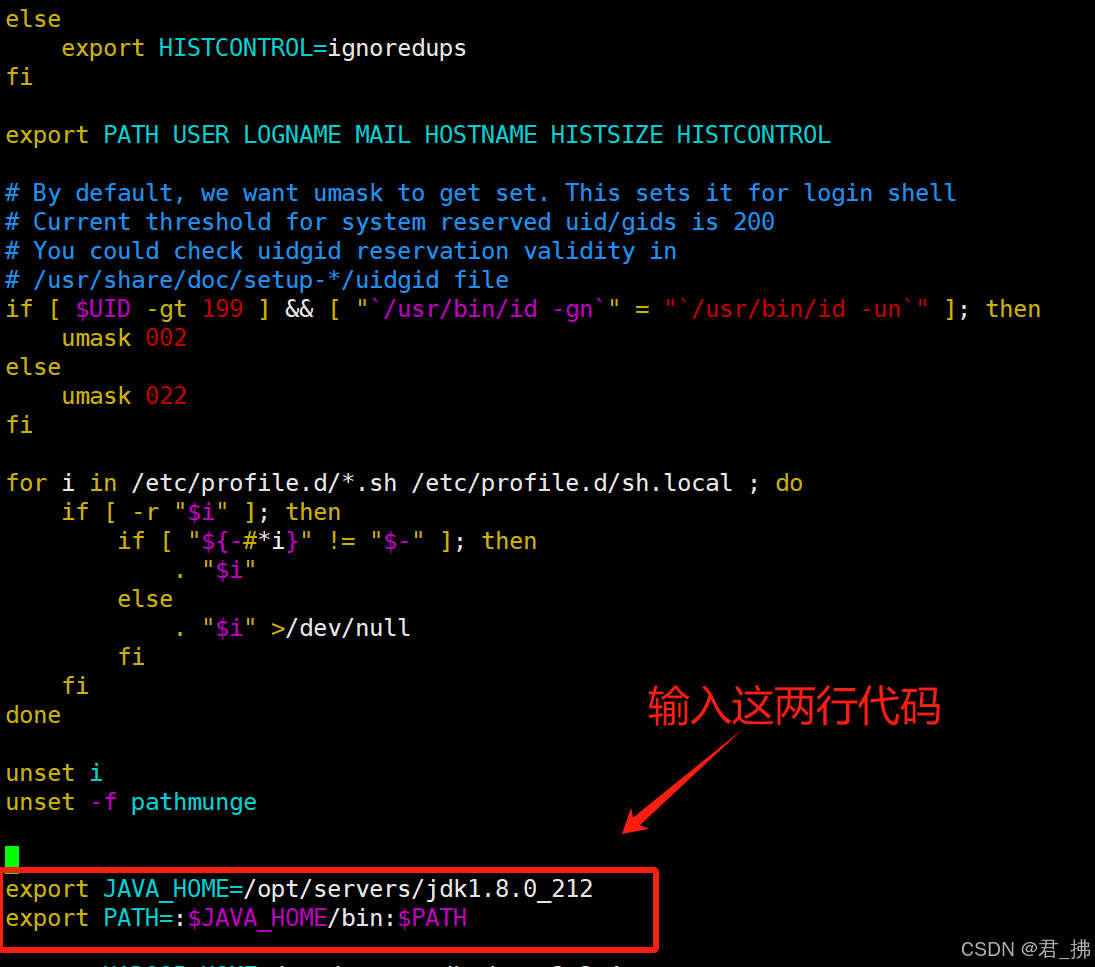
6. 使环境变量生效:
在Master上输入命令:source /etc/profile
7. 测试是否生效:
在Master上输入命令:java -version (如图显示则为安装成功)
8.分发Java环境及环境变量文件:
分发Java环境文件:
1.在Master上输入命令:cd /opt/servers 然后再分别输入scp -r jdk1.8.0_212/ -C root@Slave1:/opt/servers 和 scp -r jdk1.8.0_212 -C root@Slave2:/opt/servers
分发环境变量文件:
2.在Master上分别输入命令:scp -r /etc/profile root@Slave1:/etc/profile和scp -r /etc/profile root@Slave2:/etc/profile
9.使Slave1和Slave2环境变量生效:
在Slave1上分别输入命令:source /etc/profile和java -version
在Slave2上分别输入命令:source /etc/profile和java -version
至此,Master、Slave1和Slave2的Java环境安装完毕!
五、部署Hadoop分布式集群:
1.解压hadoop安装包:
- 在Master上输入命令:
cd /opt/softwares和tar -zxvf hadoop-3.3.4.tar.gz -C ../servers/
解压完后到servers目录下查看:
- 查看一下Hadoop文件大小:
在Master上输入命令:du -sh hadoop-3.3.4/(若包解压后大小不是1.4G,则包出现了损坏)
- 进入hadoop-3.3.4目录里,查看hadoop目录结构:
在Master上输入命令:cd hadoop-3.3.4/和ll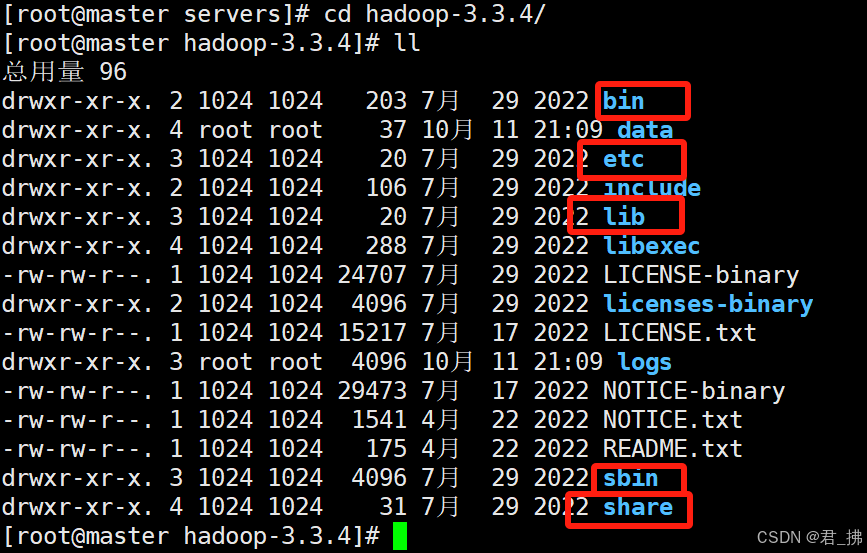
目录 说明:
bin --> 放置Hadoop的功能操作命令
etc --> 放置Hadoop的配置文件
lib --> 放置本地库文件
sbin --> 放置Hadoop集群进程管理的操作命令
share --> 放置开发所需要的jar包及用户帮助文档
2.修改Hadoop配置文件:
前提:Hadoop配置文件放置在hadoop-3.3.4/etc/hadoop目录下,共有6个配置文件需要修改:hadoop-env.sh、core-site.xml 、hdfs-site.xml、mapred-site.xml、yarn-site.xml和workers。
1. 切换到hadoop-3.3.4/etc/hadoop目录,查看相关配置文件:
在Master上输入命令:cd hadoop-3.3.4/etc/hadoop/ 和 ll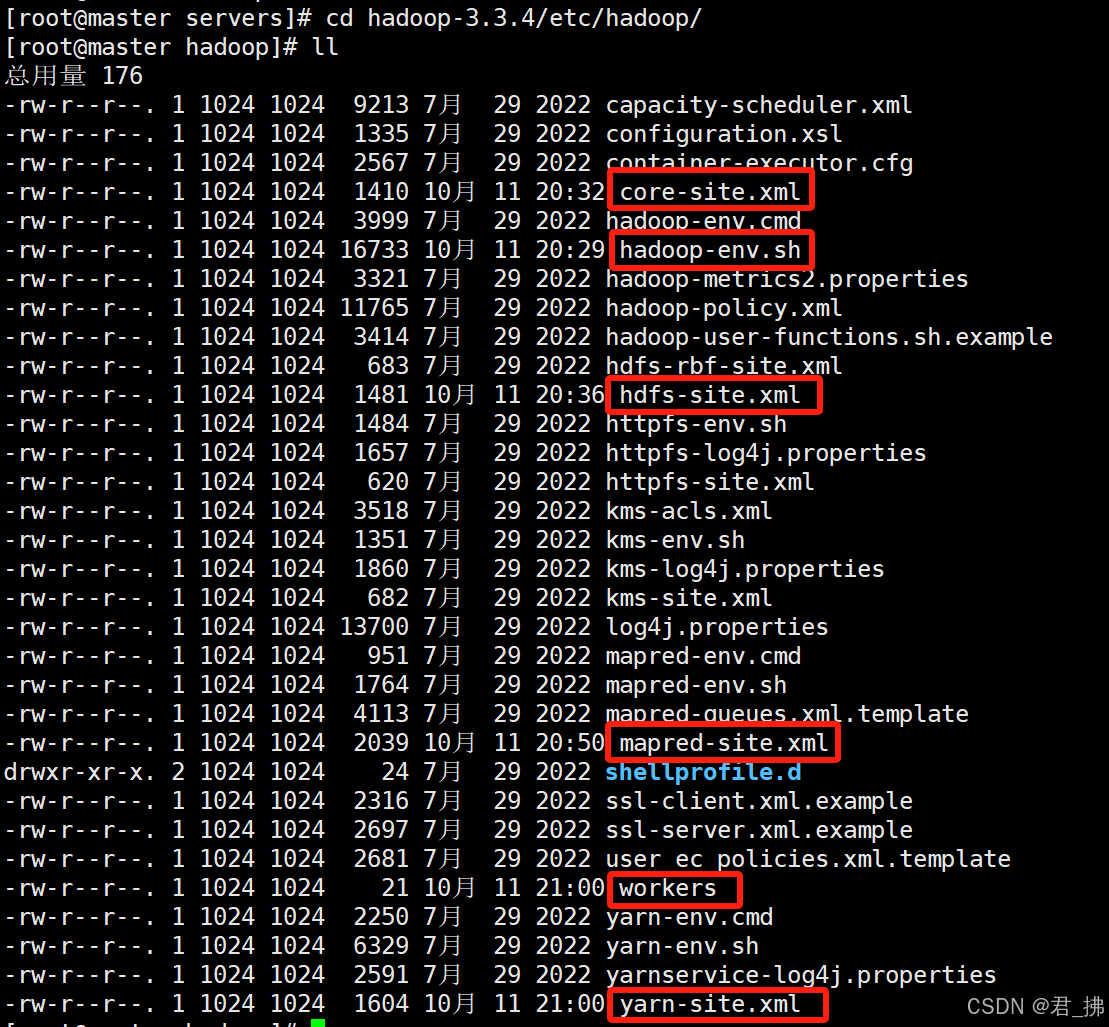
2. 修改hadoop-env.sh文件:
在Master上输入命令:vim hadoop-env.sh
然后输入以下代码:
export JAVA_HOME=/opt/servers/jdk1.8.0_212
export PATH=:$JAVA_HOME/bin:$PATH
编辑完成后,按ESC,输入“:wq”保存退出。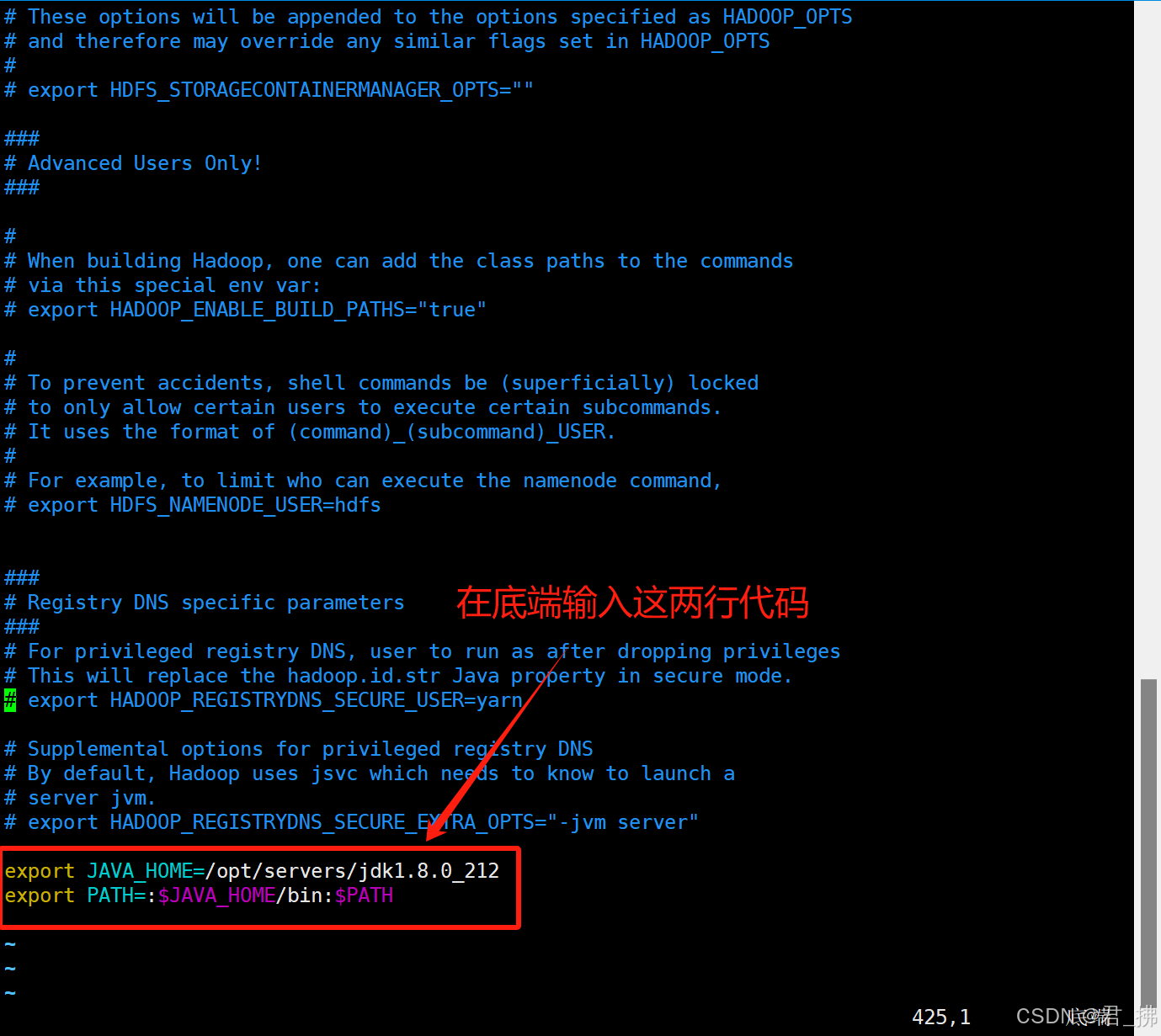
3. 修改core-site.xml文件:
在Master上输入命令:vim core-site.xml
然后输入以下代码:
<configuration>
<!-- 指定 HDFS默认使用的文件系统,指定HDFS中NameNode的入口 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/servers/hadoop-3.3.4/data/</value>
</property>
<!--设置文件删除后,回收站彻底删除的时间,默认时间单位为:分钟-->
<property>
<name>fs.trash.interval</name>
<value>0</value>
</property>
</configuration>
如图: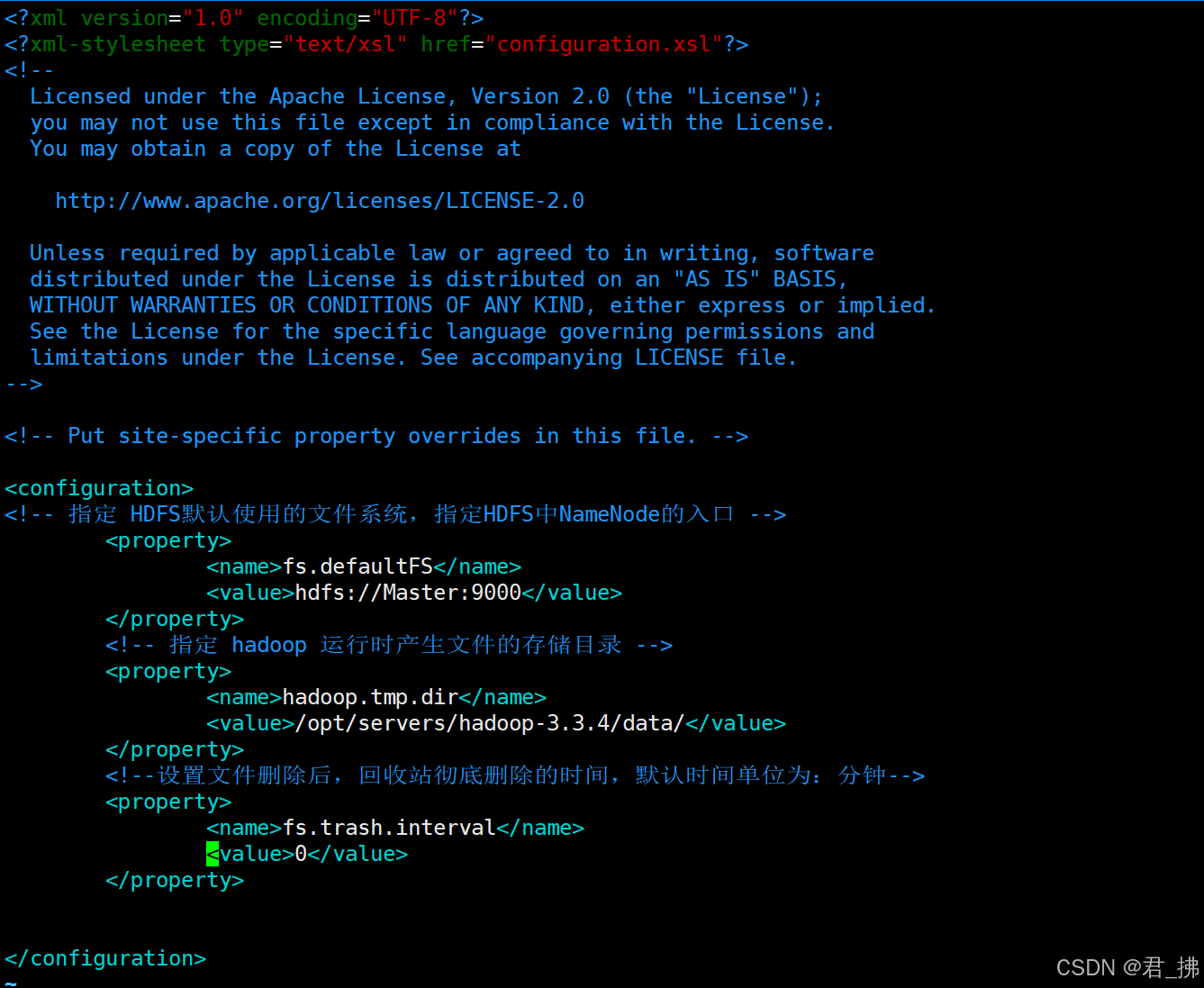
编辑完成后,按ESC,输入“:wq”保存退出。
4. 修改hdfs-site.xml文件:
在Master上输入命令:vim hdfs-site.xml
然后输入以下代码:
<configuration>
<!-- 设置Namenode的http访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>Master:50070</value>
</property>
<!-- 设置secondarynamenode的http访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Slave1:50090</value>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--关闭权限校验,默认为true-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
如图: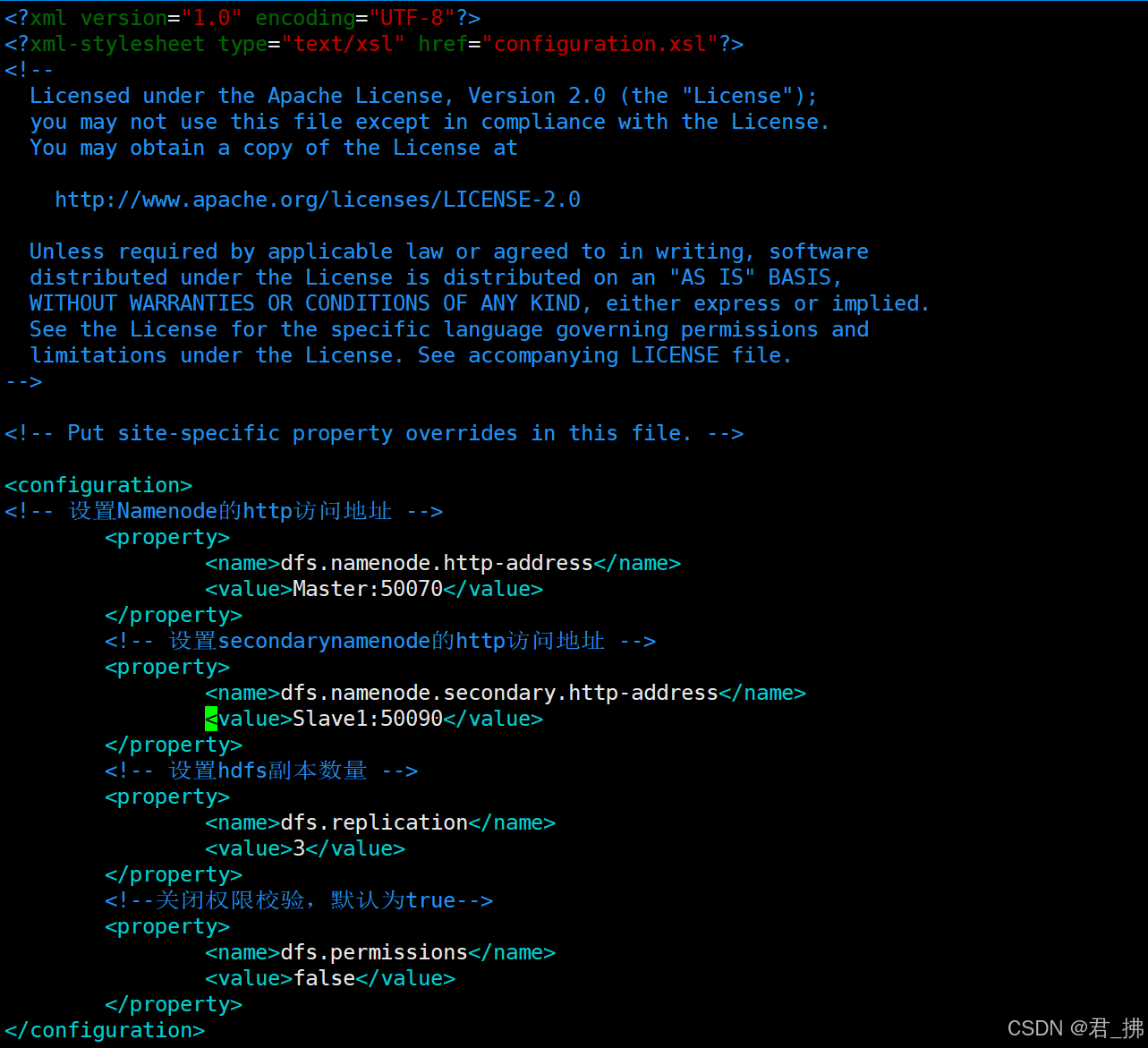
编辑完成后,按ESC,输入“:wq”保存退出。
5. 修改mapred-site.xml文件:
在Master上输入命令:vim mapred-site.xml
然后输入以下代码:
<configuration>
<!--设置MapReduce运行在yarn上,默认为local,可选参数classic -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--是否开启Uber运行模式-->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 设置历史服务器地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
<!--设置Hadoop包路径【如果出现找不到或无法加载主类org.apache.hadoop.mapreduce.......】-->
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/servers/hadoop-3.3.4/etc/hadoop:/opt/servers/hadoop-3.3.4/share/hadoop/common/lib/*:/opt/servers/hadoop-3.3.4/share/hadoop/common/*:/opt/servers/hadoop-3.3.4/share/hadoop/hdfs:/opt/servers/hadoop-3.3.4/share/hadoop/hdfs/lib/*:/opt/servers/hadoop-3.3.4/share/hadoop/hdfs/*:/opt/servers/hadoop-3.3.4/share/hadoop/mapreduce/*:/opt/servers/hadoop-3.3.4/share/hadoop/yarn:/opt/servers/hadoop-3.3.4/share/hadoop/yarn/lib/*:/opt/servers/hadoop-3.3.4/share/hadoop/yarn/*</value>
</property>
</configuration>
【君·拂】PS:<property> <name>mapreduce.application.classpath</name> <value>/opt/servers/hadoop-3.3.4/etc/hadoop:/opt/servers/hadoop-3.3.4/share/hadoop/common/lib/*:/opt/servers/hadoop-3.3.4/share/hadoop/common/*:/opt/servers/hadoop-3.3.4/share/hadoop/hdfs:/opt/servers/hadoop-3.3.4/share/hadoop/hdfs/lib/*:/opt/servers/hadoop-3.3.4/share/hadoop/hdfs/*:/opt/servers/hadoop-3.3.4/share/hadoop/mapreduce/*:/opt/servers/hadoop-3.3.4/share/hadoop/yarn:/opt/servers/hadoop-3.3.4/share/hadoop/yarn/lib/*:/opt/servers/hadoop-3.3.4/share/hadoop/yarn/*</value> </property>
这段代码是出现了【如果出现找不到或无法加载主类org.apache.hadoop.mapreduce…】这个错误时才加上去的。如果没有出现这个错误可以不用。具体路径是请执行该代码:hadoop classpath
然后将那一长串的代码复制到<value> ......</value>中。
如图: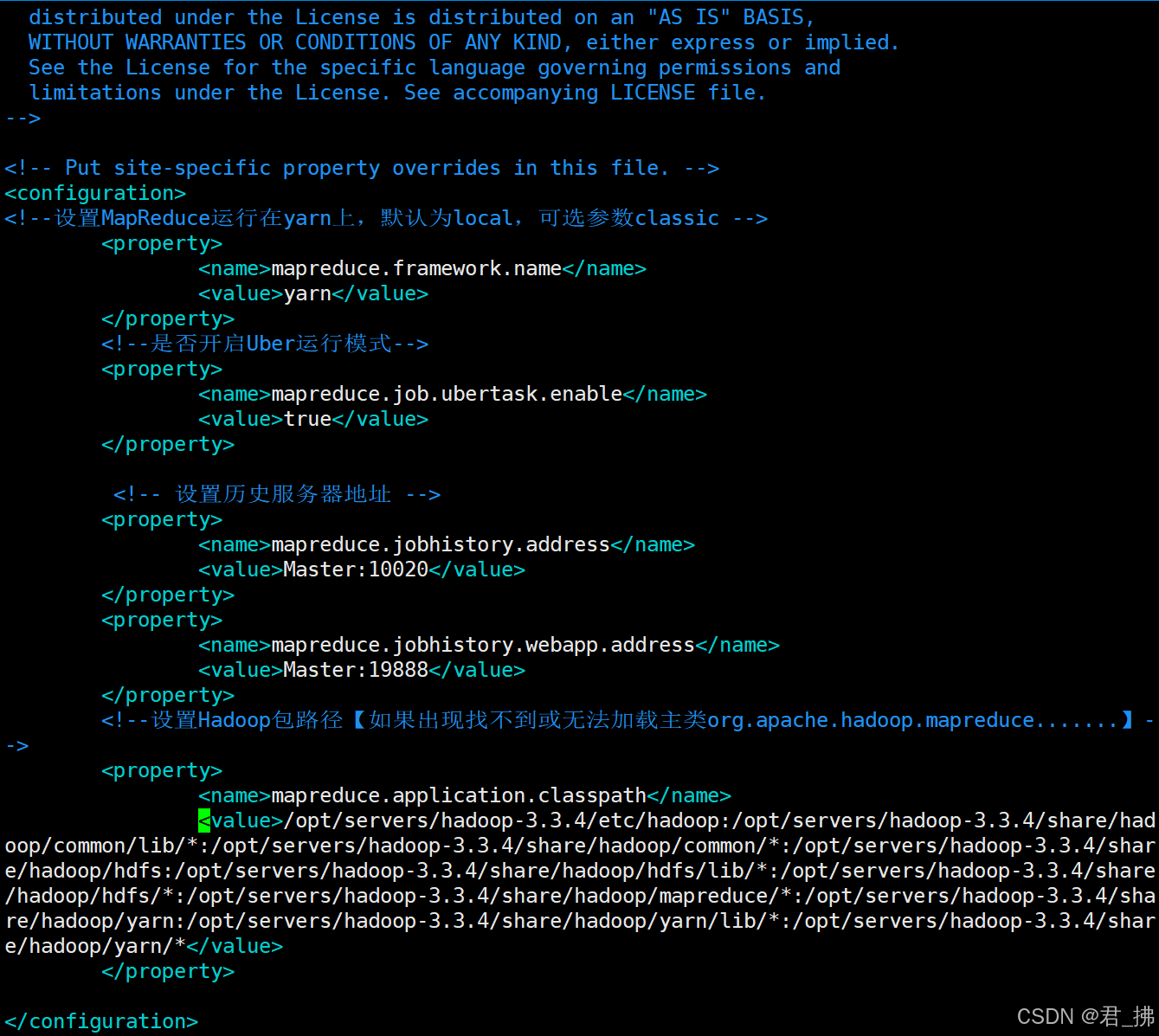
编辑完成后,按ESC,输入“:wq”保存退出。
6. 修改yarn-site.xml文件:
在Master上输入命令:vim yarn-site.xml
然后输入以下代码:
<configuration>
<!-- Site specific YARN configuration properties -->
<!--设置resourcemanager的主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<!--设置客户端的主机名及端口号-->
<property>
<name>yarn.resourcemanager.address</name>
<value>Master:8032</value>
</property>
<!--分配给容器的物理内存量,单位MB,设置为-1则自动分配,默认是你虚拟机设置的内存:MB。>我的主节点物理内存是6G,则分配3/4的样子,这样的性能比较合理-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4608</value>
</property>
<!-- 设置nodemanager的辅助服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
如图: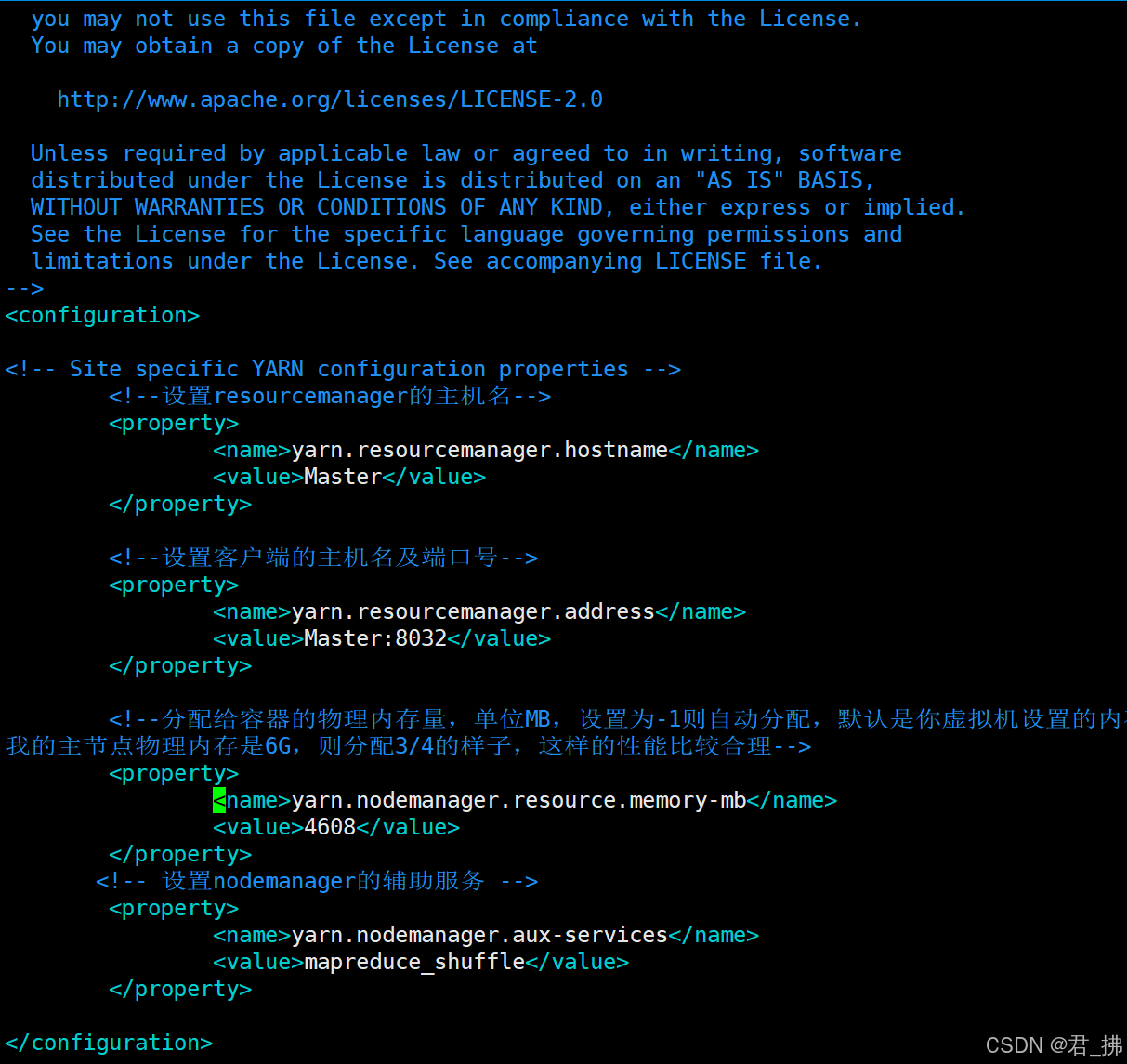
编辑完成后,按ESC,输入“:wq”保存退出。
- 修改workers文件:
在Master上输入命令:vim workers
然后输入以下代码:Master Slave1 Slave2
编辑完成后,按ESC,输入“:wq”保存退出。
3.配置Hadoop的bin和sbin的环境变量:
1.配置环境变量:
在Master上输入命令:vim /etc/profile
然后输入以下代码:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_HOME=/opt/servers/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
2.使环境变量生效:
在Master上输入命令:source /etc/profile
4.分发Hadoop软件包和环境变量文件:
1.将配置好的Hadoop软件包分发到Slave1和Slave2。
在Master上分别输入命令:
cd /opt/servers/
scp -r /opt/servers/hadoop-3.3.4/ -C root@Slave1:/opt/servers/
scp -r /opt/servers/hadoop-3.3.4/ -C root@Slave2:/opt/servers/
2.分发/etc/profile文件.
在Master上分别输入命令:
scp -r /etc/profile root@Slave1:/etc/profile
scp -r /etc/profile root@Slave2:/etc/profile
3.在Slave1和Slave2上使环境变量生效。
在Slave1上输入命令:source /etc/profile
在Slave2上输入命令:source /etc/profile
5.启动Hadoop集群:
-
初始化Hadoop集群:
在Master上输入命令:hdfs namenode -format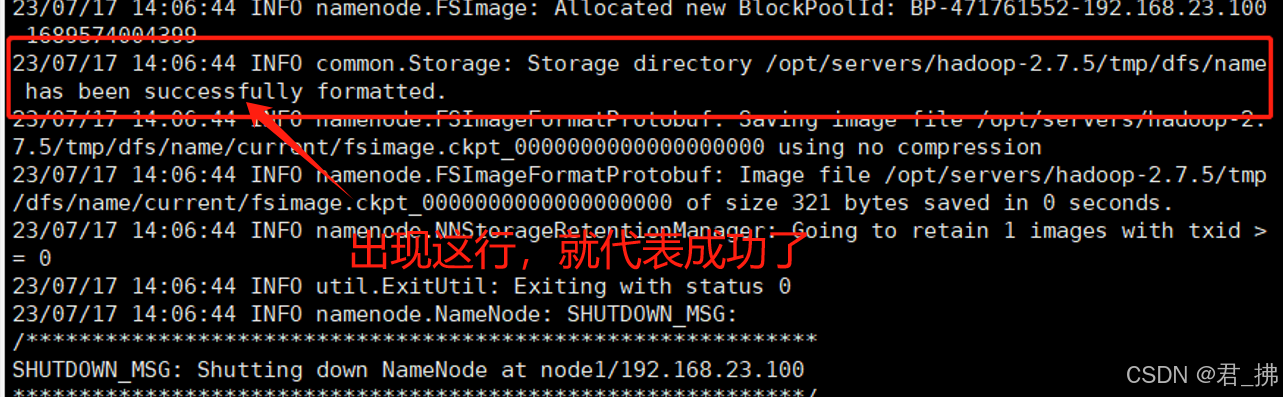
-
启动Hadoop集群:
在Master上输入命令:start-all.sh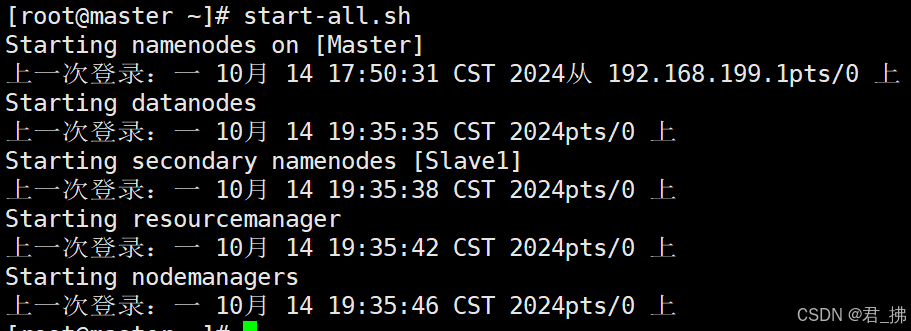
-
查看进程:
在Master上输入命令:jps
(进程共5个,若有少了,请查看Hadoop的那6个文件配置是否有误。)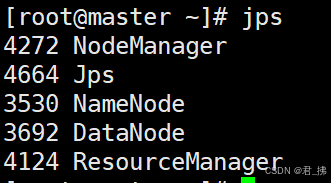
在Slave1上输入命令:jps
(进程共4个,若有少了,请查看Hadoop的那6个文件配置是否有误。)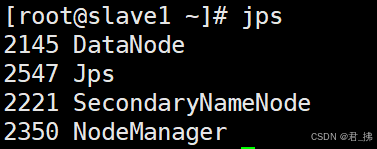
在Slave2上输入命令:jps
(进程共3个,若有少了,请查看Hadoop的那6个文件配置是否有误。)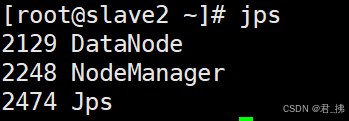
至此,Hadoop集群部署已完成。
6.在Windows上查看Hadoop集群:
1.打开你的浏览器,输入网址:http://Master:50070
2.若出现下图,则代表Hadoop集群部署成功: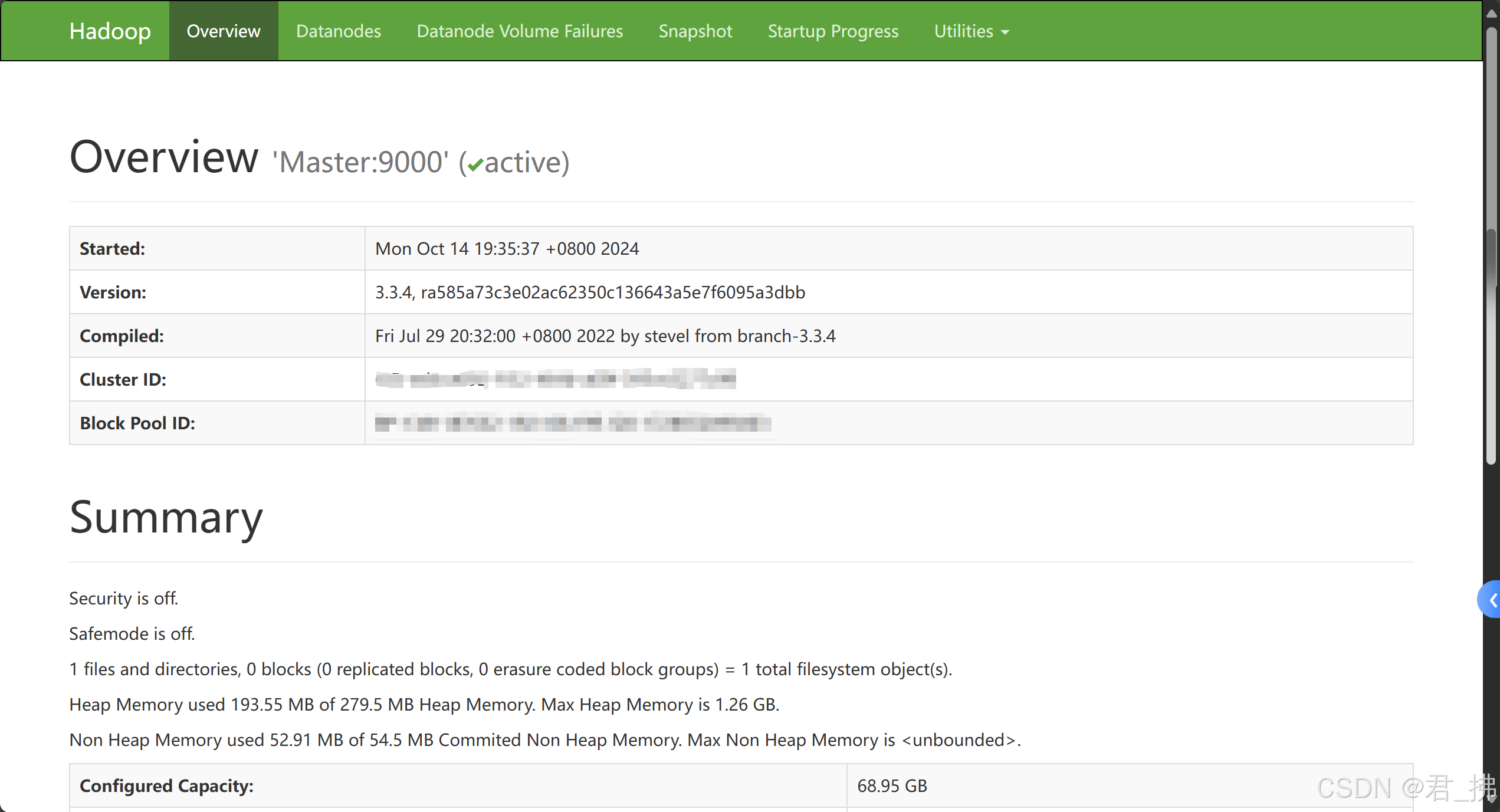
六、总结:
Hadoop集群的构建大致可以分为三大步:
1.ssh的免密配置是为了简化操作流程、提高安全性和效率。
2.JDK的部署是因为Hadoop是基于Java语言开发的,其运行环境依赖于Java虚拟机(JVM)。
3.配置Hadoop的六个核心文件是因为:
- 3.1 hadoop-env.sh:这个脚本文件用于设置Hadoop的环境变量,这些环境变量对于Hadoop的正常运行至关重要。
- 3.2 core-site.xml:这个配置文件包含了Hadoop的核心配置信息,如HDFS和YARN的元数据存储位置、日志存储位置等。这些配置对于Hadoop集群的整体运行至关重要。
- 3.3 hdfs-site.xml:这个配置文件包含了HDFS(Hadoop分布式文件系统)的配置信息,如副本数量、NameNode和DataNode的地址等。这些配置对于HDFS的正常运行至关重要。
- 3.4mapred-site.xml:这个配置文件包含了MapReduce的配置信息,如作业历史服务器的地址、任务执行器的类型等。虽然在Hadoop2.x及以后的版本中,MapReduce已经被YARN取代,但在某些情况下,仍然需要配置mapred-site.xml。
- 3.5 yarn-site.xml:这个配置文件包含了YARN(Yet Another ResourceNegotiator)的配置信息,如ResourceManager的地址、ApplicationMaster的配置等。这些配置对于YARN的正常运行至关重要。
- 3.6 workers文件:这个文件包含了集群中所有工作节点(Worker Node)的主机名或IP地址列表。Hadoop集群需要知道哪些节点是工作节点,以便将任务分配给它们执行。
七、后日谈:
你使用着【君·拂】构建好的Hadoop集群系统,那税收财政数据统计不肖片刻就已经完成了,你终于可以好好的去跟漂泊者约会了,你想到此处心里就美滋滋的,却不知你的师傅早已背着你偷吃完了。【今次的败犬-今汐酱】
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)