
Hadoop 分布式计算实战:从环境搭建到 MapReduce 作业全流程解析
本文围绕 Hadoop 集群展开实操教学,从基础环境准备(版本检查、HDFS 格式化、服务启动 ),到 HDFS 文件操作(目录、文件的增删查 ),再到 MapReduce 作业(WordCount 提交、监控与结果验证 )及 Shuffle 阶段分析,助读者体验大数据处理流程。
目录
三、MapReduce 作业全流程实战:WordCount 案例
Hadoop 作为大数据处理的基础框架,其分布式计算能力是理解大数据技术的核心。本文将通过完整的实操案例,带你从零开始体验 Hadoop 集群环境下的 MapReduce 作业流程,涵盖 HDFS 文件操作、YARN 服务管理及 Shuffle 阶段分析等关键环节。
一、Hadoop 集群基础环境准备
1. 环境版本与配置检查
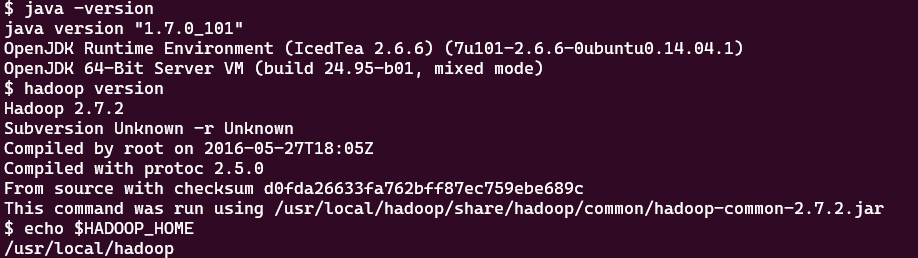
确认Hadoop和java的版本和安装路径,我用的是docker搭建的kiwenlau/hadoop 镜像,不了解的看我之前的文章。
java -version
hadoop version
echo $HADOOP_HOME
如果hadoophome路径没设置,最好设置一下
vi ~/.bashrc
#添加以下内容
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#添加完后保存
source ~/.bashrc # 使配置生效2. 初始化 HDFS 文件系统
首次部署Hadoop或者重置集群时,需要格式化NameNode,谨慎操作,格式化会清空 HDFS 所有元数据,如果已有数据要考虑是否格式化
hdfs namenode -format
3. 启动 Hadoop 服务
启动 HDFS 和 YARN 服务,查看进程状态。
start-dfs.sh
start-yarn.sh
jps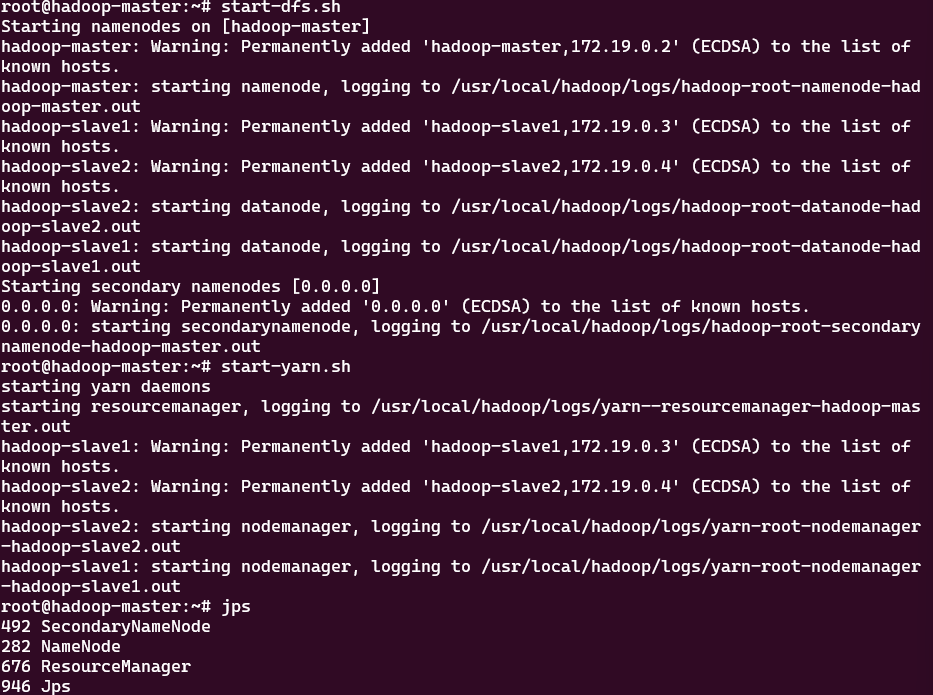
二、HDFS 分布式文件系统操作实战
1. 创建与管理 HDFS 目录
创建多级目录
hdfs dfs -mkdir -p /input
hdfs dfs -mkdir -p /mapreduce/input
hdfs dfs -mkdir -p /mapreduce/output
hdfs dfs -mkdir -p /test/cluster 
创建本地文件
echo "hadoop mapreduce" > words.txt
echo "hello hadoop mapreduce" > test.txt
echo "This is a test file for HDFS" > test-cluster.txt 2.上传与下载文件
2.上传与下载文件
上传文件到HDFS
hdfs dfs -put words.txt /mapreduce/input/
hdfs dfs -put test.txt /input/
hdfs dfs -put test-cluster.txt /test/cluster/
验证上传结果
hdfs dfs -ls /input
hdfs dfs -ls /mapreduce/input
hdfs dfs -ls /test/cluster
把文件下载到本地并查看文件内容
hdfs dfs -get /test/cluster/test-cluster.txt /tmp/
cat /tmp/test-cluster.txt
3.HDFS集群状态查看
通过端粒元命令获取集群整体状态,包括存储容量和节点信息。
hdfs dfsadmin -report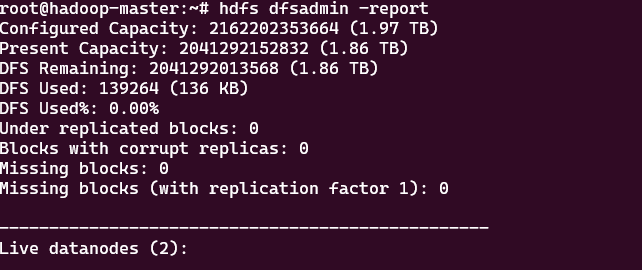
说明:
Configured Capacity:集群总存储容量
DFS Used:已使用存储量
Live datanodes:存活的数据节点列表,如果为0,集群就无法读写三、MapReduce 作业全流程实战1:使用官方WordCount 案例
1. 提交 WordCount 作业
Hadoop自带了WordCount程序,我们可以直接执行,不过要保证/mapreduce/output目录不存在,否则会报错说FileAlreadyExistsException,如果真报错了,可以通过hdfs dfs -rm -r /mapreduce/output 删除目录,然后再重新运行
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /mapreduce/input /mapreduce/output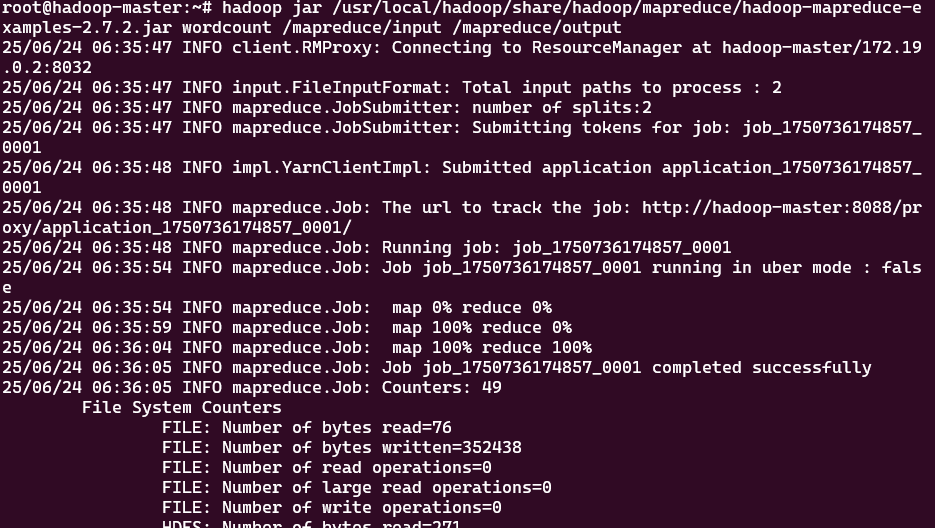 2.监控作业执行过程
2.监控作业执行过程
查看所有作业状态
yarn application -list

查看所有作业的状态
yarn application -list -appStates ALL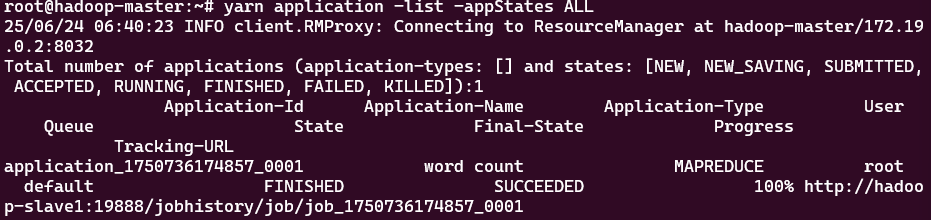
3.验证作业结果
查看 MapReduce 作业的输出结果,确认单词计数准确性
hdfs dfs -cat /mapreduce/output/part-r-00000
四、MapReduce 作业全流程实战2:自己创建WordCount 案例
我们也可以通过自己编写Java代码实现MapReduce作业
1.创建文件目录
mkdir -p ~/hadoop-projects/wordcount/src
cd ~/hadoop-projects/wordcount/src![]()
2.编写MapReduce 程序
vi WordCount.java在文件里写入以下代码
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}保存并退出
3.编译并运行测试程序
创建测试文件
echo "Hello Hadoop MapReduce" > test1.txt
echo "Hello World" >> test1.txt
创建目录 并将输文件复制到hadoop文件系统
mkdir input
hdfs dfs -mkdir -p input
hdfs dfs -put test1.txt input
编译程序并创建jar包
javac -classpath `hadoop classpath` WordCount.java
jar cf wc.jar WordCount*.class
运行程序
hadoop jar wc.jar WordCount input output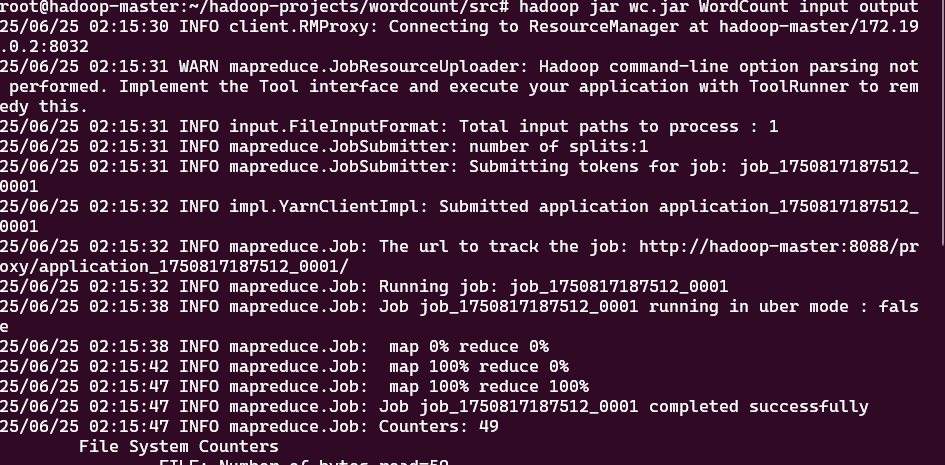
查看输出结果
hdfs dfs -cat output/part-r-00000
五、分析MapReduce 的 Shuffle 阶段
1.从日志中提取Shuffle信息
Shuffle 是 MapReduce 的核心阶段,通过日志可分析数据流动过程:
yarn logs -applicationId <你的pplicationID> | grep -iE "shuffle|merge|sort" 我的作业太简单了,所以Shuffel完成的太快,日志没有相关信息。
我的作业太简单了,所以Shuffel完成的太快,日志没有相关信息。
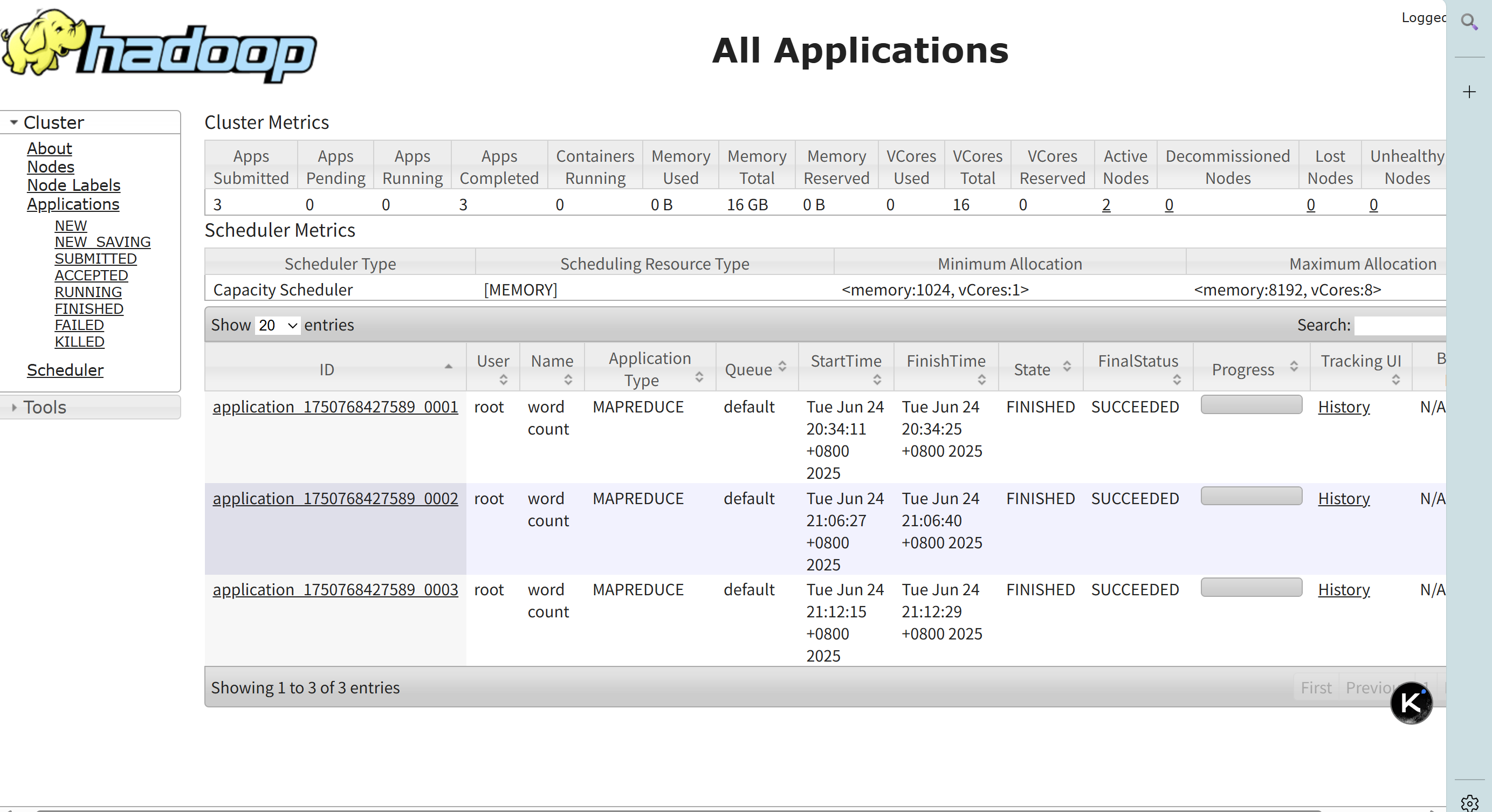
2.通过 YARN 界面分析 Shuffle 指标
在本地浏览器输入http://<主节点 IP>:8088(若在本地机器且未修改端口,可访问 http://localhost:8088 ),可以看到相关信息
六、总结
这篇文章写的有些潦草,如果有什么问题可以评论或者私信我。如果想详细了解MapReduce,大家可以去看b站视频理解相关概念,或者点赞高的话我也会考虑写相关文章帮助大家理解。
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)