
Hadoop组件——HDFS
1,HDFS简介HDFS(Hadoop Distributed File System)是hadoop项目的核心子项目,在大数据开发通过分布式计算对海量数据进行存储与管理。它基于流数据模式访问和处理超大文件的需求而开发,可以运行在廉价的商用服务器上,为海量数据提供了不怕故障的存储方法,进而为超大数据集的应用处理带来了很多便利。HDFS的特点:HDFS非常适合使用商业硬件进行分布式存储和分布式处理。
1,HDFS简介
HDFS(Hadoop Distributed File System)是hadoop项目的核心子项目,在大数据开发通过分布式计算对海量数据进行存储与管理。它基于流数据模式访问和处理超大文件的需求而开发,可以运行在廉价的商用服务器上,为海量数据提供了不怕故障的存储方法,进而为超大数据集的应用处理带来了很多便利。
HDFS的特点:
- HDFS非常适合使用商业硬件进行分布式存储和分布式处理。它具有容错性,可扩展性,并且扩展极其简单。
- HDFS具有高度可配置性。大多数情况下,需要仅针对非常大的集群调整默认配置。
- HDFS是Hadoop的核心框架,而Hadoop是用java编写的,因此可以运用于所有主流平台上。
- 支持类似shell的命令直接于HDFS交互。
- HDFS内置了Web服务器,可以轻松检查集群当前的状态。
2,HDFS总体架构
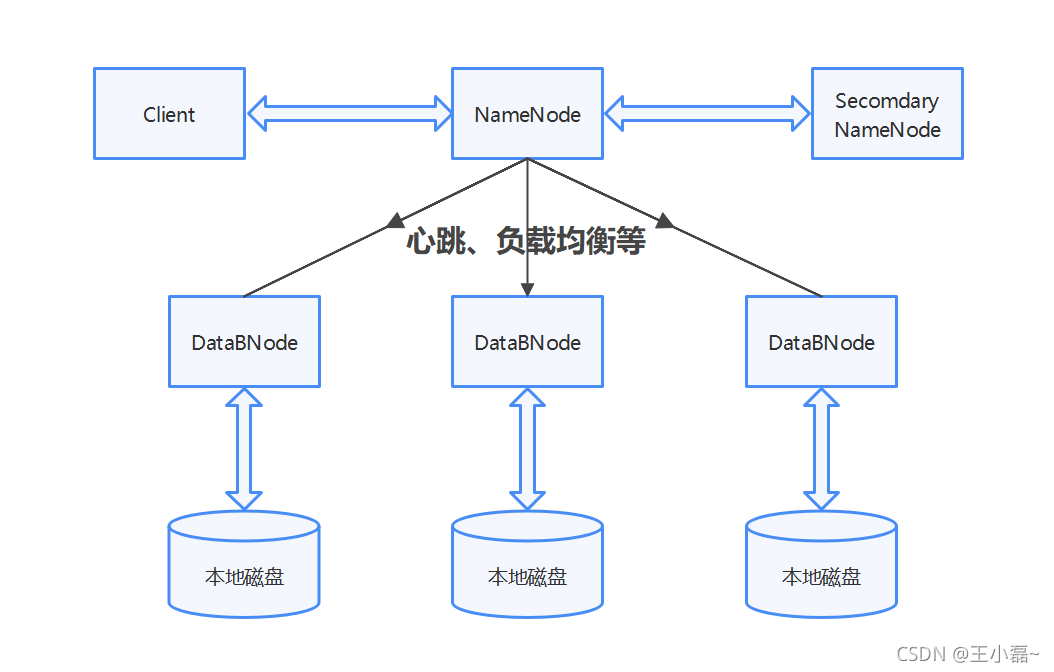
HDFS是一个典型的主/从架构的分布式文件系统。一个HDFS集群由一个元素据节点(称为NameNode)和一些数据节点(称为DataNode)组成。NameNode是HDFS的主节点,是一个用来管理文件元数据(文件名称,大小,存储位置等)和处理来自客户端的文件访问请求的主服务器,DataNode是HDFS的从节点,用来管理对应节点的数据存储,及实际文件数据存储于DataNode上,而DataNode中的数据则保存在本地磁盘。
当HDFS系统启动后,NameNode上会启动一个名称为“NameNode”的进程,DataNode上会启动一个名称为“DataNode”的进程。
典型的HDFS集群部署是一台专用的计算机只运行NameNode进程,集群中的其他计算机都运行DataNode进程。HDFS架构并不排除在同一台计算机上运行多个DataNode进程,但在实际部署中很少出现这种情况
HDFS集群中单个NameNode的存在极大地简化了系统的体系结构。NameNode是HDFS元数据的仲裁者和存储库。该系统的设计方式是,用户数据永远不会流经NameNode。
现在大三,双非二本院校 大数据专业,个人原因不打算考研,准备主攻Hadoop生态系统。机器学习等大数据算法。购买了一本张伟洋老师的hadoop大数据技术开发实战,希望通过写博客记录我每天的学习成果。感兴趣的小伙伴可以一起学习,一起进步!
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)