
一文了解大语言模型推理性能优化关键技术之 PD 分离及典型的 PD 分离方案
本文首先明确大语言模型推理系统的关键性能指标,继而剖析预填充(Prefilling)与解码(Decoding)这两个阶段的核心特征。基于上述分析,本文指出:持续批处理(Continuous Batching)采用阶段隔离与抢占机制,虽有助于提高系统吞吐量并降低首令牌延迟(Time To First Token,TTFT),但会显著增加词元间延迟(Token-to-Token Delay,TBT),
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/
一、PD 分离是什么?
本节在讲解 PD 分离之前,首先明确常用的大语言模型(Large Language Models,LLMs)推理系统的性能指标:
-
服务级别目标(Service-Level Objectives,SLOs):系统在提供推理服务过程中,为保障性能、可用性和可靠性所设定的量化目标阈值。它通常涵盖 响应时延(Latency)、可用性(Availability) 和 错误率(Error Rate) 等关键指标,用于评估系统是否持续满足预期服务级别。SLO 实际是服务级别协议(Service-Level Agreement,SLA)的基础,能够指导系统设计、容量规划与运行优化,从而在用户体验(User eXperience,缩写为 UX)与资源利用之间取得平衡。
-
首 Token 时延(Time To First Token,TTFT):从系统接收到完整输入提示(Prompt)到生成输出序列中的第一个词元(Token)所经历的时间。该指标反映模型在推理初始阶段的实际响应速度,包括请求解析、模型前向计算及首个解码步骤的耗时,通常用于评估系统的实时性。TTFT 值越小越好。
-
平均输出词元时间(Time Per Output Token,TPOT):系统在解码过程中每输出一个词元的平均时延,通常以毫秒 / {/} /词元(ms / {/} /token)为单位。其计算方式为 D 阶段的 总生成时间 除以对应的 输出词元数。TPOT 值也是越小越好。
-
词元间(Token Between Token,TBT)时延 (也称为 Inter-Token Latency,ITL):解码阶段,生成当前这个词元后,再到生成下一个词元之间的耗时,反映模型在解码阶段的实时生成流畅度。从理论上看,其计算方式应为统计所有相邻词元时间间隔的均值或中位数。ITL 值越小越好,表示模型输出越流畅,交互实时性越高。
-
推理总时延(Latency):P 阶段的 TTFT + D 阶段的总生成时间。
-
端到端时延(End-to-End Latency,E2EL):推理服务从接收到完整输入请求开始,到系统生成完整输出结果为止所经历的总时间,涵盖输入预处理、算子下发、前向推理计算、自回归式解码以及后处理等全过程。该指标适用于综合评估系统的整体响应速度。
-
指数移动平均(Exponential Moving Average,EMA)时延:使用时间序列分析领域的思路,对连续推理请求的响应时延应用指数移动平均算法,赋予近期观测点较高权重,同时平滑历史数据,从而反映系统在动态负载下的时延变化趋势与短期性能波动。
-
模型尺寸(Model Size):在推理过程中需要占用的内存量,包括模型参数、激活值、缓存以及运行时中间张量(如果存在)等,这是评估 LLM 在 AI 加速器上部署与运行效率、并行策略设计和资源分配的关键指标。
-
峰值内存(Peak Memory):推理过程中,LLM 在任意时刻占用的 最大内存量,主要由两部分组成:模型参数(Model Parameters) + KV 缓存(Key-Value Cache)。因此,简化后的 LLM 推理过程中的内存和时延变化如下图示意:

「备注:上面的示意图源自这篇综述论文 A Survey on Efficient Inference for Large Language Models」
-
吞吐量(Throughput):系统在单位时间内生成的词元数或完成的推理请求数,通常以 Tokens Per Second(词元 / {/} /秒,TPS)或 Requests Per Second(请求 / {/} /秒,RPS)为度量单位。该指标反映系统的并行处理能力与资源利用效率,是评估推理服务的成本效益和可扩展性的关键之一。Throughput 的值越大越好。
-
Goodput 与 Throughput 类似,但要求请求完成必须满足了 SLO 的性能要求(才算 “Good”);吞吐量统计每秒钟生成的输出词元数或完成的推理请求数,但未考虑 SLO 的约束,Goodput 的值也是越大越好。如下图示意:

「备注:上面的示意图源自这篇博客 https://hao-ai-lab.github.io/blogs/distserve/。补充说明:SLO 的一个示例,P90 TTFT SLO = 190 ms,这意味着 90% 的请求的首个词元的生成时延需小于或等于 190 ms。实际上,时延与吞吐量之间实际存在固有的权衡关系:设定此类 SLO 的本质在于,用户关注的时延与厂商关注的吞吐量往往不可兼得。因此,厂商通过设置 SLOs 在保障用户体验的前提下,最大化系统吞吐量。这实质上是一个约束条件下的最优化问题。」
- MFU(Model FLOPs Utilization):模型算力利用率,即:模型实际执行的浮点运算量(FLOPs)占理论最大可用计算量的比例,用于衡量模型在 AI 加速器(如 GPUs、NPUs)上计算资源利用的效率。MFU 表示模型在推理过程中对底层算力的 “饱和度” 或 “利用率”,反映了系统的计算效率与优化程度 —— MFU 越高,说明推理系统对硬件算力的利用越充分。其计算公式通常为:
MFU = 模型实际执行的 FLOPs 硬件在该时间内的峰值 FLOPs × 100 % \text{MFU} = \frac{\text{模型实际执行的 FLOPs}}{\text{硬件在该时间内的峰值 FLOPs}} \times 100\% MFU=硬件在该时间内的峰值 FLOPs模型实际执行的 FLOPs×100%
接着,一个 LLM 以自回归方式逐步生成下一个词元的推理过程如下图示意:
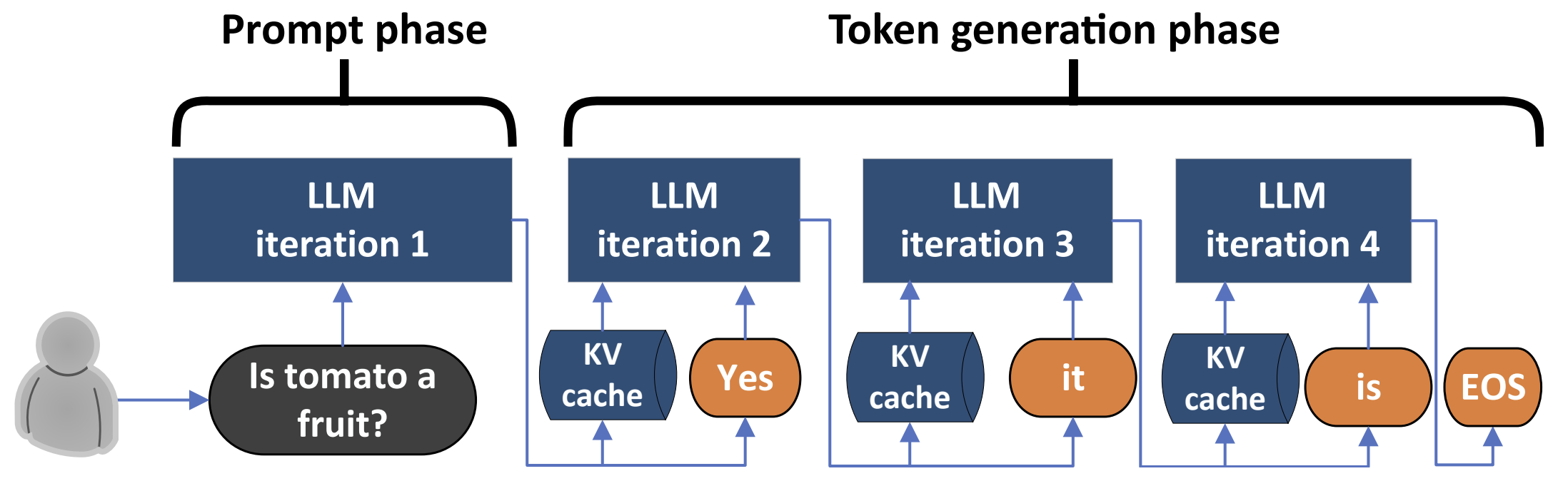
「备注:上面的示意图源自这篇论文 Splitwise: Efficient Generative LLM Inference Using Phase Splitting」
在 LLMs 的实际大规模部署中(通常是多机多卡),推理优化是提升模型推理效率的关键环节。其中,“Prefilling 与 Decoding 分离(PD 分离)” 是一种流行的优化技术,其工作流程如下图示意:

「备注:上面的示意图源自这篇博客 https://hao-ai-lab.github.io/blogs/distserve/」
然后,明确 PD 分离的定义和主要特征。
PD 分离(Prefilling-Decoding Disaggregation)是将 LLM 的推理过程划分为两个独立阶段并在不同的 GPU/NPU 实例上执行:
-
Prefilling(预填充)阶段:处理输入的完整提示(Prompt),即词元(Token)序列;计算所有输入词元的上下文表示,并生成初始的 KV 缓存(Key-Value Cache 来自注意力层的 KV 向量);输出首个词元。此阶段的时延就是 TTFT,通常在 50~400 ms 量级。一次性计算:以存换算,避免在解码阶段重复计算历史 Tokens 的中间状态。Prefilling 是计算密集型阶段,但对 AI 加速器(比如 GPU、NPU 等)内存带宽的要求不高。
-
Decoding(解码)阶段:访存密集型任务,基于 P 阶段已生成的 KV 缓存,以自回归方式逐步生成后续的每一个词元,直至当前输出词元是截止词元 eos_token(End Of Sequence,EOS)或者生成的词元总数目已达输出上限(max_tokens)。其时延称为 TBT(Token Between Token),通常在 25~55 ms 范围内。需要增量更新 KV Cache:每次生成新 Token 时,仅计算当前 Token 的 KV 向量并追加到 KV Cache 队列中,但需要访问完整的 KV Cache 数据。因此,与 Prefilling 不同,Decoding 需要快速的内存访问,对时延比较敏感,但计算量相对较小。
P 阶段的主要特征包括:
-
计算密集型:执行完整的 LLM 前向推理,计算全部输入词元的注意力矩阵,其计算复杂度与序列长度的平方呈正比,即 O ( n 2 ) O(n^2) O(n2)。
-
并行化处理:所有输入词元都能够被并行处理,从而充分发挥 GPU、NPU 等 AI 加速器的算力优势。因为可以并行,所以速度相对较快。
D 阶段的主要特征包括:
-
输入: 之前所有的输入 + P 阶段生成的首个 Token。任务:基于已知的所有信息,预测下一个最有可能的 Token。方式:串行计算。一次只生成一个 Token,然后把它加到已知信息里,再进行下一次生成。这个过程循环往复,直到生成结束。
-
内存密集型:需频繁访存历史 Tokens 的 KV Cache 数据,数据传输密集,内存与通信带宽 易成为性能瓶颈。
-
注意力计算聚焦于最新 Token:其计算复杂度与序列长度呈线性关系,即 O ( n ) O(n) O(n)。
P 阶段与 D 阶段的主要特征总结如下表所示:
| 特性 | P 阶段 | D 阶段 |
|---|---|---|
| 输入 | 完整的输入提示 Prompt | 前一步生成的 Token |
| 计算复杂度 | O ( n 2 ) O(n^2) O(n2), n n n 为输入 Prompt 的长度 | 注意力计算聚焦于最新 Token,约为 O ( n ) O(n) O(n) |
| 并行性 | 完全并行 | 严格串行 |
| 资源消耗 | AI 加速器的计算性能 | 内存和通信带宽 |
| 输出 | 除首个 Token 外,无新 Token 生成 | 逐个生成后续 Token |
| 性能瓶颈 | 受限于计算能力(FLOPs) | 受限于内存带宽,即 KV Cache 的读写速度 |
| 工程优化 | 适用 Flash Attention 等技术加速长序列处理 | 通过 Page Attention、缓存压缩等技术降低 KV Cache 内存占用 |
🏠 最后,举一个生活中的例子:家庭烹饪
-
P 阶段:准备所有食材并进行切配、调味等预处理,开始制作第一道菜。该过程需大量准备工作,类似于模型的预填充阶段。
-
D 阶段:依次加入食材,逐步完成菜肴烹制,该过程类似于模型的解码阶段。
-
对于做一份简单的番茄炒鸡蛋,实际一个人也容易做好;但对于做一桌子丰富的菜肴,若在同一个时段内,就一个人同时进行食材准备与烹饪,可能导致烹饪效率降低。将两个过程分离,由两个人分别执行,就能有效提升整体效率。
二、为什么需要 PD 分离?
应用程序实际具有不同的 SLO,如下图所示:
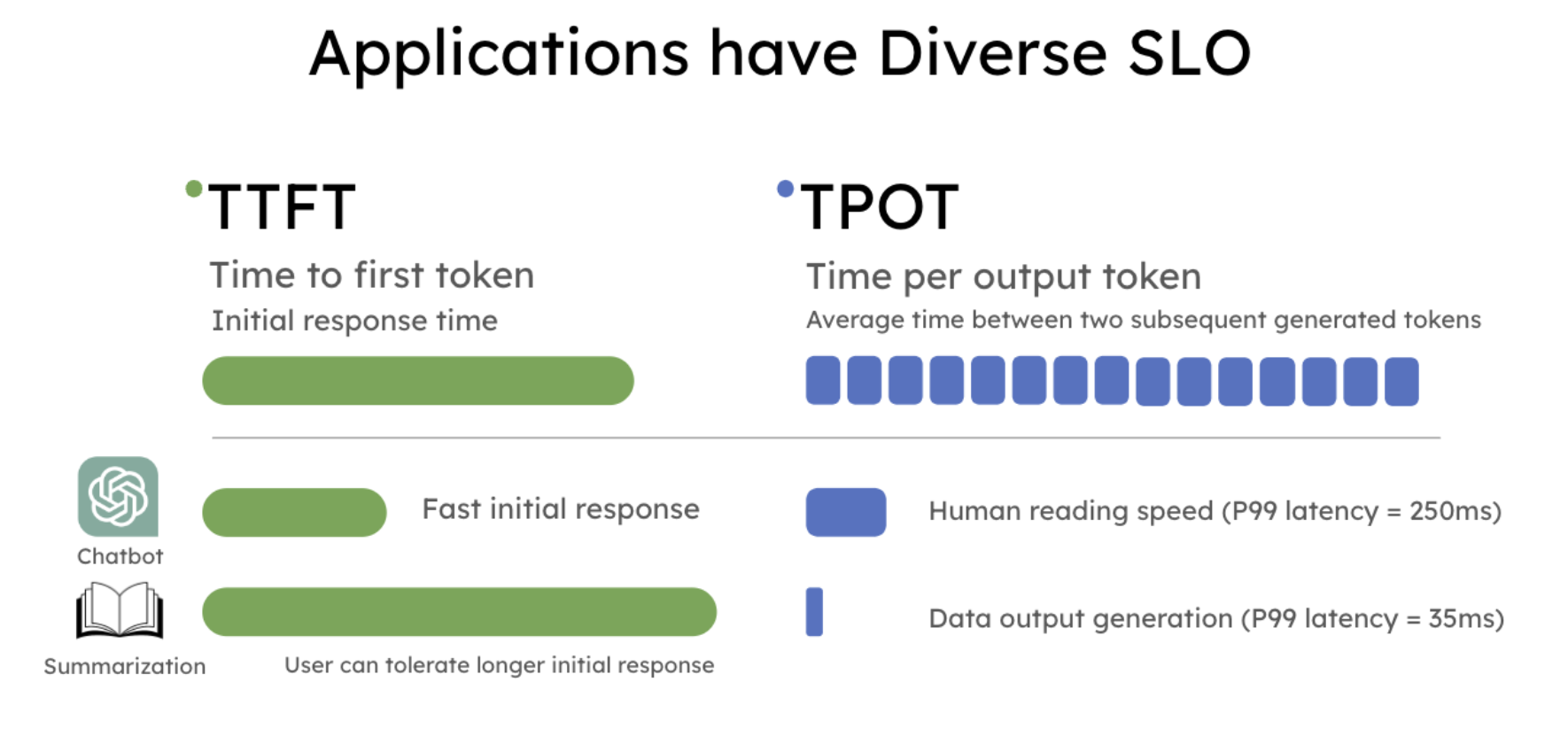
「备注:上面的示意图源自这篇博客 https://hao-ai-lab.github.io/blogs/distserve/」
在传统架构中,这两个阶段通常在同一张卡上(这里的 “卡” 泛指 GPU、NPU 等 AI 计算加速器)顺序执行;但由于它们在计算特性、资源需求、配置策略和性能指标上存在显著差异,并且具有不同的推理特性,因而可能引发性能瓶颈。
举个例子,在单条请求的场景中,LLM 推理首先通过 P 阶段生成 KV Cache 和首个 Token,随后进入 D 阶段执行自回归解码以生成后续 Token。这种单批次推理情景下,P 与 D 阶段耦合执行(部署在同一张卡上),其吞吐量较低。该模式表面看似合理,但要实现高吞吐量,需采用持续批量推理技术来同时处理许多请求,例如采用 Continuous Batching 技术,如下图所示:
「备注:下面两张示意图分别源自:https://hao-ai-lab.github.io/blogs/distserve/、https://zhuanlan.zhihu.com/p/1919794916504114120」
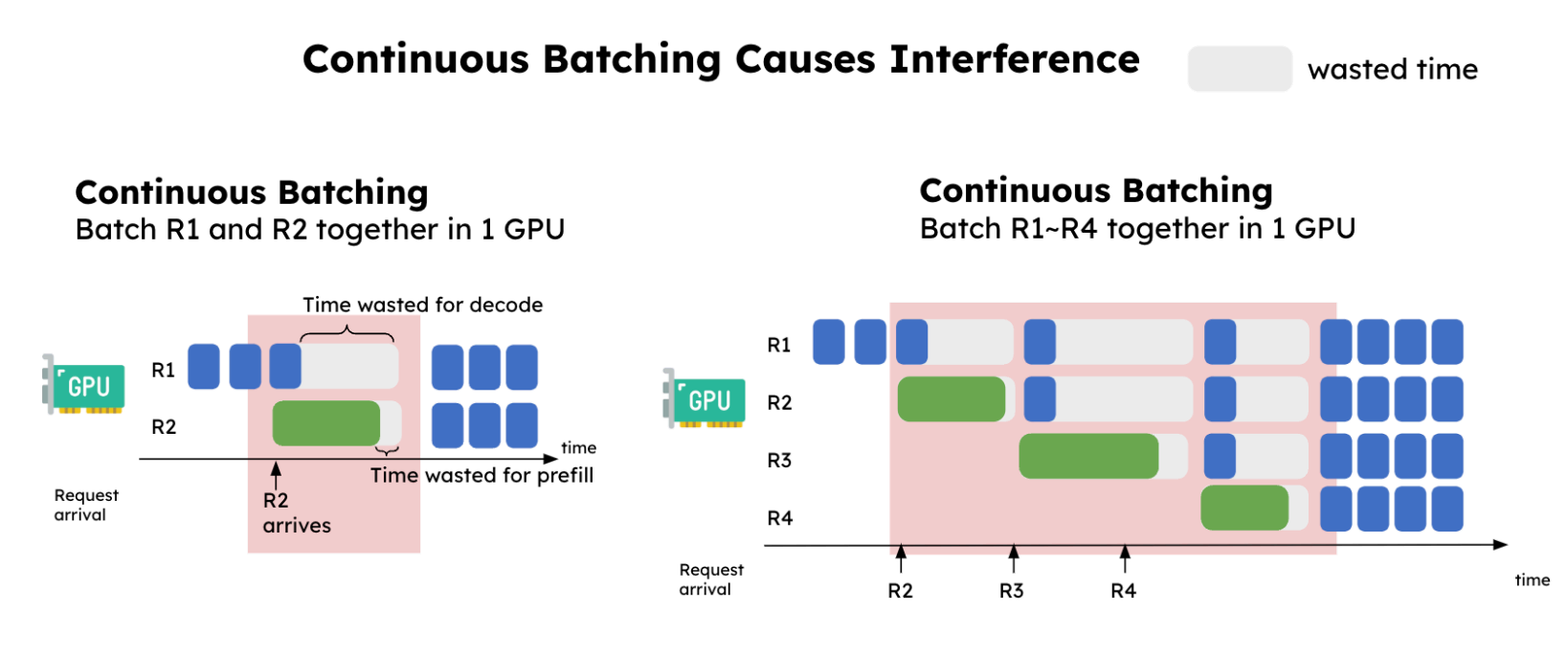
将 Prefilling 与 Decoding 部署在同一张卡上,并采用持续批处理,会导致两个主要问题:
-
首先,不同请求之间在计算资源上会相互干扰,造成资源浪费,并导致 TBT 时延出现尖峰,使用户感知到明显卡顿;
-
其次,例如当批次大小为 2 时,若请求 A 正处于 D 阶段,而新请求 B 刚加入批次并执行 Prefilling,且 B 的 Prefilling 处理时间超过 A 的 Decoding 时间,则 A 请求解码输出 Token 的时延将显著增加。同时,由于 A 与 B 对计算资源的竞争,B 请求的首 Token 时延也可能增加。
-
长时间运行的 Prefilling 任务会持续占用计算资源,严重干扰并阻塞对时延敏感的 Decoding 任务。不良影响是系统生成 Tokens 的吞吐量显著降低,同时服务时延出现明显波动。
总体而言,推理服务在实际运行中常需并行处理许多推理请求。每个请求均有各自的 P 和 D 需求。LLM 推理引擎的调度器会根据显存占用和请求队列状态,在 P 和 D 任务之间动态切换,以推进整体推理流程。然而,由于 AI 加速器在同一时刻仅能执行其中一类任务,当计算密集型的 Prefilling 任务占用卡时,Decoding 任务便需等待,从而增加 TBT;反之亦然。
鉴于 P 阶段主要影响 TTFT,而 Decoding 过程则主导 TBT,将两者混合调度会令这两个指标难以同时优化。如下图所示:
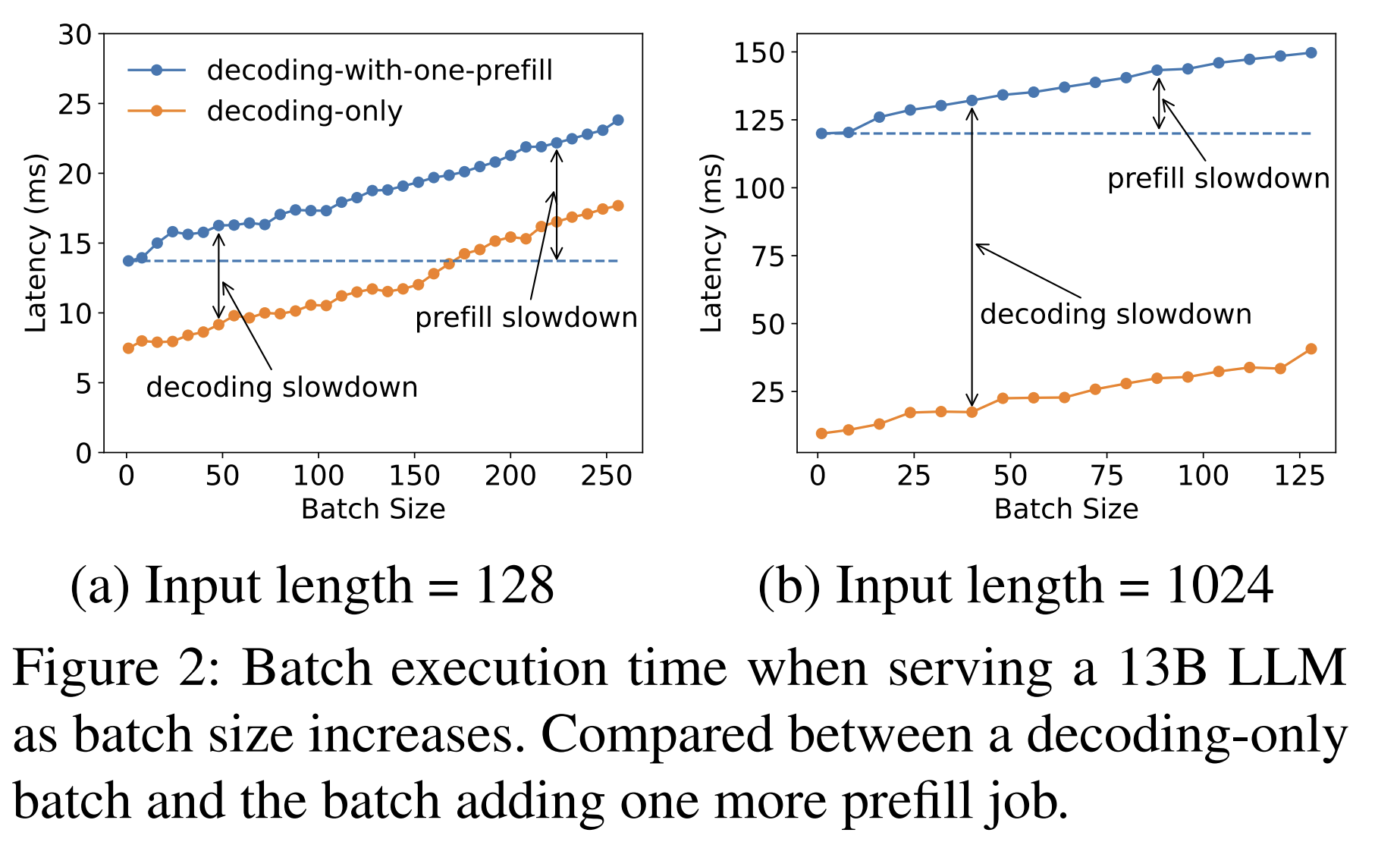
「备注:上面这张图源自这篇论文 DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving」
为此,P 与 D 分离技术的核心思想是将两个阶段解耦,并将其分配至不同的卡上执行,通过各自独立优化,最终提升整体推理效率和吞吐量。Prefilling 与 Decoding(PD)分离的架构应运而生,其示意图如下所示:
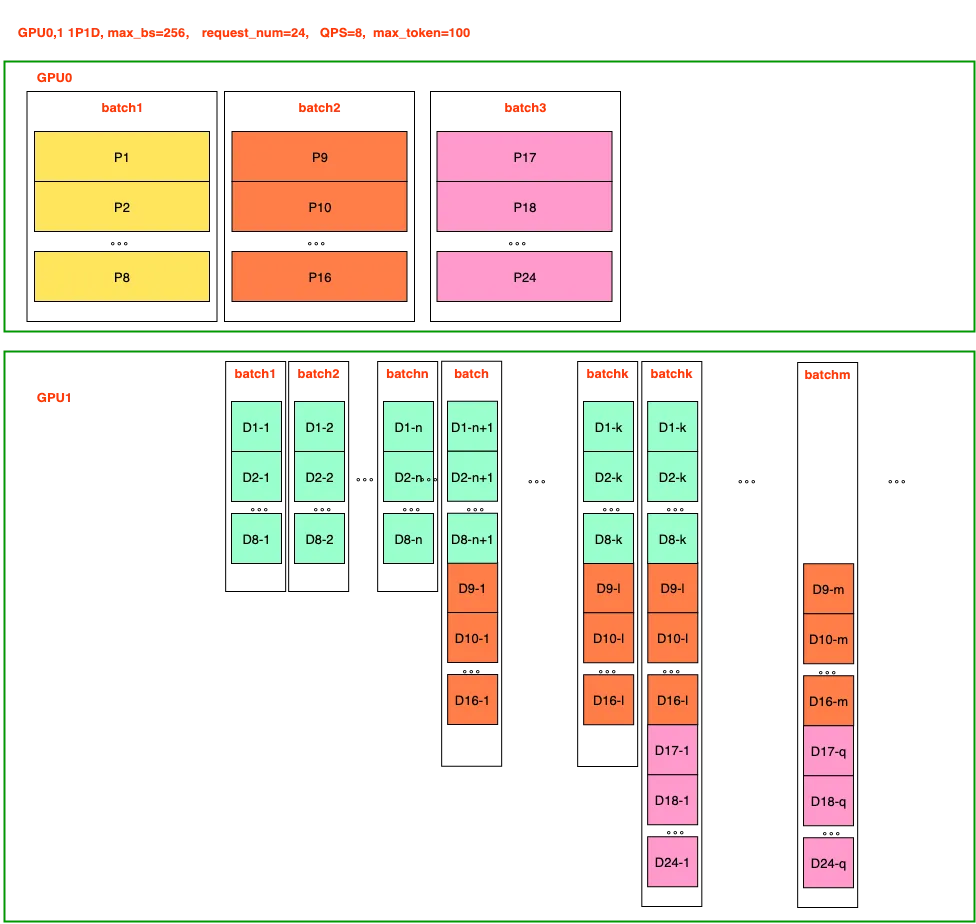
由上图可知,PD 分离架构可以有效提升 D 阶段的处理效率。从双卡并行(TP2)转变为单 Prefilling 卡与单 Decoding 卡(1P1D)的配置后,用于 P 阶段的计算卡数量减少。在面对大批次规模或长序列输入时,这会增加首 Token 时延(TTFT)。此外,由于 P 阶段计算密集,而 D 阶段数据通信量较大,PD 分离架构允许为两个阶段分别配置不同类型的 AI 加速器,从而实现最佳性价比。
补充说明:
- 要做 PD 分离的一个现实背景可能是国内 GPUs 供应受限以及成本问题。部分公司采用 RTX 4090 负责 P 阶段、H20 负责 D 阶段的协同方案,从而有效利用两种卡在不同阶段的性能优势,减少资源浪费。RTX 4090 与 H20、A100 的参数对比如下图所示:
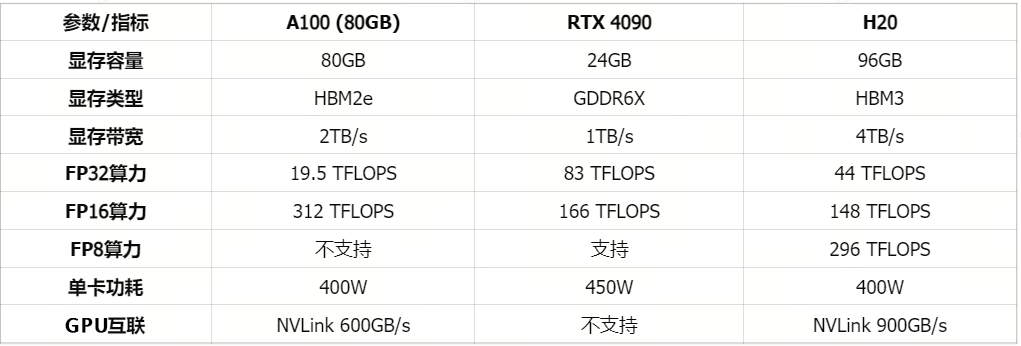
- PD 分离的本质是计算资源的物理分离与专业化:计算性能强但传输带宽较低的卡进行 Prefilling,Prefilling 卡专门负责高效处理批量传入的请求,最大化并行计算能力以提升 Prefilling 任务的吞吐量和 GPU 利用率;使用计算能力一般但传输带宽较高的卡进行 Decoding,Decoding 卡专门负责执行低时延的 Token 生成,通过维持稳定的并发请求数,实现最高的 Decoding 吞吐量。
讲到这里,为什么需要 PD 分离的原因已然明了:将 Prefilling 与 Decoding 这两个不同任务进行分离,使其互不干扰。主要优势包括:
-
专用资源分配:Prefilling 与 Decoding 任务可在不同 AI 加速器上调度与扩展。例如,当工作负载中存在大量提示重叠(例如在多轮对话或智能体工作流中)时,大部分 KV 缓存可被复用,从而降低 P 阶段的计算需求,并将更多资源集中于 D 阶段。P 实例和 D 实例使用不同的硬件资源,避免资源的冲突。D 实例可以使用更大的 batch_size,计算效率更高。
-
独立调优:可以根据 P 与 D 阶段需要的计算资源,独立地调整资源的比例,资源利用更充分;P/D 可分别采用不同的优化策略(例如张量并行或流水线并行),从而更精准地优化 TTFT 与 TBT 等时延指标,以确保满足 SLOs。
总体而言,P 和 D 两个阶段在计算特性、批处理方式和并行策略上的优化倾向存在差异。传统耦合式推理框架一般只能在 TTFT 与 TPOT 之间进行权衡(trade-off)。而解耦后的框架支持更精细化的策略配置,实现对两个阶段的分别优化,从而更好地满足服务级别目标。
三、典型的 PD 分离方案举例
现代 PD 分离系统(如 DistServe 和 Mooncake)通过 KV Cache 传输技术和调度算法的优化,能够将 LLM 推理的计算与内存成本控制在合理范围内,这一改进显著提升了模型的推理效率。
DistServe 优化了资源分配和并行策略,以达到更好的 Goodput 和 SLOs,DistServe 的运行时系统架构如下图示意:
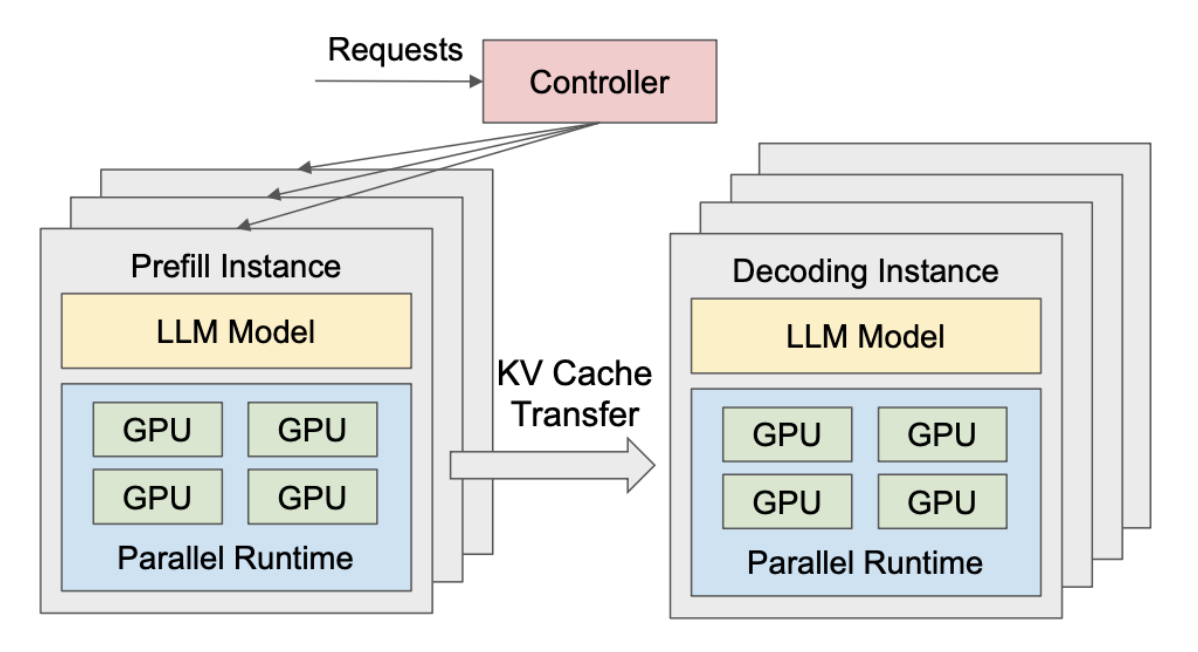
PD 分离式架构:
-
P 和 D 这两个阶段被拆分到不同的 GPU 实例上独立运行。
-
LLM 的预填充阶段,部署在 P Instance 上,专注于 P 阶段的计算,得到 KV 缓存及输出首个词元。
-
LLM 的解码阶段,部署在 D Instance 上,专注于 D 阶段的自回归生成任务,逐步生成后续词元。
-
在 DistServe 中,P 实例数和 D 实例数可以不一样。Prefilling 与 Decoding 解耦,两阶段在并行方式、Batch 策略上分别优化,有助于同时满足 TTFT 和 TBT 的 SLOs。
-
DistServe 首先筛选出满足硬件约束的所有配置。接着,通过模拟器(Simulate 函数)评估各配置的有效吞吐量。最后,系统采用网格搜索方法,在所有可选参数中确定能够最大化有效吞吐量的最优配置。该过程类似于机器学习中的超参数调优。
推理流程如下:P Instance 在完成 KV Cache 的计算后,会将其传输给 D Instance 进行解码,由后者继续生成后续内容。PD 分离架构的优势在于,P 和 D 两个阶段可部署于不同机器,便于各自独立优化,从而提升整体吞吐量与计算资源利用率,同时降低生成每个 Token 的时延。
P 阶段是计算密集型任务,在推理过程中适合采用张量并行策略。D 阶段则是内存密集型任务,适合采用数据并行与流水线并行策略。若将 P 与 D 阶段部署于同一张卡,则两者的并行策略难以独立配置。
-
将 P 与 D 阶段耦合部署的策略会导致两者资源分配与并行策略的相互耦合,这样的耦合可能导致两个阶段各自的优化目标 SLOs(Service-Level Objectives)发生冲突。
-
DistServe 论文的实验结果表明,P 阶段在请求率较小时更适合采用 张量并行(Tensor Parallelism,TP),而在请求率较高时则更适合 流水线并行(Pipeline Parallelism,PP)。对于 D 阶段,随着 GPU 数量的增加,PP 可显著提高吞吐量;TP 则能降低时延,从而减少单个请求的处理时间。
DistServe 还针对以下两种硬件场景提供了相应的 Placement 方案,其核心思想分别为:
-
节点间带宽极高时,KV Cache 的传输开销可忽略不计。紧耦合放置(Co-located Placement):这种方案适用于计算节点内部具备高速互联的同构集群,例如通过 NVLink/NVSwitch 连接的 GPU 服务器。它的核心思想是将 P 实例跟与之配对的 D 实例放置在同一个计算节点内,或者通过超高速网络直连的 GPU 上。这样做可以充分利用节点内的极致通信带宽,使得分离后 KV Cache 的传输时延远低于单个 Token 的解码时间,从而几乎感觉不到通信开销的存在。
-
节点间带宽有限时,KV Cache 的传输时延较为显著(异构集群或跨节点网络带宽受限)。带宽感知的松耦合放置(Bandwidth-Aware Placement):在更加复杂和普遍的跨节点或异构集群环境中,网络带宽可能成为瓶颈。此时,DistServe 采用一种更为灵活和智能的策略。系统在调度请求时,会实时考虑集群的网络拓扑和带宽状况,动态地将 P 实例分配给那些与目标 D 实例之间网络路径最优(带宽最高、延迟最低)的可用节点。这相当于在调度器中内置了一个 “网络地图”,确保 KV Cache 的传输始终走在一条 “高速公路” 上,而不是拥堵的 “乡间小路”。
-
以 “有效吞吐量” 为目标:DistServe 的所有优化,包括 Placement,最终目标都不是单纯追求最高的吞吐量(Throughput),而是提升有效吞吐量(Goodput),即在满足每个请求的延迟目标(TTFT 和 TBT)的前提下,系统所能完成的最大工作量。智能的 Placement 正是确保时延 SLO 的关键一环。

PD 分离架构一个核心点在于,KV Cache 的计算和传输,它直接影响整个架构的调度设计。Mooncake 进一步推进并扩展了 PD 分离架构 「备注:Mooncake 还收获了计算机文件与存储技术领域顶会 FAST-2025 最佳论文荣誉」,设计出一种以键值缓存(KV Cache)为中心的分离式 LLM 服务架构。
通过优化 KV Cache 的管理和传输,Mooncake 在确保 SLOs 的前提下,最多可将吞吐量提高 525%,相比 vLLM,有效请求容量提升 107%,长上下文和大负载场景优势显著;在实际工作负载下,Mooncake 可使系统处理的请求量增加 75%,最终取得显著的性能 & 效率的双提升。
如下图 Figure 1 所示,Mooncake 同样采用了分离式架构。此处的 “分离” 实际包含两层含义:
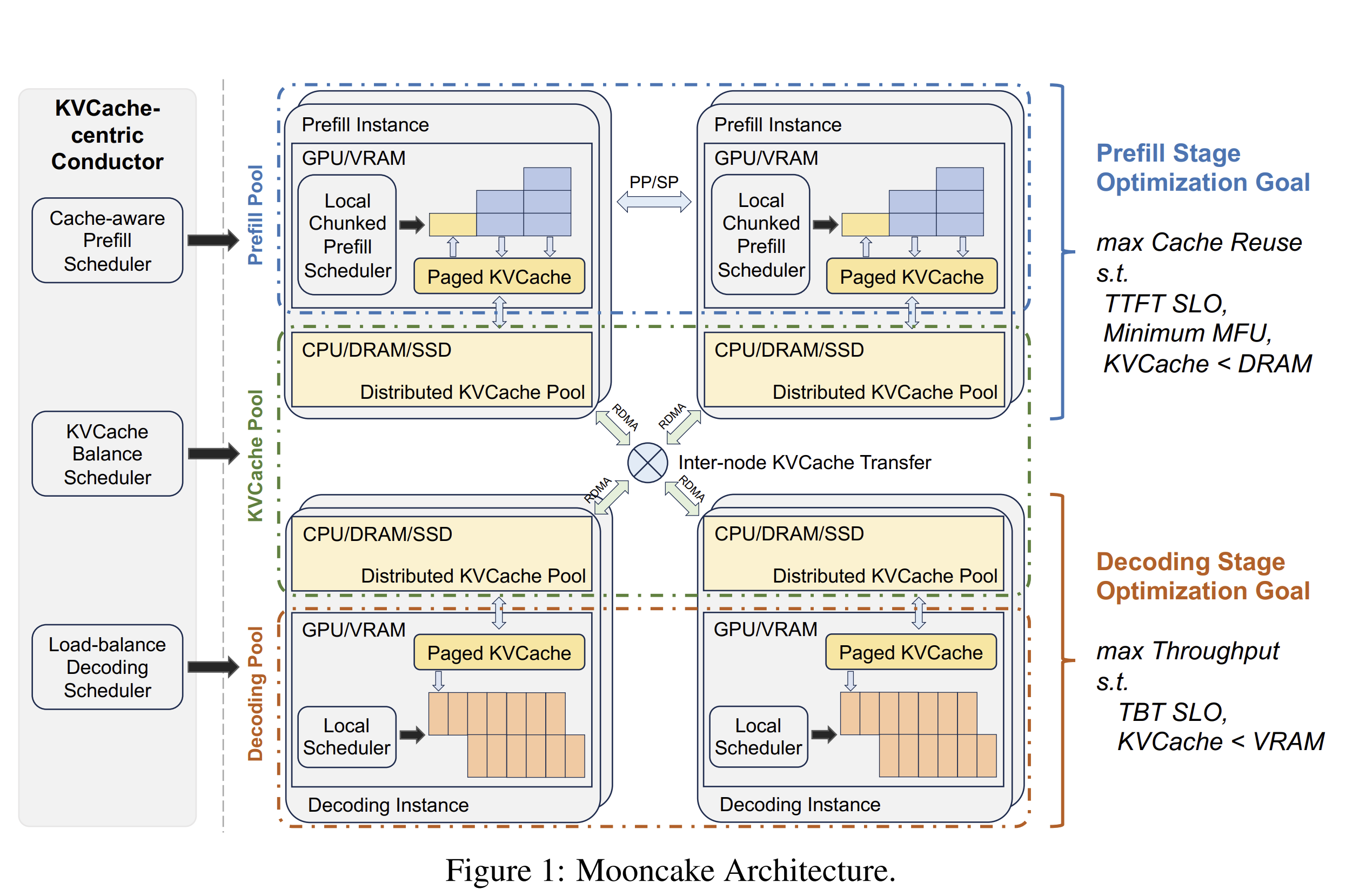
-
第一,将 Prefilling 与 Decoding 的计算资源进行分离,这其实与现有工作(如 Splitwise 和 DistServe)的做法一致。在 P 阶段,优化目标是利用请求间可能存在的共同前缀,尽可能复用 KV Cache,这种做法有助于降低成本,因此,你在 Moonshot AI 的 Kimi API 平台中可以看到缓存命中/缓存未命中的计费价格是不一样的。
-
满足 TTFT 的服务级别目标(SLO),并尽可能提高模型浮点运算利用率(MFU),同时确保 KV Cache 总量不超过 CPU 内存容量限制。在 D 阶段,优化目标为最大化系统吞吐量,满足词元间时延(TBT)的 SLO,并确保 KV Cache 总量不超过 GPU 显存限制。
-
第二,将 KV Cache 与计算单元分离。Mooncake 将计算集群中的 GPU、CPU、DRAM、SSD 和 RDMA 资源整合为分布式 KV Cache 池,采用分页式块管理方式来组织 KV Cache。KV Cache 块在该池中的 调度策略与复用机制 是 Mooncake 设计的核心所在。
遵循论文的阐述,我们结合下图 Figure 4 来了解一下 Mooncake 处理一个请求的流程:
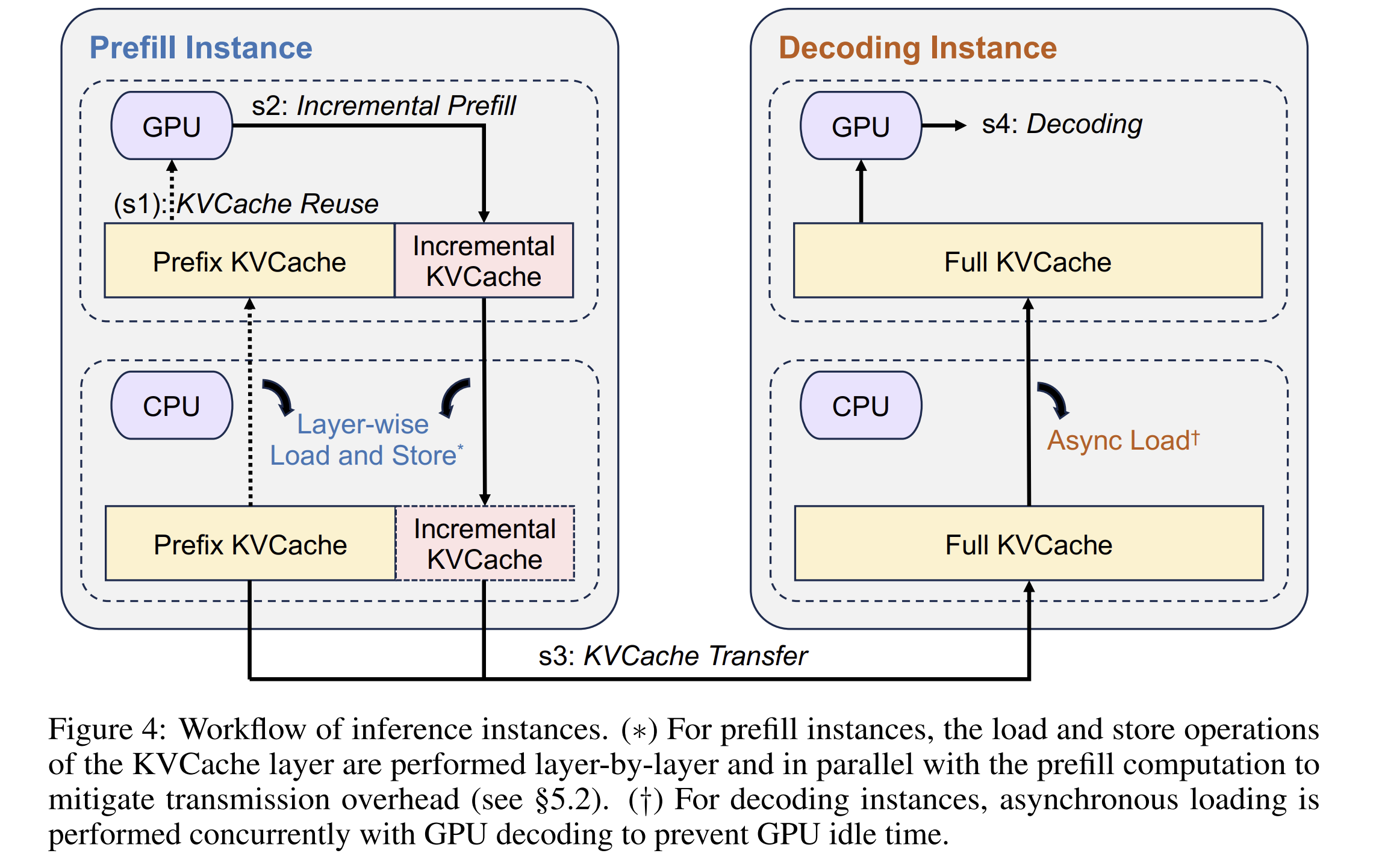
当一个请求(经 Tokenization 后)到达时,调度器会为其选择一对 P 实例与 D 实例。这两个实例均需持有模型参数的副本,并启动一个包含四个步骤的工作流:
-
步骤一:KV Cache 复用。P 实例会将请求划分为多个词元块。考虑到请求间可能存在的共同前缀,系统会尽可能将词元块调度至拥有最长前缀 KV Cache 的节点进行处理,以实现 KV Cache 的复用。为此,Mooncake 提出了一种以 KV Cache 为中心的调度策略。
-
步骤二:增量 Prefilling。利用前缀缓存(Prefix Cache),P 实例仅需计算前缀缓存未命中的 Tokens 部分。对于长序列的计算,系统通过多卡并行处理,并采用 TeraPipe 流水线并行方式(基于 Token-level 的 Pipeline 并行模式)。
-
步骤三:KV Cache 传输。与 Splitwise、DistServe 等分离式架构设计一致,需要将生成的 KV Cache 从 P 实例传输至 D 实例。Mooncake 实际采用异步传输方式,将此过程与上述增量 Prefilling 步骤重叠执行,将每个模型层产生的 KV Cache 流式传输至目标 D 实例的 CPU 内存中,旨在降低传输时延。
-
步骤四:解码。当 D 实例的 CPU DRAM 完成接收所有 KV Cache 后,该请求即进入 GPU 上的持续批处理(Continuous Batching)流程进行解码。
PD 分离主要优化的是 TBT,对 TTFT 并无提升,但实现了换取系统整体服务能力和稳定性的显著提升。该分离机制的核心在于请求(Requests)调度与 KV Cache 传输的高效协同。实际调度中不能仅考虑负载均衡,还需综合权衡实际 KV Cache 复用率与显存剩余空间等因素。
在大模型的大规模部署场景下,PD 分离将是较为复杂的分布式系统方案。在工业界,华为昇腾提出 AutoPD 分离方法,智能调配 Prefilling/Decoding 计算资源。另外,目前主流的开源大语言模型推理引擎和框架也在积极探索 PD 分离方案,其中包括 vLLM、SGLang、Dynamo 和 LLM-d 等。
四、总结与展望
本文主要内容:
-
本文首先明确大语言模型推理系统的关键性能指标,继而剖析预填充(Prefilling)与解码(Decoding)这两个阶段的核心特征,并通过举一个生活中的例子以帮助读者更好地理解 PD 分离。
-
基于上述分析,本文指出:持续批处理(Continuous Batching)采用阶段隔离与抢占机制,虽有助于提高系统吞吐量并降低生成首个词元的时延(Time To First Token,TTFT),但会显著增加词元间时延(Token Between Token,TBT),进而对端到端(End-to-End,E2E)时延造成不利影响。
-
最后,本文简要回顾了预填充与解码相分离(Prefilling-Decoding Disaggregation,PD 分离)方面的已有研究工作。PD 分离技术将大语言模型推理过程划分为两个独立阶段,并针对各阶段的计算特性实施针对性优化,从而显著提升推理效率与资源利用率。该架构的引入已为大语言模型的高效部署与实际应用开辟新的技术路径。未来,随着昇腾 AI 处理器在更多场景中的应用,PD 分离技术将进一步释放大模型的潜力,为各行业带来更智能化、高效的 AI 体验。
需要指出的是,解耦并非总是最优方案;尽管前景广阔,但 PD 分离并非适用于所有场景:
-
性能阈值至关重要:当工作负载规模较小或 AI 加速器配置未针对该方法优化时,性能可能不升反降。在实际 PD 分离架构中,Prefilling Server 的带宽利用率与 Decoding Server 的算力利用率通常较低。该架构适用于批处理规模较大、且输入与输出序列均较长的应用场景。对于常规应用场景,不建议采用此方案。在满足性能要求的前提下,应优先采用单机部署而非多机部署。
-
本地 Prefilling 更具优势:对于短提示或 Decoding 引擎前缀缓存命中率较高的情况,在 Decoding 节点本地执行 Prefilling 通常更快速且实现更简单。
-
数据传输成本:PD 分离要求 P 与 D 节点间高效可靠地传输 KV Cache。因此,实施方案需支持快速、低时延的通信协议,并具备硬件与网络无关性。若数据传输开销超过解耦带来的性能收益,整体性能将受损。现有传输技术示例如下:华为 HIXL(Huawei Inference Xfer Library)、NVIDIA Inference Xfer Library(NIXL)、CXL(Compute eXpress Link)、NVMe-oF(NVMe over Fabrics)。
📚️ 参考资料链接整理如下:
更多推荐


 38
38 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)