
王耀南院士团队 | AI大模型驱动的具身智能人形机器人技术与展望
王耀南院士团队探讨了AI大模型驱动的具身智能人形机器人技术的发展与展望。文章首先回顾了人形机器人的发展历程,从机械自动化到人工智能集成,强调了人形机器人在社会、经济和军事领域的重要性。随着大模型技术的进步,人形机器人在语言理解、视觉泛化和常识推理等方面取得了显著进展。文章还分析了国内外政策背景,指出各国政府对人形机器人技术的高度重视和投资。最后,文章探讨了通用大模型技术在人形机器人中的核心作用,特
王耀南院士团队 | AI大模型驱动的具身智能人形机器人技术与展望
1 人形机器人智能化技术发展背景与意义人形机器人是 “人工智能+机器人” 的产物, 是多学科交叉融合的集大成者. 它的出现是现代科技革新的显著标志, 对全球的经济、社会乃至军事领域产生了深远的影响. 通过与深度学习、机器学习等技术的融合, 机器人技术实现从自动化向智能化的飞跃, 赋予了机器人执行复杂任务、自主决策以及适应不断变化环境的能力. 近年来, 大模型技术的迅猛发展, 赋予了人形机器人语言理解、视觉泛化、常识推理等关键能力, 进一步促进人形机器人技术的发展与应用. 接下来, 本文将探讨智能机器人与人形机器人发展历程、人形机器人发展背景及其深远意义.1.1 智能机器人与人形机器人发展历程机器人, 根据国际标准化组织的定义, 是一种自动的、位置可控的、具备编程能力的多功能机械臂. 这种机械臂拥有多个轴, 能够通过编程操作处理各种材料、零件、工具以及专用装置, 以执行多样化的任务. 随着人工智能、大数据、传感器等智能技术的逐步融入, 智能机器人在传统机器人功能的基础上, 进一步增强了感知与自主学习能力, 能够适应更加复杂多变的环境和任务需求. 如图 1所示, 机器人发展历程可分为机械自动化、可编程控制、系统控制和人工智能集成4个阶段.从20世纪40年代到60年代, 机器人处于机械自动化阶段, 依靠机械设计和简单的控制逻辑, 通常用于执行重复性任务. 在20世纪60年代至80年代, 机器人进入了可编程阶段, 开始具备编程能力, 能够根据预设程序执行特定任务, 并具备了基础的环境感知能力. 从20世纪80年代至2015年, 随着伺服系统、传感器和人工智能技术的持续进步, 机器人的自主学习能力得到了显著提升, 能够在各种复杂环境中执行精确任务. 2015年被视为智能机器人的元年. 随着人工智能技术, 尤其是深度学习和大型模型技术的迅猛发展, 机器人在感知和决策能力上实现了重大突破, 并在自主学习与任务执行能力上达到了新的水平. 到2020年以后, 随着Transformer架构和大型语言模型的广泛运用, 智能机器人不再局限于执行预设任务, 它们还能进行复杂任务的推理和自我优化.人形机器人之所以受到广泛关注, 首先是因为其接近于人类外观的设计不仅有助于机器人更好地融入人类社会, 还能在心理层面拉近人机之间的距离. 更重要的是, 人形结构赋予了机器人执行复杂任务的能力, 比如行走、抓取物体甚至是进行简单的社交互动, 这些都是传统机器人难以实现的功能. 人形机器人发展历程相对较晚. 在20世纪70年代, 人形机器人研究才初露端倪, 早期相关研究主要集中在手部的简单运动和行走控制模型上, 人形机器人也尚未拥有交互能力, 智能化程度相对较低. 1973年, 日本早稻田大学(Waseda University)的加藤一郎教授成功研发了世界上首款人形机器人—— WABOT-1, 它标志着人形机器人概念的诞生. 进入21世纪, 2000年, 丰田公司推出了ASIMO机器人, 它不仅能够流畅地行走和奔跑, 还能执行简单的任务并进行人机交互, 这标志着人形机器人技术取得了重大突破. 随着21世纪人工智能、机器学习、感知系统及交互系统等技术的迅猛发展, 人形机器人逐渐获得了更高级的感知和决策能力. 它们不仅在运动性能上表现出色, 还能够执行一些较为复杂的人机交互任务, 这标志着人形机器人进入了高度集成的发展阶段. 2013年, 美国波士顿动力公司(Boston Dynamics)推出的双足机器人Altas, 展现了卓越的灵活性和稳定性, 其应用领域主要涵盖救灾、物流及服务行业. 2015年, 日本软银集团(SoftBank)发布了人形社交机器人“Pepper", 该机器人能够识别面部表情和声音, 并与人类进行基本的互动交流. 进入2020年后, 随着大模型技术的兴起, 以及自然语言处理和计算机视觉等技术的不断进步, 人形机器人的外部环境认知和感知能力得到了显著提升, 能够进行自主决策, 并完成更为复杂的任务和人机交互. 至2023年, 特斯拉(Tesla)推出的Optimus Gen2人形机器人, 展现了更为强大的理解、判断和自我评估能力, 能够执行更为灵活的任务.大模型技术的应用, 显著提升了人形机器人的智能化水平, 使其不仅能够完成复杂的任务, 还能够在无人监督的条件下自主学习和优化其行为. 特别是在人形机器人理解自然语言、处理视觉和语音信息, 以及进行复杂任务推理方面, 大模型技术提供了强大的计算与推理支持. 具身智能机器人已不再是简单的工具, 而是能够与人类协作, 甚至独立完成任务的智能实体, 其应用范围已经扩展至服务业、教育、医疗等领域.1.2 人形机器人国内外政策背景与意义在国际背景下, 各国政府认识到人形机器人技术智能化的深远影响, 纷纷采取行动来促进这一领域的进步. 美国作为机器人技术的先锋国家, 早在2011年便发布了“美国国家机器人计划(NRI)“, 旨在推动人形机器人在医疗、教育、服务等领域的应用, 探索其在各种社会角色中的潜力. 该计划强调人形机器与人类之间的协作, 鼓励开发能够在家庭、工作和社会环境中有效与人类互动的机器人. 此后, 美国政府通过“国家机器人计划2.0"和“国家人工智能战略"继续推动人形机器人与人工智能的结合, 确保美国在全球高科技领域中的领导地位. 日本政府于2015年发布了“机器人战略”, 鼓励研发更先进的机器人技术, 特别是在人工智能、机器学习和自动化等领域的应用. 该战略强调机器人在医疗、护理和老龄化社会中的重要性, 推动人形机器人在照顾老年人和残疾人方面的应用. 2021年欧盟通过“欧洲地平线计划", 明确了机器人技术和智能系统的研究重点. 该计划不仅关注机器人技术的前沿创新, 还致力于推动机器人在医疗、交通和服务领域的广泛应用, 以应对人口老龄化和经济转型带来的挑战.在国家层面, 我国近年来显著增加了对人形机器人智能化技术的投资和研发. 《中国制造2025》战略和《新一代人工智能发展规划》均明确提出了提高机器人智能化水平的关键目标. 2023年, 中华人民共和国工业和信息化部发布的《人形机器人创新发展指导意见》强调了加速解决技术积累不足、产业基础薄弱、高端供给短缺等问题的重要性, 旨在推动人形机器人技术创新能力的显著提升, 并构建安全可靠的产业链供应链体系, 以形成具有国际竞争力的产业生态. 国内科技巨头,如百度、阿里巴巴、华为等, 在人工智能技术领域取得了重大突破, 并开始将这些技术应用于人形机器人领域. 中国智能制造业和服务业越来越依赖于机器人技术的进步, 这促进了工业生产效率的提升和服务业的智能化升级. 此外, 我国在人形机器人领域的专利申请和学术研究数量也呈现出快速增长的态势, 这标志着我国正从人形机器人技术的“追赶者"转变为“领跑者". 综上所述, 人形机器人技术受到世界主要国家的高度重视, 相关政策背景详见图 2.2 通用大模型与具身智能人形机器人的核心关键技术2.1 通用基础大模型技术大模型, 通常指具有庞大参数规模和复杂计算结构的深度学习模型, 它们包含数十亿甚至数千亿个参数. 得益于其巨大的参数规模和复杂的计算架构, 大模型能够学习和表达更为复杂的数据模式和特征, 展现出强大的特征表达能力和预测性能, 能够处理更加复杂的任务. 大模型在自然语言处理、计算机视觉、语音识别等众多领域中得到了广泛应用. 在具身智能人形机器人作业推理过程中, 大模型同样也扮演着核心角色, 它能够将复杂任务分解为多个子任务, 并利用多模态输入进行有效推理, 从而提升人形机器人的具身智能水平.2.1.1 大型自然语言模型技术大型语言模型(large language model, LLM)是专门用于理解与生成自然语言的人工智能模型, 通常采用如 Transformer 等深度学习架构 [1], 并在海量文本数据上进行训练, 展现出卓越的语言处理能力. LLM 的显著特点之一是其巨大的参数规模, 当前模型的参数数量范围从数十亿到数万亿不等, 这使得它们能够应对极其庞大的数据集并执行复杂任务. 因此, LLM 在各种自然语言处理(natural language processing, NLP)任务中表现出色.在语言模型的发展历程中, 先后采用前馈神经网络、循环神经网络、卷积神经网络以及记忆网络等结构来建模词汇之间的条件概率分布, 从而有效地捕捉词汇间的长序列依赖关系 [2,3]. BERT (bidirectional encoder representations from transformers)语言模型 [4]使用双向Transformer架构, 并设计了掩码语言模型和下一句预测等自监督学习任务来进行预训练, 大幅提升了在多项自然语言处理任务中的表现. 现有语言大模型结构, 主要以Transformer模型作为基础架构来构建. 不过从建模策略的角度, 它们在具体采用结构上通常存在一定差异. 如图 3所示, 语言大模型架构大致可以分为三类: 掩码语言建模、自回归语言建模和序列到序列建模. 例如, 2022年, OpenAI发布了GPT-3 (generative pre-trained transformer 3)模型 [5], 这是一种序列到序列模型, 能够在处理长序列数据时避免传统的循环神经网络(recurrent neural network, RNN)中存在的梯度消失问题, 该模型采用了更大规模的参数进行预训练, 并将上下文长度扩展至2048个词元(Token), 其能够胜任多种自然语言理解与生成任务, 如自动问答、文本分类、文本摘要、机器翻译和对话系统等. 同时, 它在少样本和零样本学习情境下表现出了与传统监督学习相媲美的性能, 展现出较强的泛化能力 [6], 并在多个自然语言处理基准任务中刷新了纪录. 随后, 2023年, OpenAI 推出GPT-4 (generative pre-trained transformer 4)模型, 增强语言上下文处理能力, 并具备多模态理解能力, 能够识别和处理图像信息, 进行数学推理和编程等.这些自然语言大模型的强大性能很大程度上依赖于深度学习技术的进步, 尤其是Transformer架构的应用, 这标志着语言模型发展进入了新的阶段 [7]. Transformer架构还能同时处理多序列输入, 极大地提升了大规模语料库上的训练效率 [1], 并通过引入链式思维(chain-of-thought, CoT) [8]、思维树(tree-of-thoughts, ToT) [9] 等提示技术, 大语言模型的逻辑推理能力得到显著提升, 使其有望解决复杂的具身智能任务中的分解与推理问题. 如图 4所示, 这是一种典型LLM模型架构, 由Mate AI提出来LLaMA [10] 和Llama 2 [11], 一种经过预训练和微调的LLM模型, 模型参数规模高达 70B (billion) 个参数. 此外, 国产大语言模型也相继推出, 百度的文心大模型、阿里的通义千问大模型、腾讯的混元大模型、科大讯飞的星火认知大模型等, 这些模型在中文理解方面具有更强的能力.综上, 自然语言大模型技术的发展可以赋予机器人强大的语言理解和生成能力, 使其能够流畅地与人类进行交流, 执行语言指令, 并从大量文本中快速检索和推理信息等.2.1.2 视觉Transformer模型技术Transformer模型是一种基于自注意力机制的架构, 在建模全局上下文时展现出强大的能力, 并在大规模预训练下对各类下游任务表现出出色的可迁移性. 这种成功在机器翻译和NLP领域得到了广泛认可. 受Transformer模型在语言任务中的成功启发, 近期有多项研究将其应用于计算机视觉任务. Parmar等 [12]基于Transformer解码器的自回归序列生成或转换问题, 提出了Image Transformer模型用于图像生成. Carion等 [13]基于Transformer提出了detection transformer (DETR), 一种端到端目标检测方法, 其性能达到了与Faster R-CNN [14]相当的水准. 如图 5所示, Dosovitskiy等 [15]提出了vision transformer (ViT)模型, 一种典型的视觉Transformer网络模型架构. 通过将图像按局部块状补丁分割为序列化的Token, 并将这些Token输入ViT模型中, 经过Transformer编码特征提取后用于目标识别分类. 基于ViT的网络模型在多个图像识别基准任务中取得了当前最先进的效果, 性能上优于卷积神经网络和递归神经网络等其他类型的网络. 研究人员将视觉Transformer模型广泛应用于多个领域, 涵盖目标检测 [16,17]、图像分割 [18]、文字提取 [19]、图像生成 [20]、文本图像合成 [21]、视频理解 [22]和自动驾驶 [23]等多个领域.随着研究的深入, 不同视觉Transformer改进方法相继被提出, 包括训练策略的优化、Token生成方式的改进等. 例如, Touvron等 [24]提出DeiT (data-efficient image transformers)模型, 通过将知识蒸馏技术引入ViT的训练过程中, 将已训练好的卷积神经网络(如ResNet [25])作为教师模型, 指导Transformer模型的训练, 并提出多种图像预处理方法, 使得视觉Transformer在小数据集上也能取得良好表现. Jiang等 [26]提出LV-ViT模型, 一种新的训练计算损失函数, 训练时不仅仅依赖Class Token的结果, 而是将所有Token的贡献纳入考虑, 将图像分类问题转化为识别图像中每个Token的问题, 大幅提升了视觉Transformer的图像分类精度.综上, 视觉Transformer大模型, 是智能机器人技术的一个重要研究方向. 视觉Transformer模型技术能够提升智能机器人的视觉感知能力, 使其更精准地识别物体、理解场景, 并通过全局特征提取在复杂的环境中作出更有效的决策.2.1.3 视觉–语言大模型技术视觉–语言模型(visual language model, VLM)结合视觉基础模型与大语言模型, 能够同时处理图像和语言输入, 并基于视觉信息和语言指令生成输出, 执行图像问答任务. 其核心在于其出色的多模态学习能力. 视觉模型侧重于图像识别、分类等任务, 自然语言处理模型则专注于文本生成与理解. 通过结合两者的优势, 实现图像与文本数据的跨模态理解与生成. VLM包含3个关键组成部分: 视觉编码器将图像数据转换为高维特征向量表示; 语言解码器基于视觉嵌入生成对应的自然语言描述或指令; 跨模态融合模块则整合视觉和语言嵌入, 提升模型对多模态数据的理解.近年来, 多模态大模型以语言大模型为核心逐步发展. 其中, DeepMind 的 Flamingo [27]视觉语言模型是一个典型代表. 该模型能够将图像、视频和文本作为输入提示, 并生成相关的语言输出. 它通过可学习的融合模块连接视觉编码器与冻结参数的语言大模型, 具备少样本多模态序列推理能力, 能够无需额外训练执行视觉语义描述、视觉问答等任务. 另一个典型模型是KOSMOS-1 [28], 该模型使用基于Transformer的语言模型作为通用接口, 与视觉感知模块结合, 从而赋予模型“能看"和“会说"的能力. KOSMOS-1 拥有 16 亿参数, 并在大规模多模态语料库上进行训练, 具备零样本学习与少样本学习能力, 能够处理视觉对话、视觉问答、图像描述生成及光学字符识别等多种任务. Wang等 [29]提出SimVLM (simple visual language model)模型, 将图像和文本输入到编码器, 并从解码器生成后续文本或回答. Li等 [30]提出BLIP2 (bootstrapping language-image pre-training 2)模型, 通过将 QFormer [31] 结构从冻结的编码器中提取视觉特征, 其将多模态信息匹配预训练, 从而对齐视觉与文本表征. 提取的特征经过线性投影后, 与语言指令共同作为大语言模型的输入. BLIP模型架构如图6所示. MiniGPT-4 [32] 等在模型结构、预训练任务及语言基础模型等方面进一步提升了 VLM的理解与推理能力. Video-ChatGPT [33], VideoLLaMA [34], Timechat [35], Moviechat [36]等模型将图像输入扩展为视频输入, 使大模型能够基于语言指令和视频进行问答. 然而, 鉴于视频信息的复杂性, 视觉–语言大模型在处理长序列视频时仍面临诸多挑战, 通过改进视频数据时间动态捕捉、幻觉问题, 优化模型架构, 提升训练数据的质量与规模等方面, 提高视觉–语言大模型性能.综上, 视觉–语言大模型能够通过结合图像和语言信息, 使机器人能够理解视觉场景与语言描述的关系, 支持图像描述生成、视觉引导下的任务执行, 并在跨模态信息推理中表现出色.2.1.4 视觉生成大模型技术视觉生成模型能够基于给定输入数据生成视觉内容, 如图像或视频. 这些模型通常使用深度学习技术, 如生成对抗网络(generative adversarial networks, GANs) [37]、变分自编码器(variational autoencoder, VAE) [38]等. 扩散模型(diffusion models)作为一种重要的图像生成方法 [39], 在生成高质量图像方面表现优异, 超越了传统的自编码器、显式概率模型网络和生成对抗网络. 扩散模型已在多个领域中得到应用, 如可控图像生成 [40]、图像目标生成 [41]、轨迹生成 [42]以及文本到图像生成 [43], 并成功用于DALL-E [44]等图像和视频生成任务中. 视觉生成大模型的发展历程如图 7所示.在序列生成模型中, DALL-E 是一个典型的案例. 由 OpenAI 推出, 该模型基于 4 亿对图文数据进行训练, 通过采用向量量化变分自动编码器(vector quantized variational autoencoder, VQVAE [45]) 与 GPT 结合的架构, 在文本生成图像的任务上取得了显著的生成质量和泛化能力, 被誉为 “图像版 GPT". 另一个具有代表性的图像生成模型是北京智源研究院的 CogView [46], 其结构与 DALL-E 相似, 但专注于中文环境的文本到图像生成, 并进一步研究了多模态生成模型在经过下游任务精调后的泛化能力, 和基于文本描述生成高质量图像的能力. 典型模型还有Video-LaVIT [47], 通过自回归预测下一个图像或文本词元, 在统一生成目标的框架下同时处理图像和文本.综上, 视觉生成模型帮助智能机器人生成逼真的图像、视频或三维场景, 增强其场景模拟和预测能力, 尤其在强化学习和人机交互中, 通过虚拟环境的构建和视觉修复提升机器人的操作效率.2.1.5 具身智能多模态大模型技术具身智能是指智能系统通过物理实体与环境交互, 促进智能发展的过程. 此类系统具备环境感知、信息认知、自主决策和行动能力, 并能够通过经验反馈实现智能进化和行为适应. 当系统能够处理多模态信息时, 被称为多模态具身智能. 多模态大模型通过结合文本、语音、图像和视频等不同形式的数据进行综合学习. 这种模型整合了多样的感知方式和表达形式, 能够同时分析并理解来自视觉、听觉、语言和触觉等多种感官通道的数据, 并以多模态的形式进行信息的表达和输出. 如图 8所示, 这是一种典型的多模态生成式大模型架构, 通过输入文本、语音、图像和视频等多模态数据, 利用大语言模型挖掘不同模态间的特征范式, 并生成输出多模态信息.具身智能多模态大模型旨在使智能体能够在物理世界中进行感知、认知及环境互动, 并具备自主学习和决策的能力. 多模态大模型的另一突破在于视频理解与生成, 如 VideoGPT [48] 和 Perceiver IO [49], 前者利用视觉生成模型来处理视频序列数据, 实现视频生成与编辑, 后者则通过多模态信息融合, 增强大模型在复杂任务中的泛化能力. 它们为自动视频生成、视频摘要, 以及视频问答等任务提供了新方法. 多流结构的典型模型如ViLBERT [50], 通过融合文本和图像特征, 应用于视觉问答和图像描述生成等多模态任务. VATT [51]针对视频、文本和音频数据, 将各模态线性投影为特征向量后分别送入Transformer编码器, 并通过对比学习进行训练. ChatBridge [52]等模型则尝试将图像、视频等感知模块与开源语言大模型LLaMA [10]结合, 达到类似GPT-4的多模态理解效果. 通过将知识图谱、场景图及外部知识库等结构化知识注入大模型, 可提升多模态模型的知识利用能力, 例如百度的ERNIE-ViL [53]模型.视觉–语言–动作(vision-language-action, VLA)模型 [54]是一类处理多模态输入的模型, 旨在结合视觉、语言和动作信息, 主要用于解决具身智能中的指令跟随任务. 其涉及对物理实体的控制及与环境的互动, 尤其在机器人领域表现突出. 机器人在执行语言驱动的任务时, 需要理解指令、感知环境并生成适当的动作, 这使得VLA的多模态能力变得至关重要. 相比于早期的深度强化学习方法, 基于VLA的策略在复杂环境中展现出更高的多样性、灵活性和泛化能力, 适用于工厂等受控环境以及日常生活中的任务 [55]. VLA模型依赖于高效的视觉编码器、语言编码器和动作解码器, 以便输出机器人动作来完成具身任务. 一些VLA优先获取高质量的视觉预训练表征 [56-59], 另一些则致力于改进低级控制策略 [60-62], 善于处理短期任务并生成可执行的动作. 此外, 某些VLA专注于将长期任务分解为低级控制策略可以执行的子任务, 因此可以将低级控制策略与高级任务规划器结合 [63-65], 形成一种分层策略. 此外, 具身模拟器在具身智能研究中发挥着重要作用, 因其提供了成本效益高的实验方式, 能够模拟潜在危险场景以保障安全. 它们支持在多种环境中测试, 具备可扩展性, 且能够快速原型制作, 服务于更广泛的研究群体. 此外, 模拟器为精确研究提供了受控环境, 有助于生成和评估数据, 并为算法比较提供标准化基准. 为了实现agent与环境的有效交互, 需构建逼真的模拟环境, 这包括考虑环境的物理特性、物体属性及其相互作用. 模拟平台主要分为两类: 基于底层模拟的通用模拟器与基于真实场景的模拟器.综上, 具身智能多模态大模型, 通过结合视觉、语言、触觉等多种感知, 赋予机器人在环境中自主学习和决策的能力, 帮助其在复杂任务中进行多模态信息融合和实时响应, 提高与人类的互动和协作效率.2.2 大模型驱动的人形机器人关键技术机器人技术的核心包括感知、规划、控制和决策等关键技术, 它们共同确保机器人能在复杂环境中高效地完成任务. (1) 视觉感知技术: 作为机器人系统的关键部分, 视觉感知利用视觉传感器捕捉周围环境的真实空间信息, 并通过预处理、配准融合以及空间场景表面生成等步骤, 实现对外界环境的精确描绘和数字模型的重建. 关键技术涵盖双目三维环境感知、3D点云配准、位姿估计算法等, 这些技术为机器人在工业制造中提供丰富的二维和三维信息. (2) 机器人运动规划技术: 运动规划技术负责生成符合任务需求的轨迹和路径规划, 以实现高效的运动控制. 控制系统则负责对机器人的动作和状态进行精确控制, 确保其稳定性和安全性. (3) 机器人控制关键技术: 这包括精准执行控制和运动控制. 精准执行确保机器人在作业过程中对预设加工轨迹保持高精度跟踪, 并对各种扰动具有鲁棒性, 以保证加工的一致性. 运动控制技术则实现机器人的准确运动和姿态调整, 涵盖轨迹规划、运动学和动力学控制等方面. (4) 机器人决策技术: 涉及机器学习和深度学习, 使机器人能够从数据中学习和提取特征, 提升其智能水平和决策能力. 深度学习通过构建深层神经网络模型, 能够自动从大规模数据中学习和提取特征, 实现对复杂任务的高效处理和决策. 这些技术使机器人能够在各种环境中自主导航, 完成复杂任务, 是现代机器人技术发展的重要方向.近年来, 随着大模型技术的不断进步, 一系列关键能力, 诸如语言理解、视觉泛化以及常识推理等, 被成功地注入至机器人的感知控制系统中. 特别是在人形机器人领域, 大模型技术的引入不仅显著提升了人形机器人的智能化程度, 而且为其在复杂多变的环境中进行自主控制与操作作业奠定了坚实的基础, 从而极大地推动了人形机器人技术及其应用的新一轮发展. 展望未来, 人形机器人有望在智能制造、无人系统、家庭服务、医疗护理等多个领域发挥更加重要的作用. 接下来, 本文将从3个维度深入阐述5种AI 基础大模型所驱动的人形机器人关键技术, 详细技术路线图如图9所示.2.2.1 分布式模块化大模型技术分布式模块化大模型技术通常应用于智能人形机器人相对比较单一的、模块化的任务中, 比如人形机器人单一任务的感知、规划、决策、控制等.(1) 智能人形机器人感知大模型技术. 在通用智能机器人感知方面, 现有的大模型技术主要研究可以分为分割一切、定位一切、动作识别一切、重建一切、感知一切等大模型技术. 在基于大模型技术的分割任务方面 [66-70], Meta AI 发布首个分割一切(segment anything model, SAM [66])大模型, 可以一键“剪切"任何图像中的任何对象, 这是一种可提示的分割系统, 对不熟悉的对象和图像进行零样本泛化, 无需额外训练. 根据点或框等输入提示生成高质量的对象遮罩, 可用于为图像中的所有对象生成分割掩膜. 随后, Meta AI团队发表了Segment Anything2 [70], 准确性与处理速度得到了提高, 同时支持视频对象分割. 在基于大模型技术的定位方面, Ma等 [71]提出一种名为Groma的多模态大语言模型(multimodal large language model, MLLM), 旨在提高现有MLLM在定位和细粒度视觉感知能力等方面的不足, 从而解决无法将理解深入到视觉感知任务上下文中的问题, 同时为了增强Groma的定位聊天能力, 作者利用强大的GPT-4V模型和视觉提示技术, 策划了一个视觉定位指令数据集. 在视频动作识别领域, Wang等 [72]设计了一种新颖的视觉TED-Adapter, 它通过进行全局时间增强和局部时间差异建模, 来提升视觉编码器的时间表征能力. 此外, 还采用了文本编码器适配器, 以加强语义标签信息的学习, 设计一个具有丰富监督信号集的多任务解码器, 巧妙地满足了在多模态框架内实现动作识别一切的强监督性能和泛化需求. 在通用目标识别领域, 智源研究院视觉团队Pan等 [73]推出一种感知一切基础模型 (tokenize anything via prompting, TAP), 一种以视觉感知为中心的基础模型, 利用视觉提示同时完成任意区域的分割、识别与描述任务. 将分割一切SAM模型升级为感知一切TAP模型, 高效地在单一视觉模型中实现对任意区域的空间理解和语义理解. Shen等 [74]提出一种通用的视觉感知模型, 用于一次性在图像中对齐和提示所有内容, 以执行各种任务, 即检测、分割和定位, 作为一种实例级句子–对象匹配范式, 通过将语言引导的定位重新构想为开放词将模型提示扩展到数千个类别词汇和区域描述, 同时保持跨模态融合的有效性.在人形机器人感知大模型技术方面, 大模型技术主要用于增加人形机器人的人机交互能力, 如语音对话、手势识别、简单动作表达. 例如, Zhang 等 [75] 提出一种基于大模型的自主意识人形机器人(autonomous conscious humanoid robot, ACHR)架构, 通过设计一种基于大模型和生成智能技术的环境感知系统, 实现自主意识人形机器人的环境感知. Antikatzidis等 [76]提出一种基于大语言模型的AI聊天人形机器人, 通过利用云边端协同的策略, 部署相应的Python API访问云端的大型语言模型, 提升人形聊天机器人交流能力. Sievers等 [77] 开发一种基于大语言模型(LLM)的人形服务机器人, 通过利用大语言模型, 使机器人应该识别人类情绪, 并做成相应情绪反应. Bottega等 [78]开发一种开源的模拟类人机器人, Jubileo, 通过利用预训练大型语言模型, 提升人形机器人在动态交互式的虚拟环境中的语言交流能力. Lim等 [79]提出一种基于大型语言模型(LLM)的人形机器人交互方法. 通过部署一种手势识别小模型, 识别人机交互时人的动作手势, 结合大型语言模型, 增强人类和机器人之间的非语言互动能力. Kawaharazuka等 [80]提出一种基于预训练视觉–语言大模型的人形机器人环境感知方法, 通过视觉–语言模型对周围环境进行状态识别、物体识别、功能识别和异常检测等, 从而使人形机器人做出相应的动作反应. 如图 10所示, 这是一种用于人形机器人环境感知的视觉感知与定位多模态大模型, 能够帮助人形机器人实现对任意场景空间的目标语义理解.综上, 人形机器人通过多传感器, 如视觉、语言、雷达等传感器, 获取作业环境中的数据, 利用预训练多模态大模型处理环境感知数据, 实现作业环境的感知理解与认知, 可以通过手势、声音等进行人机交互. 大模型技术的不断发展可以为人形机器人系统注入环境感知与认知、情绪表达与交互等关键能力, 进一步推动人形机器人的发展.(2) 智能人形机器人规划大模型技术. 在智能机器人规划方面, 现有的大模型技术主要研究介绍如下. Xu等 [81]提出一种基于大语言模型(LLM)的自我引导进化(env-guided self-training)机器人操作轨迹规划新范式, 通过在无人类标注、不引入Strong LLM的情况下, 在与环境交互过程中, 实现机器人操作轨迹的自我训练与自我进化. Huang等 [82]提出一种基于大语言模型与视觉模型的模块化机器人操作轨迹规划方法, VoxPoser, 从LLM中提取语言为条件的可见性约束, 通过代码接口并且无需对任何一方进行额外训练, 用VLM模型部署空间感知, 可以通过一组开放的指令和一组开放的目标实现各种日常操作任务的零样本轨迹规划. Ahn等 [63] 提出一种名为SayCan的机器人任务规划大模型, 将大模型任务拆解能力与机器人实际可执行任务二者结合起来进行机器人规划和控制, Say代表大模型LLM, 用于输出操作规划可用的高层级运动指令, Can代表机器人在当前环境下能做的事情, 二者通过值函数(value function)的方式结合起来, 规划决定选择哪条指令用于实际执行.在人形机器人的智能规划领域, 当前的研究主要聚焦于利用强化学习和模仿学习来指导它们在执行多任务操作时的决策制定. 但是, 这些方法往往需要为特定任务构建模拟环境和设计奖励机制, 这导致了多种策略的产生, 并且在应对复杂或未知任务时显得能力有限. 因此, Sun 等研究者 [83] 提出了一种基于LLM的策略规划器, 它通过特定任务的策略提示, 使机器人在执行操作任务时能够学习并掌握解决新任务的技能. Li等 [84] 提出了一种基于大模型的人形机器人灵巧抓取策略生成方法, 该方法通过多模态大模型来实现对目标的感知、识别、估计以及抓取策略的生成. Kumar等 [85]提出一种基于大型语言模型的人形机器人规划方法, 使用自然语言命令来迭代优化人形机器人的动作行为规划, 并通过持续的训练和微调来提升机器人的控制策略. 如图11所示,这是一种较为典型的大模型驱动人形机器人自我引导作业轨迹规划技术路线图.综上, 大模型技术在人形机器人规划领域的应用, 往往结合具体的作业任务, 通过获取作业环境感知数据, 利用多模态大模型技术进行认知规划、常识推理等. 人形机器人作业任务的规划往往伴随着任务的决策与控制执行.(3) 智能人形机器人决策大模型技术. 在通用智能机器人决策方面, 现有的大模型技术主要研究介绍如下. 在复杂的任务推理和决策领域, Li等 [86]提出一种预训练语言模型(pre-trained language models, PLMs), 利用大语言模型实现观察目标与观察行为建模, 将目标与其行为作为嵌入序列, 利用先期训练的大语言模型来预测输出行为决策. Shah等 [87]提出一种用于机器人导航的决策大模型系统, 通过将语言、视觉和行动模型结合起来, 利用高级自然语言命令指导机器人导航. 利用预训练的视觉导航、图像–语言相关性和语言理解多模态模型, 减少了对昂贵的轨迹标注监督的依赖, 提升实现复杂任务决策推理能力. 这种能力对于遵循高级任务指令和增强模型在现实世界场景中的适用性至关重要. Huang等 [88]开发了一个用户友好的、通用的机器人决策系统, Instruct2Act. 该系统使用LLM将多模态命令转换为机器人领域的动作序列. 该系统使用LLM生成的决策控制代码, 这些代码对各种视觉基础模型进行API调用, 从而获得对任务集的视觉理解. 此外, Zeng等 [89]提出一种多个大模型协同决策的策略, Socratic模型, 其中多个大型预训练模型之间的结构化对话促进了对新多模态任务的联合协同决策, 可以多个任务中零样本的任务决策. 这些研究表明大模型技术在处理复杂任务、进行逻辑推理、做出明智决策和参与互动学习方面展现出巨大能力.在面向人形机器人决策大模型技术方面, 大模型技术主要用于人形机器人复杂任务的决策和技能学习与决策等. 例如, Wang等 [90]提出一种大语言模型的人形机器人运动规划与推理方法. 通过学习非结构化不同场景中的任务、选择和规划行为, 并结合强化学习与人形机器人全身关节优化, 来创建一个学习技能运动库, 最后结合大语言模型来生成复杂操作行为的规划策略. Ryu 等 [91]提出一种基于课程学习的大语言模型(curricula large language model, CurricuLLM), 可以帮助人形机器人学习的机器人复杂决策控制任务. CurricuLLM利用LLM的高级决策能力和代码编程能力进行课程设计, 从而增强机器人复杂目标任务决策控制的学习效率.综上, 大模型技术的发展能够不断提升人形机器人在复杂任务的推理决策能力. 通过利用大模型技术将人形机器人作业环境或观察目标的语言、视觉等数据与作业行为进行建模, 生成复杂作业行为的操作策略.(4) 智能人形机器人控制大模型技术. 在通用智能机器人控制方面, 大模型相关研究介绍如下. Vemprala等 [92]提出通过使用ChatGPT解决机器人应用程序的能力, 创建一个简单的高级函数库供ChatGPT学习处理, 允许ChatGPT从自然对话中解析用户意图, 并将其转换为高级函数调用的逻辑链, 实现机器人的操作控制. Liu等 [93]提出一种名为RoboUniView的视觉语言模型, 突破机器人多视角相机的限制, 从多视角视图中学习统一视角表征, 从而学习控制机器人动作的操控. Li等 [94]提出一种简单新颖的视觉语言大模型机器人操作控制框架, 名为RoboFlamingo, 利用预训练的VLM进行单步视觉语言理解, 通过模仿学习, 在语言条件操纵数据集上进行轻微的微调, 将VLM适配到机器人控制. 这是一种成本效益高且易于使用的机器人操纵解决方案. Liu等 [95]提出一种ControlLLM框架, 通过任务分解、基于图的思考范式和执行引擎, 使大型语言模型能准确高效地利用多模态工具解决复杂的现实世界任务. Ma等 [96]提出一种基于语言–图像价值学习(LIV)的大模型方法, 通过从带有文本注释的无动作视频中学习视觉–语言表示和奖励, 以寻求适用于机器人控制的优秀视觉–语言大模型.此外, 大模型技术在人形机器人控制方面的研究与通用智能机器人控制大模型技术大体相似, 一般通过利用大模型技术来生成机器人的控制指令. 例如, Guo等 [97]提出一种基于大型语言模型(LLM)和视觉语言模型(VLM)的人形机器人作业规划控制方法, 通过利用LLM规划生成可行和可执行的文本计划, 结合VLM持续检测约束执行过程中的控制指示偏差. Bärmann等 [98]提出一种基于大型语言模型的人形机器人人机行为控制方法, 人类的指令、环境观察和执行结果输入至大语言模型中, 通过引入交互中增量学习, 使人形机器人能够从错误中学习, 来改进自己的行为或避免将来犯错. Jiang 等 [99]提出一种多模态大模型的人形机器人运动控制器, MotionChain, 包括多模态分词器, 它们将文本、图像和运动等各种数据类型转换为离散的标记, 结合视觉–运动感知语言大模型, 通过利用大规模的语言、视觉–语言和视觉–运动数据来辅助与运动相关的生成任务. Jiang等 [100]提出一种基于视觉语言模型的人形机器人运动控制方法, HARMON (humanoid robot motion generation), 通过利用VLM的常识推理能力, 结合人类动作运动先验知识, HARMON能够生成与语言描述一致的自然人形机器人运动, 并在模拟和真实的人形机器人上执行这些动作.综上, 人形机器人通过利用大模型技术, 将人形机器人作业环境中的控制指令、环境感知数据与行为运动控制进行训练. 控制指令可以利用大模型技术生成人形机器人相应的控制代码, 结合视觉–语言–动作等多模态数据, 综合人类动作运动等先验知识, 实现人形机器人作业行为的运行控制.2.2.2 端到端一体化大模型技术随着大模型的研究方向愈加广泛, 诸多研究人员开展了一系列工作, 如端到端的大模型训练 [101-104], 利用机器人技能数据集对多模态大语言模型MLLM进行预训练, 一组开放的指令和一组开放的目标, 实现日常操作任务的零样本的轨迹合成与操作控制. 例如, Kim等 [104]提出OpenVLA (open-source vision-language-action model)模型, 一种端到端机器人抓取任务的控制大模型技术, 将动作预测问题制定为“视觉语言"任务, 其中输入观察图像和自然语言任务指令被映射到一系列预测的机器人动作. Yue 等 [105]提出一种基于动态早退标准(early-termination criteria)的具身智能机器人控制框架, 该框架利用了MLLM中的多输出预测机制, 能够根据当前机器人控制环境自动调整所激活MLLM的规模, 使模型在激活适当规模后根据计算需要, 提前终止处理从而避免冗余计算.谷歌机器人团队Brohan等和Everyday Robots的研究人员在2022年开发了一种端到端机器人控制大模型, RT-1 [55], 通过Transformer模型学习得到机器人的技能, 然后使用自然语言控制机器人的运动. 随后, 团队发现RT-1泛化能力不行, 遇到没见过的任务(包括物体和环境)就难以实现机器人作业任务控制, 而如果靠人工示范继续去构建更多的数据集去接着训练RT-1的模型, 又十分费时费力. 因此, 提出RT-2 [62], 将使用互联网规模数据(internet-scale data)训练得到的VLM模型直接用于端到端的机器人控制, 直接生成底层(low-level)的机器人运动指令, 提升机器人操作的泛化能力和语义推理能力. RT-2证明了使用机器人技能数据集对已有的LLM或者VLM进行微调, 可以快速地利用VLM的海量通识能力, 大幅提升机器人的任务执行成功率和泛化能力, 基于视觉–语言大模型的端到端机器人控制技术路线如图12所示. 近期, 该团队Padalkar等 [106]提出一种RT-X模型, 并构建一个开源的机器人具身智能数据库. 多模态大模型的具身智能体架构也可以用于无人机决策控制端到端一体化作业任务中, Zhao等 [107]提出了一套“Agent as Cerebrum, Controller as Cerebellum" (智能体即大脑, 控制器即小脑)的控制架构, 用于无人机决策控制一体化. 智能体作为大脑这一决策生成器, 专注于生成高层级的行为; 控制器作为小脑这一运动控制器, 专注于将高层级的行为(如期望目标点)转换成低层级的系统命令(如旋翼转速).在基于大模型的端到端人形机器人控制技术方面, Yoshida等 [108]开发了一种人形机器人, Alter3, 有效地将大型语言模型(LLM)与Alter的身体运动控制相结合. 通过利用LLM, 如GPT-4, 生成自发性动作的程序代码, 将人类动作的语言表达映射到机器人的身体上, 实现直接运动控制. Liu 等 [109]提出一种基于MLLM的人形机器人灵巧抓取手抓取控制方法, 通过多视角和多模态视觉数据, 训练灵巧手模仿人类动作. Li 等 [110]提出一种基于多模态大模型的人形机器人自主技能学习控制框架, RoboCoder, 通过将LLM与动态学习系统结合, 能够实时环境反馈来不断更新和改进控制人形机器人的动作代码. Mu等 [111]提出一种具备树状思维推理能力的大型视觉语言模型, RoboCodeX, 通过利用大模型直接将人类的人机交互指令转换为机器人动作的代码指令, 实现人机交互的端到端学习框架. 为了增强RoboCodeX在代码中表达物理机器人偏好和行为的推理能力, 构建一个多模态推理数据集用于预训练, 并引入了迭代自我更新的方法进行监督微调. RoboCodeX能够预测物理约束、偏好排名和目标位置建议, 可以作为高层次概念知识与低层次机器人行为之间的接口. Bohlinger等 [112]提出一种端到端的具身智能机器人学习框架, 统一机器人形态架构(unified robot morphology architecture), 能够实现控制任何类型机器人形态(四足机器人、六足机器人、双足机器人和人形机器人)的运动控制.综上, 具身智能人形机器人技术, 可以通过利用端到端一体化的大模型框架, 从作业环境的数据感知识别、作业任务认知决策、作业任务操作的动作轨迹规划与控制执行, 并生成相应操作动作控制代码, 实现端到端作业任务优化与具身智能控制.2.2.3 云边端协同化大模型技术端侧大模型之兴起, 主要归因于云侧大模型推理成本高昂、数据隐私保护需求迫切以及网络连接存在限制. 然而, 端侧大模型亦有其局限性, 具体表现为对高算力的需求、较大的功耗以及参数量级相对较小. 值得注意的是, 端侧大模型与云侧大模型之间并非竞争关系, 而是相互补充、协同工作的关系. 端侧大模型能够处理即时任务并有效保护数据隐私, 而云侧大模型则以其更强大的处理能力见长. 通过充分发挥端侧与云侧大模型各自的优势, 可以最大限度地挖掘两者在智能推理任务中的潜力. 在实际应用中, 大模型向边缘端和终端的小模型输出其模型能力, 由小模型负责具体的推理与执行工作, 同时小模型再向大模型反馈算法执行效果. 目前, 云边端大模型技术的主要发展方向包括云边协同的端到端学习训练以及生成式大模型的应用等. 例如, Zhuang等 [113]提出一种边缘端–云端协作的大模型训练学习框架, ECLM (edge-cloud collaborative learning model), 在高度动态的边缘环境, 通过块级模型分解设计, 将大型云模型分解为可组合模块, 同时允许从云模型派生出适用于不同边缘设备的特定任务子模型, 并能将边缘设备上的新知识整合回云模型. ECLM框架包含离线的模型设计和训练阶段, 以及在线的边缘–云协作适应阶段, 形成端到端的学习流程. 通过边缘和云模型的高效协作, 提升模型性能和资源效率.生成式人工智能(generative artificial intelligence, GenAI)是人工智能技术发展的关键组成部分, 然而现有训练和部署大型人工智能模型面临计算和通信开销巨大, 需要高性能计算基础设施, 且存在远程云服务的可靠性、保密性和及时性问题. 为应对这些挑战, Tian等 [114]提出一种自下而上的大模型训练部署架构, 结合了大型云模型和小型边缘模型, 设计了分布式训练框架和面向任务的部署方案, 以高效提供原生GenAI服务. 尽管LLM在理解语义和代码生成方面表现出色, 但在处理复杂任务时仍存在挑战, 如多智能体策略生成和运动控制是需要跨领域专家协作的高度复杂领域. Luan 等 [115]提出一种创新的云–边缘–端层级架构, 通过多个专业领域的大型语言模型高效生成策略和任务分解, 引入余弦相似度方法, 实现任务分解指令与机器人任务序列的向量级对齐, 生成可执行的机器任务序列. 该架构成功解决了多智能体在开放场景中执行开放任务和任务分解的挑战. 稳定扩散模型(stable diffusion model, SDMs)在图像生成领域表现出色, 但其应用受限于模型体积大和计算密集. 现有的小模型虽适合边缘设备, 但通常在语义完整性和视觉质量上不如全尺寸SDMs. Yan等 [116]提出一种Hybrid SD边缘–云协作架构, 由云服务器上的大型模型处理, 以增强语义规划, 通过边缘设备上的小型模型细化视觉细节, 通过边缘-云协作显著地降低推理云成本.此外, 在人形机器人的大模型技术方面, 基于云边端协同的大模型方法仍处于初步探索阶段, 相关研究较少. 但毫无疑问, 基于云边端协同的多具身智能人形机器人分布式感知规划控制决策或端到端一体化的机器人技术将是未来具身人形机器人技术的发展趋势.3 AI大模型驱动的具身智能人形机器人应用案例随着机器人控制、智能传感、人工智能等技术迅猛进步, 特别是AI大模型与生成式AI技术的突破性进展, 人形机器人已成为各方竞相角逐的未来产业新领域, 并有力推动人形机器人技术的飞跃与商业化应用的实现. 人形机器人涵盖了机械、电气、材料科学、传感技术、控制技术、人工智能等多个学科的交叉与融合, 被国际社会广泛视为机器人技术的巅峰之作与战略高地. 如图 13所示, 这是在智能制造与无人系统领域中, 一种典型基于分布式多模态大模型的人形机器人化作业技术. 如图14所示,这是国际上各大强国发布的关于人形机器人的相关产品阵列.3.1 智能制造相较于传统的工业机器人, 应用于制造业的人形机器人无需再遵循预设规划来完成特定任务, 而是能够感知并理解周边环境, 通过学习来作出决策, 且不再局限于单一场景. 在AI大模型技术的赋能下, 人形机器人展现出了极强的自主决策能力、柔性操作能力和交互能力. 综合来看, 人形机器人在制造业工厂的典型应用场景主要包括物品搬运、拾取、检测、装配、巡检以及高危作业等.目前, 人形机器人在智能制造领域中的实际应用价值, 在汽车制造行业中尤为显著. 优必选作为国内人形机器人领域的首家上市企业, 其旗下的工业版人形机器人Walker S已在蔚来新能源汽车工厂进行了实际场景下的“实训". 该机器人成功执行了包括移动产线启停、自适应行走、鲁棒里程计与行走规划、感知自主操作以及系统数据通信与任务调度等多项复杂任务. 在汽车生产线中, Walker S负责了车门锁质量检查、安全带检测以及车灯盖板质量检验等关键工序, 并展示了以流畅且柔和的动作精确贴装车标的精湛技能. 在2024年世界机器人大会上, Walker S 还展示了其智能搬运和分拣能力, 实现了高效质检. 在执行搬运任务时, 该机器人会先构建周围环境的3D语义地图, 以实现复杂环境中的精准导航与避障. 通过视觉识别和模仿学习, 机器人能够识别并处理多种箱子, 并通过变导纳控制技术确保夹抱力的稳定与精细.2023年8月, 智元机器人发布了第一代通用型具身智能机器人“远征A1", 并在汽车制造工厂中展示了其具体应用. 该机器人在3C装配线上完成了齿轮点油任务, 在汽车底盘线上进行了底盘装配, 同时在汽车OK线上进行了外观检测, 充分展现了其在工业领域的多功能性和实用性. 此外, 华为云与乐聚机器人共同推出了首款搭载鸿蒙操作系统的人形机器人“夸父". 该机器人已进入蔚来、江苏亨通集团等工厂进行检测验证. 夸父具备跳跃和多地形行走能力, 并搭载了盘古具身智能大模型, 在智能化和泛化能力上得到了显著提升. 它能够完成扫码包装、物流搬运、沾锡等非标工序的自动化, 从而提高生产效率, 降低生产成本, 并提升生产安全性. 傅利叶(Fourier)智能推出了第一台实现量产交付的双足人形机器人, 通用人形机器人GR-1. GR-1拥有高度仿生的躯干构型, 覆盖人体主要自由度, 拥有稳定的运动能力和敏捷性, 是通用人工智能的理想载体. 它具备快速行走、敏捷避障、稳健上下坡、抗冲击干扰等运动功能, 在工业、康复、居家、科研等多种应用场景中的潜能巨大.美国特斯拉研制的Optimus人形机器人已具备流畅行走和抓取物体的能力. 在结合端到端神经网络进行训练后, 该机器人能够执行基本的工厂任务并自行纠正错误. Optimus的控制系统中采用了特斯拉的FSD控制器, 提供了高级的视觉处理能力和实时决策制定功能. 这使得Optimus能够在没有人类直接监督的情况下, 自主完成复杂任务, 有效支持其复杂数据处理和实时决策需求. 美国初创公司Figure与OpenAI联合推出的机器人展示了高级的交互能力, 如会话、视觉识别以及递送物品等. 该机器人能够自行识别、规划并执行任务, 其背后的技术包括OpenAI的视觉推理和语言理解技术支持. 目前, 该公司已与宝马制造公司签署协议, 计划在美国工厂部署人形机器人, 进行薄板金属处理、箱子搬运、拾取和放置任务及托盘装载等任务. 苹果公司开发了一款名为ARMOR [117]的人形机器人感知系统, 该系统基于Transformer架构开发, 让机器人能够快速高效地规划无碰撞轨迹, 提升了机器人的环境感知能力和动态避障能力. 研究团队已经成功将ARMOR系统部署在了傅利叶GR-1机器人上, 安装了28个ToF激光雷达传感器, 实现了15 Hz的实时轨迹规划和避障控制. Agility Robotics公司发布了一款双足移动操纵人形机器人Digit, 这是世界上第一家人形机器人工厂RobotFab, 使用人形机器人生成人形机器人, 计划每年生产1万台Digit人形机器人. 同时与大型合同物流供应商 GXO Logistics 合作, 可能成为第一个在工作环境中商业部署的人形机器人.人形机器人, 作为智能制造领域中的新兴势力, 正逐渐显现出其巨大的发展潜力. 然而, 若要实现人形机器人在工业制造场景中的广泛应用, 仍需应对众多挑战. 首要任务是, 人形机器人需进一步积累场景数据, 以不断优化其感知、决策与控制能力, 进而提升其在不同应用场景下的通用性和适应性. 其次, 从工程化角度来看, 人形机器人还需在稳定性、可靠性、成本控制及能耗管理等方面取得突破, 以期在实际应用中达到最佳运行效果, 并有效降低使用门槛. 此外, 相较于传统工业机器人, 人形机器人在精度、力量等方面尚存在不足, 需进一步提升其视觉精度、双手操作的灵巧性、在保持平衡姿态下的工作能力, 以及根据指令灵活调整任务的能力.展望未来, 随着人工智能、传感器、驱动器等技术的持续进步, 以及工程化水平的不断提升, 人形机器人有望在更多场景中发挥重要作用, 推动工业制造向智能化、自动化及柔性化方向发展. 例如, 在人机协作模式下, 人形机器人能够与工人协同作业, 共同完成危险、重复或高强度的工作任务, 从而释放人力资源, 提升生产效率. 此外, 人形机器人还可应用于产品的检测、装配及质量控制等环节, 进一步提升产品质量及生产效率. 随着技术的不断演进, 人形机器人有望成为智能制造领域的关键力量, 推动产业升级, 并创造更为显著的经济效益与社会价值.3.2 无人系统随着人工智能技术的迅猛进步, 大型模型在军事领域的应用范围不断拓展, 尤其在无人系统作战方面展现出显著优势, 为作战情报感知、态势分析、知识推理、任务规划及评估等多个环节和阶段提供了智能化支持. 大型模型凭借其卓越的数据处理和计算能力, 利用深度学习技术实现了目标识别与追踪, 为无人系统精确打击目标提供了有力保障. 面对新型、未知目标, 大型模型展现出优秀的泛化能力, 能够准确识别并追踪目标, 有效应对战场环境的复杂性.2023年5月, 美国、英国及澳大利亚成功举办了首届“奥库斯人工智能和自主系统"作战试验, 实现了无人机目标算法在飞行中的实时更新及国家间AI模型的交换与使用. 在机器学习模型和人工智能技术的驱动下, 试验中的无人机蜂群能够自主融合并快速处理所收集的传感器数据. 抵达指定区域后, 无人机蜂群开始识别、分类和定位威胁, 并将数据传输至其他节点.在复杂多变的战场环境中, 路径规划是一项极具挑战性的任务. 大型模型通过学习历史数据, 深入了解战场环境的特征和规律, 为无人系统规划出最优打击路径. 同时, 大型模型还能结合实时的战场态势信息, 动态调整路径规划, 以适应战场环境的变化, 确保无人系统能够迅速、有效地完成任务. 无人系统依据大型模型的指令, 进行自主行动和决策, 适应战场环境的变化, 提升作战效能. 美军配备自主控制系统的X-62A验证机已完成超视距空战和近距离空中缠斗试验, 为后续开发可扩展、类人化的自主空战能力奠定了坚实基础. 此外, 大型模型还能促进无人系统间的协同作战. 通过整合和分析无人系统的感知信息, 大型模型实现信息共享, 促进协同作战. 无人机与无人地面车辆可协同作战, 无人机负责侦察和打击, 无人地面车辆负责支援和保障, 共同形成强大的作战力量.以往, 受限于技术水平, 人形机器人在战场实际应用中的表现受到较大制约. 然而, 随着大模型技术的迅猛进步, 新一代人形机器人已具备了在复杂场景中实现感知、决策与规划的“大脑"功能, 以及精确控制高度灵活肢体运动的“小脑"能力, 显著增强了其在复杂战场环境下的适应能力. 此外, 强烈的战场需求、技术的重大突破以及产业的迅速发展, 为人形机器人在战场的应用奠定了坚实基础, 使得人形机器人的战场应用成为必然趋势. 人形设计使得机器人能更好地融入人类工作环境, 适配武器装备, 执行多样化军事任务, 展现出更强的通用性和更高的战场利用率. 美国波士顿动力公司为美国军方研制了一款名为“Petman"的军用机器人, 能够像士兵一样活动手臂和大腿, 还能够做俯卧撑. Petman还能通过控制温度、湿度和出汗量来模拟人体生理现象, 以期达到更真实的测试效果. 这款人形机器人正在接受各项性能的检验, 下一步计划是让Petman接受“实战演习", 检验其是否能在沙林、芥子毒气等环境中运行. 待通过“实战演习"之后, 将在美国军队“服役", 为美军测试各种防护服装和军事设备.在后勤保障领域, 武器制造、库室管理、物资搬运、装备维修、协助救灾等任务往往具有简单重复性且环境相对封闭, 同时对人力资源的需求较高. 人形机器人的引入能够显著提升工作效率, 降低安全隐患. 例如, 俄罗斯研发的“FEDOR"人形机器人, 不仅能在多种极端环境下执行指令, 还能在紧急情况下提供物资补给、武器运送和战斗支援. 在灾害救援方面, 人形机器人同样能够转移伤员至安全地点, 减轻对救援人员的依赖. 此外, 人形机器人不受生理条件限制, 在极端环境如高温、低温、高海拔、有毒等条件下执行排爆、侦查和攻击等高风险任务方面具有巨大潜力. 波士顿动力公司为美军研制的人形机器人“Atlas"展现出卓越的行走、奔跑、跳跃、上下楼梯、避障、360∘∘后空翻、三连跳等高机动能力, 能够在实时遥控下穿越复杂地形. 谷歌 Alphabet公司开发的双足机器人Schaft, 这款机器人还会自己清洁楼梯, 在踩到钢管这样的物体之后也可以保持平衡, 甚至还可以在海边沙滩、雪地中稳步行走. 至少在平衡行走方面, Schaft机器人与波士顿动力的技术水平不相上下, 主要用于协助救灾等任务.人形机器人在战场应用的最高等级场景是协同作战. 它们不仅能够与人类并肩作战, 协助完成各项任务, 还能在必要时充当诱饵吸引火力, 主动“牺牲"以掩护人类. 为此, 需要结合先进的人工智能技术, 训练机器人掌握机动隐蔽、情报侦察、识别定位、武器操控等军事技能, 拓展语言、动作、情绪等多种人机交互方式, 并提升自主决策能力. 尽管人形机器人在无人作战领域的应用前景广阔, 但目前仍面临一系列技术和非技术挑战. 在关键技术方面, 缺乏高质量的战场数据, 动力设备亟待突破, 控制行动的灵活性不足, 且能量密度电池和轻量化材料的研发需加速推进. 在道德伦理层面, 联合国秘书长古特雷斯指出, 具有杀伤能力的机器应被禁止, 误击风险引发的责任归属问题亟待解决, 同时长期共处可能导致心理认知偏差. 此外, 成本问题也是制约人形机器人应用的重要因素. 商用和军用人形机器人的造价高昂, 需通过提升制造工艺和实现规模化生产来降低成本.4 大模型驱动的具身智能人形机器人技术挑战与展望由大型模型驱动的人形机器人正处于迅猛发展的时期, 但同时也为机器人行业开辟了新的前景, 如服务机器人、家庭助理以及医疗护理机器人等. 
这些集成大型语言模型(LLM)、大型视觉–语言模型(VLM)、大型音频–语言模型(ALM)和大型视觉导航模型(VNM)的人形机器人, 能够更加高效地执行包括感知、预测、规划和控制在内的多样化任务 [118], 但相关技术同样遭遇了诸多挑战, 相关技术挑战如图15所示.4.1 工业大模型与人形机器人技术融合的挑战为提升人形机器人在高度复杂工业制造环境中的适应能力, 需强化其个体认知能力, 即赋予其更为先进的感知与处理逻辑. 然而, 将大型模型应用于人形机器人领域仍面临诸多技术难题, 包括数据获取、泛化性能、不确定性量化、安全评估、实时性能以及高昂的算力成本等. 具体而言, 如何获取足够规模的数据以实施自我监督训练; 如何适应多变的物理环境和任务需求等问题亟待解决. 此外, 实时性亦能构成一项关键挑战, 鉴于部分基础模型的推理时间较长, 这在一定程度上会制约机器人的快速决策与部署能力.大模型的数据短缺, 优质且可靠的训练数据不足 [119]. 人形机器人在工业场景的数据收集较为困难且难度大, 由于大多数工业企业缺乏专门的数据管理组织, 数据管理人力有限, 缺乏数据隐私保护,且大部分工作集中在数据和操作等基础领域, 缺少顶层规划和管理, 从而造成数据治理的滞后, 影响了数据的质量和可用性. 此外, 数据的共享机制不够完善, 优质的工业数据语料库不能获取用于模型训练, 限制了高质量数据资源的有效利用. 产业数据规模和泛化性不足, 数据的适应场景局限, 导致每次更换场景都需要重新训练大模型, 增加成本. 大模型的多模态数据建模与解释, 人形机器人大模型的复杂性对数据的处理和解释也会产生显著的影响, 如何让大模型更加通透且易于理解也是面临的挑战之一. 随着人形机器人大模型应用的复杂性增加, 需要集成学习和多模型协同, 以处理更加复杂的任务和数据. 大模型能够将庞杂的数据处理和解释成能够读懂的语言, 而对于这些庞杂的数据, 如何有效地管理和解释仍是一个挑战, 特别是在特定领域和任务中, 训练数据的获取和标注仍是一个巨大难题. 针对大模型数据的问题, 一方面可以通过制定大模型数据标准, 开发通用数据采集装备, 创新数据共享机制, 来降低数据采集的难度, 提升数据通用性. 另一方面, 开发用于数据标注的大模型感知认知标注技术, 实现通用场景下一切数据的获取与标注.如何提升大模型的可靠性, 降低大模型算力需要. 大模型可以处理更复杂的数据, 提高机器学习模型的性能, 但如何确保模型的可靠性与可解释性, 顺畅完成工业应用, 仍是一个难题. 另外, 算力成本太高, 初期训练一个大型模型, 需要较高的算力成本, 尤其是针对极多参数大模型, 提高模型泛化能力的同时, 其相应的算力成本会显著增加. 此外, 算力和数据资源分散, 无法统一调用, 增加了获取足够算力的难度, 提高整体的运营成本. 针对大模型可靠性与算力需求问题, 一方面, 采用新型模型结构与训练手法可以提升模型的泛化能力和鲁棒性, 同时, 跨领域数据与应用场景的融合扩展, 可以提升模型可靠能力. 另一方面, 可以优化模型架构, 降低模型复杂度, 采用新云边端的训练方式, 降低本地应用场景的算力需求.如何适应多任务场景的应用需求. 应用场景存在局限, 无法轻松应对某专业全部场景. 尽管人形机器人在生产制造、研发设计和经营管理等场景中有着广泛的应用潜力, 但在工艺设计等具体应用层面还无法胜任. 为了加强大模型的场景适应性, 可以加强包括如何解决数据标注效率、跨域学习、数据管理方面能力, 以训练出适应性更强、鲁棒性更高(即系统或算法在面对各种随机噪声、异常情况和攻击等干扰时的抗干扰能力)的模型.综上, 尽管存在诸多挑战, 但通过应用工业大模型可以大幅提升生产效率、节约研发成本、优化资源配置已是业界共识. 因此, 工业大模型应用被视为推动制造业高质量发展的重要手段.4.2 大模型驱动的人形机器人技术未来展望在未来, 人工智能领域将迎来大模型与具身智能融合的新浪潮. 具身智能侧重于感知–运动回路的构建, 使机器人能够感知外部环境, 并依据任务目标进行有效规划与决策. 大模型则以其丰富的知识储备, 与具身智能的传统架构相融合, 进一步增强了智能体策略学习的泛化能力. 在产业发展层面,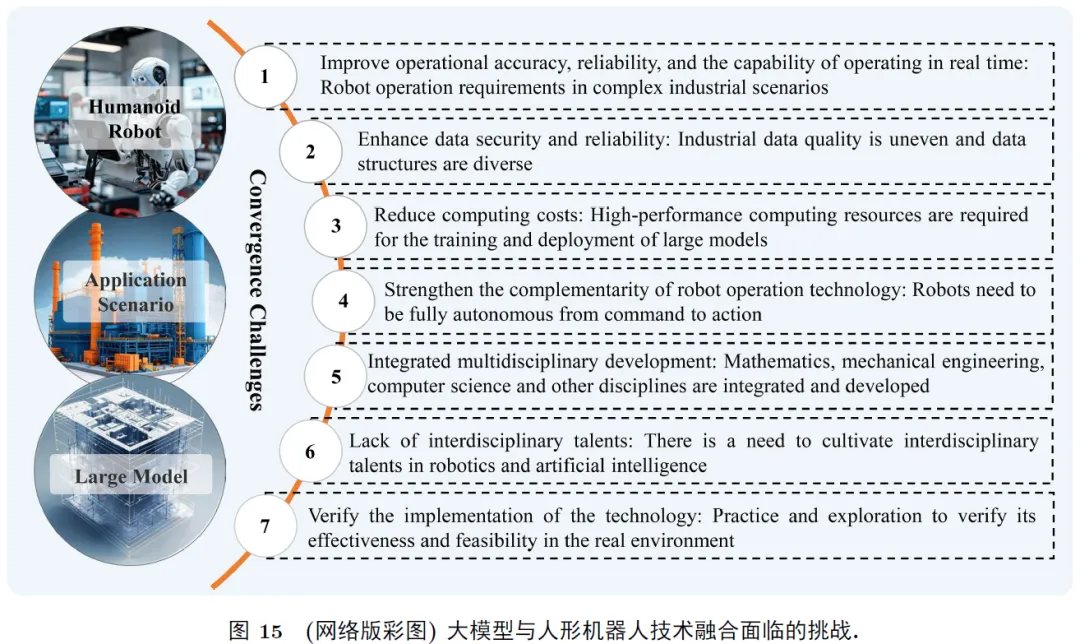
AI大模型技术的革新为人形机器人的智能化发展奠定了坚实基础, 使其能更精准地理解并响应人类需求, 实现更为自然且高效的交互体验. 此外, AI大模型还显著提升了人形机器人的环境感知能力, 使其在复杂多变的环境中展现出更高的灵活性. 随着技术的持续演进, 人形机器人的应用范围正日益拓宽, 涵盖从工业制造到商业服务, 从家庭陪伴到医疗辅助等多个领域, 机器人正愈发频繁地融入我们的日常生活.大模型在决策提升、感知提升、理解提升领域赋能人形机器人, 打开了通用人形机器人的可实现性 [120]. 人形机器人的通用化需要解决三层技术问题, 上层需要对任务做理解、定义、规划、拆分, 中层需要能够强泛化的执行层来满足不同场景的任务执行, 底层是相对成熟的机器人控制, 再搭配上合适的硬件本体. 其中, 3个层级中的顶层设计是最难实现的, 而大模型的能力可完全匹配这一层的需求, 所带来多个领域的基础知识与通识、强大的内容生成能力、良好的上下文理解能力与自然语言连续对话能力, 以及强大的零样本与小样本学习能力, 将有效赋能人形机器人的任务描述、任务分解、运动代码生成、任务过程交互的核心需求, 能够使人形机器人在复杂环境中自主决策和执行动作, 不再仅限于完成某一类特定工作, 使通用人形机器人具有变为现实的可能. 尽管大模型驱动的人形机器人技术具有相当丰富的应用前景, 其仍面临多方面的挑战, 包括算力瓶颈、主流大模型架构的局限、高质量的训练数据集的缺乏, 以及爆款应用的缺失 [121].为了克服这些挑战, 需要加强资源与研发力量的统筹, 强化大模型在发展中的场景牵引作用, 促进经济社会的高质量发展. 总而言之, 大模型驱动的智能机器人技术正朝着更加智能化和自主化的方向发展, 但要实现广泛部署和应用, 还需要在技术、数据和安全等方面进行更多的研究和创新. 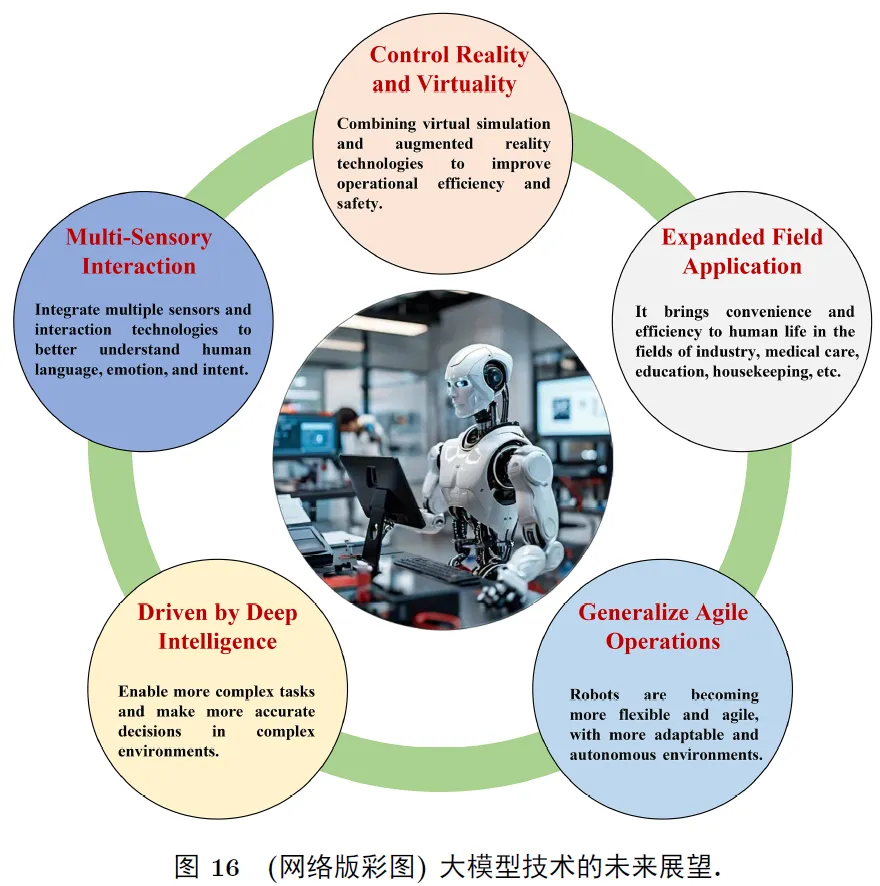
随着这些挑战的逐步解决, 未来的智能机器人将更加聪明和能干, 能够在更多领域服务于人类社会. 关于人形机器人技术的未来展望如图16所示.5 总结大模型技术的发展为具身智能人形机器人的感知识别、认知决策、行为控制等行为注入语言理解、视觉泛化、常识推理等关键能力, 进一步推动了智能人形机器人的应用前景. 本文分析了AI大模型驱动的具身智能人形机器人技术与展望, 详细介绍了通用大模型技术, 如大型自然语言模型、视觉Transformer、视觉语言模型、视觉生成模型、具身多模态大模型等技术, 并从3个方面分析总结了大模型驱动的智能机器人关键技术, 如分布式模块化大模型技术、端到端一体化大模型技术、云边端协同化大模型技术等. 最后总结了大模型技术与具身智能人形机器人技术相结合的典型应用领域, 并探讨了工业大模型与人形机器人技术融合的挑战, 对大模型驱动的具身智能人形机器人技术发展进行了展望分析.
更多推荐


 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)