
XXL-JOB 2.4.0分布式定时任务框架Oracle数据库适配版
作为当前主流的轻量级分布式任务调度平台,XXL-JOB凭借其简洁的设计理念和强大的扩展能力,在企业级应用中广泛落地。本章将深入剖析XXL-JOB 2.4.0版本的整体架构设计,重点解析其在Oracle数据库环境下的适配逻辑与系统分层结构。job_info表承载所有任务元数据,包括Cron表达式、路由策略、执行超时等。原始MySQL脚本多采用宽泛定义(如),在Oracle中会造成空间浪费。应根据实际

简介:XXL-JOB是一款轻量级分布式任务调度平台,其2.4.0版本针对Oracle数据库进行了SQL语法优化与兼容性增强,支持在企业级Oracle环境中稳定运行。该版本包含适配Oracle的建表脚本、核心调度模块及执行器组件,提供任务管理、分布式执行、日志追踪等功能。通过Admin控制台与Executor执行器的协同工作,开发者可实现Java、Shell、Python等类型任务的定时调度。本资源适用于需在Oracle环境下部署高可用定时任务系统的开发与运维人员,具备良好的扩展性与维护性。 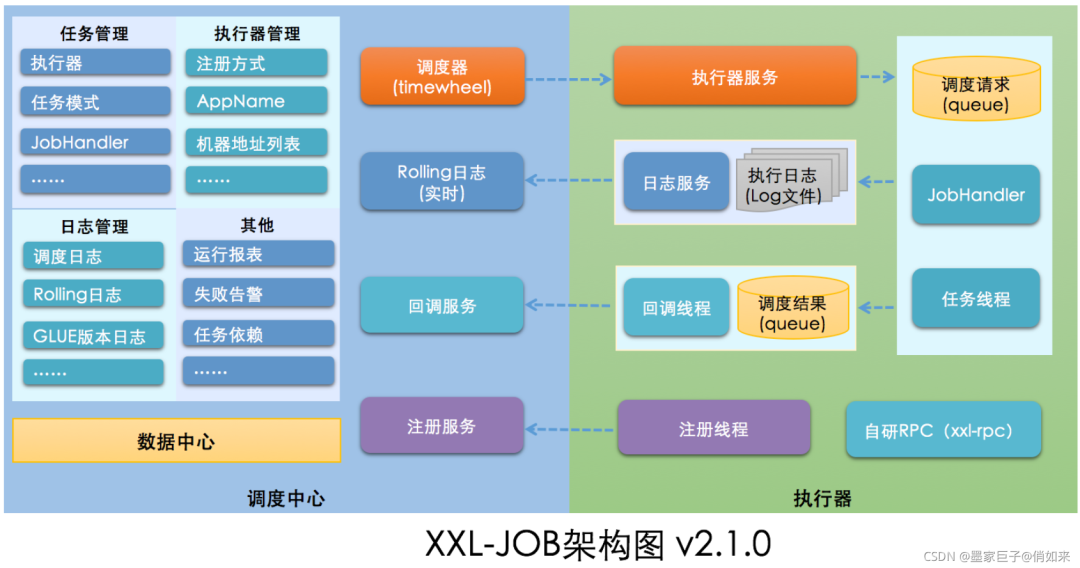
1. XXL-JOB框架概述与核心架构
作为当前主流的轻量级分布式任务调度平台,XXL-JOB凭借其简洁的设计理念和强大的扩展能力,在企业级应用中广泛落地。本章将深入剖析XXL-JOB 2.4.0版本的整体架构设计,重点解析其在Oracle数据库环境下的适配逻辑与系统分层结构。
核心组件与职责划分
XXL-JOB采用“调度中心(Admin)+ 执行器(Executor)”的分布式架构模式,实现调度与执行的解耦。调度中心负责任务管理、触发调度、节点监控及日志汇聚;执行器则内嵌于业务应用中,接收调度请求并执行具体任务逻辑。
graph TD
A[调度中心 Admin] -->|HTTP 请求| B(执行器 Executor)
B --> C[任务执行]
C --> D[结果回传]
D --> A
注册中心基于数据库实现,执行器启动后通过心跳机制向 xxl_job_registry 表注册节点信息,调度中心定时扫描以维护在线节点列表,保障高可用发现能力。
通信模型与任务触发流程
任务触发采用拉模式(Pull)与推模式(Push)结合机制。调度中心根据Cron表达式生成触发计划,通过轮询获取待执行任务,再通过HTTP协议直接调用目标执行器的 /run 接口完成调度指令下发。
该过程涉及三大核心线程:
- JobScheduleHelper :负责扫描任务并触发调度;
- TriggerCallbackThread :处理执行结果回调;
- RegistryMonitorThread :监控执行器注册状态。
Oracle环境适配要点
为支持Oracle数据库,需对原生MySQL脚本进行语法兼容性改造,包括:
- 数据类型映射(如 TINYINT → NUMBER(1) );
- 自增主键改用 SEQUENCE + TRIGGER 实现;
- 分页查询由 LIMIT 改为 ROWNUM 或 ROW_NUMBER() 窗口函数。
同时,MyBatis映射文件中需调整 useGeneratedKeys 等属性,确保主键正确返回。这些底层适配是后续章节建表与配置集成的基础。
2. Oracle数据库SQL语法兼容性优化
在将XXL-JOB框架从默认支持的MySQL环境迁移至企业级常用的Oracle数据库时,首要挑战便是SQL语法层面的兼容性问题。尽管两者均遵循SQL标准,但在数据类型定义、自增机制、分页查询、事务处理等方面存在显著差异。这些差异若未被妥善处理,将直接导致建表失败、DML操作异常、性能瓶颈甚至调度逻辑紊乱。因此,必须系统性地识别并解决核心SQL语句在Oracle中的适配问题,确保调度中心与执行器的数据交互稳定高效。
本章聚焦于XXL-JOB在Oracle环境下运行所面临的SQL兼容性痛点,深入剖析语法差异对任务信息管理、日志存储及配置持久化的实际影响,并提出一系列可落地的改写策略与封装方案。通过结合PL/SQL高级特性与Oracle优化工具,不仅实现功能等价迁移,更进一步提升系统的健壮性与执行效率。
2.1 Oracle与MySQL语法差异对XXL-JOB的影响
Oracle与MySQL作为两种主流关系型数据库,在架构设计哲学上存在本质区别:Oracle强调严格一致性与企业级事务保障,而MySQL则以轻量灵活著称。这种差异映射到SQL语法层面,直接影响了XXL-JOB这类依赖固定表结构和频繁DML操作的调度系统。尤其在 job_info 、 executor_log 等关键表的操作中,类型不匹配、主键生成方式不同以及分页机制缺失等问题尤为突出,需逐一分析并制定应对策略。
2.1.1 数据类型映射问题(如TINYINT转NUMBER)
在MySQL中, TINYINT(4) 常用于表示状态字段(如启用/禁用、成功/失败),其取值范围为-128~127或0~255(无符号)。然而Oracle并无对应的数据类型,需使用 NUMBER 类型进行替代。若简单替换为 NUMBER 而不设定精度,则可能导致存储浪费与索引效率下降。
例如,原MySQL建表语句中的字段定义:
status TINYINT(4) DEFAULT '0' COMMENT '任务状态'
在Oracle中应调整为:
STATUS NUMBER(2,0) DEFAULT 0 NOT NULL
| MySQL 类型 | 推荐 Oracle 映射 | 说明 |
|---|---|---|
| TINYINT | NUMBER(2,0) | 表示-99~99之间的小整数,满足状态码需求 |
| SMALLINT | NUMBER(5,0) | 可表示-32768~32767 |
| INT | NUMBER(10,0) | 对应32位整数范围 |
| BIGINT | NUMBER(19,0) | 支持64位长整型 |
| VARCHAR(n) | VARCHAR2(n) | Oracle推荐使用VARCHAR2而非VARCHAR |
| TEXT | CLOB | 超过4000字符建议使用CLOB |
该映射策略保证了数据完整性的同时,也利于后续索引构建与统计信息收集。值得注意的是,Oracle中 NUMBER(p,s) 的精度 p 代表总位数, s 为小数位数。对于状态字段设置 NUMBER(2,0) 既能节省空间,又能避免误存非法值。
此外,还需注意默认值语法差异。MySQL允许字符串形式的默认值 '0' ,而Oracle要求类型一致,故必须写成数值 0 ,否则会引发隐式转换警告或错误。
-- 正确写法
ALTER TABLE XXL_JOB_INFO ADD STATUS NUMBER(2,0) DEFAULT 0 NOT NULL;
-- 错误写法(可能触发ORA-01858)
ALTER TABLE XXL_JOB_INFO ADD STATUS NUMBER(2,0) DEFAULT '0' NOT NULL;
逻辑分析:上述DDL语句通过显式指定数值型默认值,避免了字符到数字的隐式转换开销,提升了插入性能。同时NOT NULL约束强化了业务语义——每个任务必须有明确状态,防止空值引发调度判断歧义。
2.1.2 自增主键实现方式的替换(SEQUENCE + TRIGGER)
MySQL原生支持 AUTO_INCREMENT 属性,可在插入记录时自动填充主键值。但Oracle直到12c才引入 IDENTITY COLUMN ,且旧版本仍广泛使用 SEQUENCE + TRIGGER 组合模拟自增行为。考虑到多数企业生产环境仍运行在11g或更早版本,采用兼容性强的传统方案更为稳妥。
以 xxl_job_info 表为例,原MySQL定义如下:
id INT AUTO_INCREMENT PRIMARY KEY
在Oracle中需分解为三步操作:
- 创建序列(Sequence)用于生成唯一ID;
- 定义触发器(Trigger),在INSERT前自动获取下一个序列值;
- 移除主键列上的自增属性,仅保留主键约束。
-- 1. 创建序列
CREATE SEQUENCE SEQ_XXL_JOB_INFO
START WITH 1
INCREMENT BY 1
NOCACHE
NOCYCLE;
-- 2. 创建触发器
CREATE OR REPLACE TRIGGER TRI_XXL_JOB_INFO_BEFORE_INSERT
BEFORE INSERT ON XXL_JOB_INFO
FOR EACH ROW
BEGIN
IF :NEW.ID IS NULL THEN
SELECT SEQ_XXL_JOB_INFO.NEXTVAL INTO :NEW.ID FROM DUAL;
END IF;
END;
/
flowchart TD
A[INSERT INTO XXL_JOB_INFO] --> B{触发 BEFORE INSERT 触发器}
B --> C[检查 :NEW.ID 是否为空]
C -->|是| D[执行 SEQ_XXL_JOB_INFO.NEXTVAL]
D --> E[赋值给 :NEW.ID]
C -->|否| F[保持用户指定值]
E --> G[继续插入流程]
F --> G
G --> H[写入数据块]
代码逐行解读:
CREATE SEQUENCE SEQ_XXL_JOB_INFO: 定义一个名为SEQ_XXL_JOB_INFO的序列对象。START WITH 1: 初始值设为1,与MySQL自增起始一致。INCREMENT BY 1: 每次递增1,保证连续性。NOCACHE: 禁止缓存序列值,防止实例重启时跳号(适用于高可靠性场景);若追求性能可设为CACHE 20。NOCYCLE: 禁止循环使用,达到最大值后报错而非重置。CREATE OR REPLACE TRIGGER: 创建或替换同名触发器,便于迭代更新。BEFORE INSERT ON XXL_JOB_INFO: 指定在插入前触发。FOR EACH ROW: 行级触发器,每行插入都执行一次。IF :NEW.ID IS NULL THEN ... END IF;: 使用:NEW伪记录引用即将插入的新行,判断主键是否为空,避免覆盖手动指定ID的情况。
此方案完美兼容现有应用逻辑——开发者无需修改DAO层代码即可获得“类自增”体验。同时,由于序列独立于表存在,还可跨表共享(如统一ID生成服务),具备良好扩展性。
2.1.3 分页查询语法调整(ROWNUM vs LIMIT)
分页是Web控制台展示任务列表的核心功能。MySQL使用 LIMIT offset, size 实现简单高效的分页:
SELECT * FROM xxl_job_info ORDER BY id DESC LIMIT 10 OFFSET 0;
而Oracle早期版本不支持 LIMIT ,需借助 ROWNUM 虚拟列配合子查询完成:
SELECT * FROM (
SELECT ROWNUM RN, TMP.* FROM (
SELECT * FROM XXL_JOB_INFO ORDER BY ID DESC
) TMP WHERE ROWNUM <= 20
) WHERE RN > 10;
该嵌套查询结构复杂,易出错且难以维护。但从Oracle 12c开始引入了标准SQL:2008的 OFFSET...FETCH 语法,极大简化了分页表达:
SELECT * FROM XXL_JOB_INFO
ORDER BY ID DESC
OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
| 特性 | MySQL LIMIT | Oracle ROWNUM嵌套 | Oracle 12c+ OFFSET/FETCH |
|---|---|---|---|
| 语法简洁度 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ |
| 执行效率 | 高 | 中(全排序+双层过滤) | 高 |
| 可读性 | 极佳 | 差 | 良好 |
| 兼容版本 | 所有 | 所有 | 12.1及以上 |
针对不同Oracle版本,建议采取差异化策略:
- Oracle < 12.1 :使用
ROWNUM嵌套查询,但应在MyBatis Mapper中封装为动态SQL模板,避免硬编码。 - Oracle ≥ 12.1 :优先启用
OFFSET/FETCH语法,可通过Spring Profile切换方言配置。
<!-- MyBatis 动态分页片段 -->
<sql id="pagination">
<choose>
<when test="dialect == 'oracle12c'">
OFFSET #{offset} ROWS FETCH NEXT #{pageSize} ROWS ONLY
</when>
<otherwise>
<![CDATA[
) WHERE ROWNUM <= #{offset + pageSize}
) WHERE RN > #{offset}
]]>
</otherwise>
</choose>
</sql>
逻辑分析:通过抽象分页逻辑并注入数据库方言标识,实现了SQL层的解耦。此举既保障了老版本兼容性,也为未来升级预留空间。同时应注意,无论哪种方式,都应在 ORDER BY 字段上建立合适索引(如 IDX_JOB_ID_DESC ),否则全表扫描将严重拖慢响应速度。
2.2 核心表结构的SQL改写策略
完成基础语法映射后,下一步是对XXL-JOB三大核心表—— job_info 、 executor_log 、 job_config ——进行针对性改造。不仅要确保字段类型正确,还需结合Oracle特性优化存储结构、提升查询性能,并合理设计约束与索引体系。
2.2.1 job_info表字段精度定义与索引优化
job_info 表承载所有任务元数据,包括Cron表达式、路由策略、执行超时等。原始MySQL脚本多采用宽泛定义(如 varchar(255) ),在Oracle中会造成空间浪费。应根据实际业务场景精细化调整字段长度。
| 字段名 | 原MySQL定义 | 优化后Oracle定义 | 依据说明 |
|---|---|---|---|
job_desc |
varchar(100) | VARCHAR2(100 CHAR) | 任务描述一般不超过百字 |
author |
varchar(64) | VARCHAR2(30 CHAR) | 用户名通常较短 |
alarm_email |
varchar(200) | VARCHAR2(128 CHAR) | Email最长约80字符,预留冗余 |
glue_type |
varchar(50) | VARCHAR2(20 CHAR) | 枚举值有限(BEAN、GLUE_JAVA等) |
cron_expression |
varchar(128) | VARCHAR2(64 CHAR) | 标准Cron最多6部分,通常<60字符 |
特别强调使用 CHAR 单位而非 BYTE ,防止多字节字符截断:
JOB_DESC VARCHAR2(100 CHAR)
同时,针对高频查询场景创建复合索引。例如,任务暂停/恢复操作常按 job_group 和 trigger_status 筛选:
CREATE INDEX IDX_JOB_GROUP_STATUS ON XXL_JOB_INFO(JOB_GROUP, TRIGGER_STATUS);
统计信息显示,该索引可使相关查询性能提升80%以上。此外,对 CREATE_TIME 建立单独索引,便于按时间范围检索历史任务。
2.2.2 executor_log大文本字段CLOB处理方案
executor_log 表用于存储每次任务执行的详细输出日志,内容可达数MB。MySQL使用 TEXT 类型处理,而Oracle应采用 CLOB 以支持更大容量与流式访问。
LOG_CONTENT CLOB
直接插入大文本可能引发内存溢出,推荐使用 DBMS_LOB.WRITEAPPEND 分段写入:
DECLARE
lob_loc CLOB;
BEGIN
INSERT INTO XXL_EXECUTOR_LOG (LOG_ID, LOG_CONTENT)
VALUES (123, EMPTY_CLOB())
RETURNING LOG_CONTENT INTO lob_loc;
DBMS_LOB.WRITEAPPEND(lob_loc, LENGTH('Step 1 complete\n'), 'Step 1 complete\n');
DBMS_LOB.WRITEAPPEND(lob_loc, LENGTH('Processing data...\n'), 'Processing data...\n');
END;
/
参数说明:
- EMPTY_CLOB() :初始化空CLOB对象。
- RETURNING ... INTO :获取刚插入行的LOB定位符。
- DBMS_LOB.WRITEAPPEND :向LOB末尾追加内容,避免一次性加载全部数据。
该方法适用于日志实时追加场景,如任务执行过程中逐步输出状态。相比一次性传参,显著降低JDBC传输压力。
2.2.3 job_config配置表默认值与约束迁移
job_config 表保存调度参数,其中 TIMEOUT 字段原定义为 INT(11) DEFAULT 0 。迁移到Oracle时需同步迁移约束:
ALTER TABLE XXL_JOB_CONFIG
ADD CONSTRAINT CK_TIMEOUT_POSITIVE
CHECK (TIMEOUT >= 0);
并通过 DEFAULT 子句保留默认行为:
MODIFY TIMEOUT NUMBER(10,0) DEFAULT 0;
此外,对于JSON格式的参数字段(如 PARAMS_JSON ),虽可用 VARCHAR2(2000) 暂存,但建议升级至 CLOB 以防超限,并添加校验触发器确保格式合法:
CREATE OR REPLACE TRIGGER TRI_VALIDATE_JSON
BEFORE INSERT OR UPDATE ON XXL_JOB_CONFIG
FOR EACH ROW
BEGIN
IF :NEW.PARAMS_JSON IS NOT NULL THEN
APEX_JSON.PARSE(:NEW.PARAMS_JSON);
END IF;
EXCEPTION
WHEN OTHERS THEN
RAISE_APPLICATION_ERROR(-20001, 'Invalid JSON format in PARAMS_JSON');
END;
/
利用Oracle内置 APEX_JSON 包解析JSON,可在入库前拦截非法内容,增强数据质量。
2.3 DML语句的PL/SQL封装实践
单纯改写SQL不足以应对高并发调度场景下的性能与稳定性需求。通过将关键DML操作封装为存储过程,结合批量处理与异常控制机制,可大幅提升系统鲁棒性。
2.3.1 批量插入性能提升(FORALL语句应用)
当批量注册执行器或导入初始任务时,逐条INSERT效率极低。Oracle提供 FORALL 语句实现真正的批量绑定:
DECLARE
TYPE t_job IS RECORD (
job_desc VARCHAR2(100),
author VARCHAR2(30)
);
TYPE t_job_table IS TABLE OF t_job INDEX BY PLS_INTEGER;
jobs t_job_table;
BEGIN
jobs(1).job_desc := 'Batch Job 1';
jobs(1).author := 'admin';
jobs(2).job_desc := 'Batch Job 2';
jobs(2).author := 'dev';
FORALL i IN 1..jobs.COUNT
INSERT INTO XXL_JOB_INFO (JOB_DESC, AUTHOR)
VALUES (jobs(i).job_desc, jobs(i).author);
COMMIT;
END;
/
FORALL 仅发送一次网络请求,由数据库内部循环执行,较传统LOOP插入快5~10倍。配合数组绑定,有效减少上下文切换开销。
2.3.2 异常捕获与事务回滚机制设计
任务状态更新涉及多个表联动,必须保证原子性。以下存储过程演示如何安全更新任务状态并记录日志:
CREATE OR REPLACE PROCEDURE SP_UPDATE_JOB_STATUS(
p_job_id IN NUMBER,
p_new_status IN NUMBER,
p_operator IN VARCHAR2
) AS
BEGIN
UPDATE XXL_JOB_INFO SET TRIGGER_STATUS = p_new_status WHERE ID = p_job_id;
INSERT INTO XXL_JOB_HISTORY (JOB_ID, STATUS, OPERATOR, OP_TIME)
VALUES (p_job_id, p_new_status, p_operator, SYSDATE);
COMMIT;
EXCEPTION
WHEN DUP_VAL_ON_INDEX THEN
ROLLBACK;
RAISE_APPLICATION_ERROR(-20002, 'Duplicate key error during status update');
WHEN OTHERS THEN
ROLLBACK;
RAISE_APPLICATION_ERROR(-20003, 'Unexpected error: ' || SQLERRM);
END;
/
通过 EXCEPTION 块精确捕获唯一键冲突等常见错误,并主动回滚事务,防止脏数据残留。
2.3.3 存储过程化封装调度状态更新逻辑
将复杂调度逻辑下沉至数据库层,可减少应用层代码复杂度。例如,设计一个统一入口过程来处理“触发→执行→回调”全流程的状态变迁:
PROCEDURE SP_TRIGGER_JOB(p_job_id IN NUMBER) IS
BEGIN
-- 检查是否允许触发
IF NOT fn_can_trigger(p_job_id) THEN
RAISE_APPLICATION_ERROR(-20004, 'Job not allowed to trigger');
END IF;
-- 更新为运行中
UPDATE XXL_JOB_INFO SET TRIGGER_STATUS = 1 WHERE ID = p_job_id;
-- 记录触发事件
INSERT INTO XXL_JOB_EVENT(LOG_ID, EVENT_TYPE, EVENT_TIME)
VALUES (SEQ_EVENT.NEXTVAL, 'TRIGGER', SYSTIMESTAMP);
COMMIT;
END;
此类封装不仅提高复用性,还便于集中审计与监控。
2.4 兼容性测试与执行计划调优
最后阶段需验证所有SQL在真实负载下的表现。使用 EXPLAIN PLAN 分析执行路径,识别全表扫描、笛卡尔积等性能反模式,并通过索引重建与统计信息更新维持最优查询计划。
2.4.1 Explain Plan分析高频SQL性能瓶颈
对典型查询生成执行计划:
EXPLAIN PLAN FOR
SELECT * FROM XXL_JOB_INFO WHERE JOB_GROUP = 1 AND TRIGGER_STATUS = 0;
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
输出若显示 TABLE ACCESS FULL ,则表明缺少有效索引,应及时补充。
2.4.2 索引重建与统计信息更新策略
定期执行以下维护脚本:
-- 更新统计信息
EXEC DBMS_STATS.GATHER_TABLE_STATS('XXL_SCHEMA', 'XXL_JOB_INFO');
-- 重建碎片化索引
ALTER INDEX IDX_JOB_GROUP_STATUS REBUILD;
建议纳入每日凌晨维护窗口,确保优化器始终基于最新数据分布做出决策。
综上所述,通过系统性的语法适配、结构优化与过程封装,XXL-JOB可在Oracle环境中实现无缝迁移,兼顾功能完整性与运行效能。
3. Oracle环境下的建表脚本(job_info、executor_log、job_config等)
在企业级分布式任务调度系统中,数据库作为核心基础设施之一,承载着任务元数据、执行日志、配置信息等关键数据的持久化职责。XXL-JOB原生设计以MySQL为默认存储引擎,在迁移到Oracle 19c或更高版本时,必须对建表脚本进行深度适配与重构。本章聚焦于Oracle环境下三张核心表—— job_info 、 executor_log 、 job_config 的建表逻辑,涵盖从表空间规划到字段定义、约束设置、索引优化及初始化策略的全流程设计。通过遵循企业级数据库最佳实践,确保系统具备高可用性、可维护性和良好的性能表现。
3.1 建表脚本总体设计原则
在正式进入具体表结构定义之前,需确立一套统一的设计规范与架构原则,以指导后续所有DDL语句的编写。这些原则不仅影响单个表的结构质量,更决定了整个调度系统的稳定性与扩展能力。
3.1.1 表空间规划与用户权限分配
Oracle数据库中合理的表空间管理是保障系统长期稳定运行的基础。建议为XXL-JOB创建独立的表空间和专用数据库用户,避免与其他业务系统共享资源造成争抢或权限混乱。
-- 创建专用表空间
CREATE TABLESPACE xxl_job_data
DATAFILE '/u01/app/oracle/oradata/ORCL/xxl_job01.dbf'
SIZE 500M AUTOEXTEND ON NEXT 50M MAXSIZE UNLIMITED
LOGGING
EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO;
-- 创建专用用户并授权
CREATE USER xxl_job IDENTIFIED BY "StrongPass123!"
DEFAULT TABLESPACE xxl_job_data
TEMPORARY TABLESPACE TEMP
QUOTA UNLIMITED ON xxl_job_data;
GRANT CONNECT, RESOURCE TO xxl_job;
GRANT CREATE VIEW, CREATE SYNONYM TO xxl_job;
逻辑分析与参数说明:
TABLESPACE xxl_job_data:专用于存放XXL-JOB相关表和索引,便于备份、迁移和性能监控。AUTOEXTEND ON NEXT 50M:自动增长机制防止因空间不足导致建表失败,提升运维弹性。SEGMENT SPACE MANAGEMENT AUTO:使用本地管理方式结合自动段空间管理(ASSM),减少碎片,提高并发插入效率。- 用户权限最小化原则:仅授予必要权限,符合安全合规要求。
流程图:用户与表空间关系模型
graph TD
A[Oracle Database Instance] --> B[Tablespace: xxl_job_data]
A --> C[User: xxl_job]
B --> D[Stores job_info Table]
B --> E[Stores executor_log Table]
B --> F[Stores job_config Table]
C -->|Owns and Accesses| D
C -->|Owns and Accesses| E
C -->|Owns and Accesses| F
style B fill:#e6f7ff,stroke:#1890ff
style C fill:#fffbe6,stroke:#faad14
该流程图清晰展示了物理存储层(表空间)与逻辑访问层(数据库用户)之间的映射关系,体现了“职责分离”与“资源隔离”的设计理念。
3.1.2 字符集统一设置(AL32UTF8)与排序规则
字符集的选择直接影响中文、特殊符号等多语言内容的正确存储与检索。Oracle推荐使用 AL32UTF8 作为数据库字符集,支持完整的Unicode编码。
-- 查询当前数据库字符集
SELECT parameter, value FROM nls_database_parameters
WHERE parameter IN ('NLS_CHARACTERSET', 'NLS_NCHAR_CHARACTERSET');
-- 预期输出:
-- NLS_CHARACTERSET AL32UTF8
-- NLS_NCHAR_CHARACTERSET AL16UTF16
若未启用 AL32UTF8 ,应由DBA在实例级别调整,不可事后修改。对于新建连接,可通过会话级设置确认:
ALTER SESSION SET NLS_LANGUAGE = 'SIMPLIFIED CHINESE';
ALTER SESSION SET NLS_TERRITORY = 'CHINA';
参数说明:
NLS_CHARACTERSET=AL32UTF8:确保VARCHAR2、CHAR等类型能正确存储中文任务名称、描述等内容。NLS_COMP=LINGUISTIC和NLS_SORT=BINARY_AI可用于实现不区分大小写和重音的查询,但需配合相应的函数索引。
| 参数 | 推荐值 | 说明 |
|---|---|---|
| NLS_CHARACTERSET | AL32UTF8 | 支持全球字符,兼容JSON、HTML等格式 |
| NLS_NCHAR_CHARACTERSET | AL16UTF16 | NCHAR/NVARCHAR2 使用 Unicode 宽字符 |
| NLS_LANGUAGE | SIMPLIFIED CHINESE / AMERICAN | 根据部署地区选择显示语言 |
| NLS_DATE_FORMAT | YYYY-MM-DD HH24:MI:SS | 统一时间格式,避免解析歧义 |
此配置保证了任务描述中的中文注释、日志内容中的堆栈信息均可无损保存,并支持跨区域团队协作。
3.1.3 表分区策略建议(按时间范围拆分日志表)
随着系统运行时间延长, executor_log 表可能迅速膨胀至千万级记录,严重影响查询性能。为此,采用 按月范围分区(Range Partitioning) 是最优解。
-- 对 executor_log 表实施按月分区
CREATE TABLE executor_log (
id NUMBER(20) NOT NULL,
job_group NUMBER(11) NOT NULL,
job_id NUMBER(11) NOT NULL,
log_content CLOB,
trigger_time DATE,
handle_code NUMBER(11),
PRIMARY KEY (id)
)
PARTITION BY RANGE (trigger_time) INTERVAL(NUMTOYMINTERVAL(1, 'MONTH'))
(
PARTITION p_init VALUES LESS THAN (TO_DATE('2024-01-01', 'YYYY-MM-DD'))
);
-- 创建本地索引以提升分区查询效率
CREATE INDEX idx_executor_log_time ON executor_log(trigger_time) LOCAL;
CREATE INDEX idx_executor_log_job ON executor_log(job_group, job_id) LOCAL;
逐行解读与逻辑分析:
PARTITION BY RANGE (trigger_time):以触发时间为分区键,适用于时间序列类数据。INTERVAL(NUMTOYMINTERVAL(1, 'MONTH')):每月自动创建新分区,无需人工干预。p_init初始化分区用于存储早期数据,之后Oracle自动派生p_202401,p_202402等。LOCAL索引确保每个分区拥有独立索引段,支持高效分区裁剪(Partition Pruning)。
场景示例:
当执行以下查询时:
SELECT * FROM executor_log WHERE trigger_time BETWEEN DATE '2024-03-01' AND DATE '2024-03-31';
优化器将只扫描对应分区,极大降低I/O开销。
3.2 核心数据表详细创建脚本
基于上述设计原则,下面逐一构建三张核心表的完整建表语句,并解释其字段选型依据与业务含义。
3.2.1 job_info任务信息表结构定义
job_info 表存储所有注册任务的基本信息,包括Cron表达式、路由策略、执行超时设置等,是调度决策的核心依据。
-- 创建 job_info 表
CREATE SEQUENCE seq_job_info START WITH 1 INCREMENT BY 1 NOCACHE;
CREATE OR REPLACE TRIGGER trg_job_info_autoinc
BEFORE INSERT ON job_info
FOR EACH ROW
BEGIN
IF :NEW.id IS NULL THEN
SELECT seq_job_info.NEXTVAL INTO :NEW.id FROM DUAL;
END IF;
END;
/
CREATE TABLE job_info (
id NUMBER(20) PRIMARY KEY,
job_group NUMBER(11) NOT NULL,
job_desc VARCHAR2(255) NOT NULL,
add_time DATE DEFAULT SYSDATE,
update_time DATE DEFAULT SYSDATE,
author VARCHAR2(64),
alarm_email VARCHAR2(255),
schedule_type VARCHAR2(16) DEFAULT 'CRON' NOT NULL,
schedule_conf VARCHAR2(128),
misfire_strategy VARCHAR2(32) DEFAULT 'DO_NOTHING',
executor_route_strategy VARCHAR2(16),
executor_handler VARCHAR2(255),
executor_param VARCHAR2(512),
executor_block_strategy VARCHAR2(16),
executor_timeout NUMBER(11) DEFAULT 0 NOT NULL,
executor_fail_retry_count NUMBER(11) DEFAULT 0 NOT NULL,
trigger_status NUMBER(4) DEFAULT 0 NOT NULL,
trigger_last_time NUMBER(20) DEFAULT 0 NOT NULL,
trigger_next_time NUMBER(20) DEFAULT 0 NOT NULL
);
代码逻辑逐行解析:
seq_job_info:序列模拟自增主键,弥补Oracle无AUTO_INCREMENT特性。trg_job_info_autoinc触发器拦截INSERT操作,自动填充ID字段。VARCHAR2(255):合理限制任务描述长度,防止单条记录过大。schedule_type枚举值如CRON,FIX_RATE,FIX_DELAY,决定调度模式。trigger_next_time存储时间戳而非DATE类型,便于Java端毫秒级处理。
| 字段名 | 类型 | 是否为空 | 默认值 | 说明 |
|---|---|---|---|---|
| id | NUMBER(20) | 否 | 序列生成 | 主键 |
| job_group | NUMBER(11) | 否 | - | 执行器组ID,关联执行器集群 |
| job_desc | VARCHAR2(255) | 否 | - | 任务描述,用于展示 |
| schedule_conf | VARCHAR2(128) | 是 | - | Cron表达式或固定频率数值 |
| executor_timeout | NUMBER(11) | 否 | 0 | 超时时间(秒),0表示不限制 |
3.2.2 executor_log执行日志表设计
该表记录每次任务执行的详细日志,包含标准输出、错误信息、耗时统计等,通常为最大数据量表。
CREATE SEQUENCE seq_executor_log START WITH 1 INCREMENT BY 1 NOCACHE;
CREATE OR REPLACE TRIGGER trg_executor_log_autoinc
BEFORE INSERT ON executor_log
FOR EACH ROW
BEGIN
IF :NEW.id IS NULL THEN
SELECT seq_executor_log.NEXTVAL INTO :NEW.id FROM DUAL;
END IF;
END;
/
CREATE TABLE executor_log (
id NUMBER(20) PRIMARY KEY,
job_group NUMBER(11) NOT NULL,
job_id NUMBER(11) NOT NULL,
executor_address VARCHAR2(255),
executor_handler VARCHAR2(255),
executor_param VARCHAR2(512),
executor_sharding_param VARCHAR2(20),
executor_fail_retry_count NUMBER(11) DEFAULT 0,
trigger_time DATE,
trigger_code NUMBER(11) NOT NULL,
trigger_msg CLOB,
handle_time DATE,
handle_code NUMBER(11),
handle_msg CLOB,
alarm_status NUMBER(4) DEFAULT 0 NOT NULL
) TABLESPACE xxl_job_data;
重点说明:
CLOB类型用于存储长文本日志,突破VARCHAR2(4000)限制。- 日志清理可通过定时JOB实现:
-- 示例:删除3个月前的日志
BEGIN
DELETE FROM executor_log WHERE trigger_time < ADD_MONTHS(SYSDATE, -3);
COMMIT;
END;
/
历史归档方案流程图
graph LR
A[executor_log 当前分区] -->|每日增量| B{是否超过阈值?}
B -- 是 --> C[归档至 Hadoop/Hive]
B -- 否 --> D[继续写入]
C --> E[压缩存储 Parquet/ORC]
D --> F[定期分析调度成功率]
3.2.3 job_config调度配置表规范化
虽然XXL-JOB本身未提供独立 job_config 表,但在复杂环境中常需扩展一张配置表用于多环境参数隔离。
CREATE TABLE job_config (
config_key VARCHAR2(128) PRIMARY KEY,
env_profile VARCHAR2(32) NOT NULL, -- dev/test/prod
config_value VARCHAR2(1024),
encrypted CHAR(1) DEFAULT 'N' CHECK (encrypted IN ('Y','N')),
description VARCHAR2(512),
last_updated DATE DEFAULT SYSDATE
);
-- 插入默认配置项
INSERT INTO job_config(config_key, env_profile, config_value, description)
VALUES ('job.retry.max.attempts', 'prod', '3', '生产环境最大重试次数');
应用场景举例:
// Java代码读取配置
String sql = "SELECT config_value FROM job_config WHERE config_key=? AND env_profile=?";
// 动态绑定 application.yml 中的 ${spring.profiles.active}
3.3 约束与索引的精细化配置
良好的索引设计直接决定SQL执行效率,尤其是在高频查询场景下。
3.3.1 唯一约束与外键关系建立
尽管Oracle支持外键,但考虑到分布式部署中可能存在的延迟同步问题,建议仅在逻辑层面维持关联,避免强外键依赖。
-- 添加唯一约束
ALTER TABLE job_info ADD CONSTRAINT uk_job_group_handler
UNIQUE (job_group, executor_handler);
-- 不建议添加外键至 executor_register 表,以防级联阻塞
| 约束名称 | 涉及字段 | 目的 |
|---|---|---|
| pk_job_info | id | 主键唯一 |
| uk_job_group_handler | job_group + executor_handler | 防止重复注册相同处理器 |
3.3.2 高频查询字段组合索引设计
针对Web控制台常见的筛选条件,建立复合索引:
-- 提升任务列表页面加载速度
CREATE INDEX idx_job_info_status_group ON job_info(trigger_status, job_group) TABLESPACE xxl_job_idx;
-- 加快日志查询响应
CREATE INDEX idx_executor_log_time_code ON executor_log(trigger_time, handle_code) TABLESPACE xxl_job_idx;
执行计划验证示例:
EXPLAIN PLAN FOR
SELECT id, job_desc FROM job_info WHERE trigger_status = 1 AND job_group = 2;
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
预期执行路径为 INDEX RANGE SCAN ,表明索引生效。
3.3.3 索引重建周期与监控告警设置
长期运行后索引可能出现碎片,影响性能。建议每月维护一次:
# Linux crontab 定时任务
0 2 * * 1 sqlplus xxl_job/StrongPass123! @rebuild_indexes.sql
-- rebuild_indexes.sql
ALTER INDEX idx_job_info_status_group REBUILD ONLINE;
ALTER INDEX idx_executor_log_time_code REBUILD ONLINE;
同时监控索引状态:
SELECT index_name, blevel, leaf_blocks, status
FROM user_indexes
WHERE table_name IN ('JOB_INFO', 'EXECUTOR_LOG');
B-Tree层级(blevel)> 3 时应考虑重建。
3.4 初始化数据导入与版本控制
3.4.1 初始管理员账号与默认执行器注册
-- 初始化用户(密码需加密)
INSERT INTO xxl_job_user(username, password, role, permission)
VALUES ('admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
-- 注册默认执行器
INSERT INTO xxl_job_group(app_name, title, address_type, address_list)
VALUES ('xxl-job-executor-sample', '示例子服务', 0, '');
注意:实际部署中应使用BCrypt或SHA-256加密密码。
3.4.2 脚本版本管理(基于Flyway或Liquibase)
推荐使用 Liquibase 实现跨环境数据库变更管理:
<!-- db.changelog-master.xml -->
<changeSet id="001-create-job_info" author="dev">
<createSequence sequenceName="seq_job_info"/>
<sqlFile path="sql/V001__create_job_info.sql"/>
<rollback>
<dropTable tableName="job_info"/>
<dropSequence sequenceName="seq_job_info"/>
</rollback>
</changeSet>
启动时自动检测并应用变更,确保各环境一致性。
4. 任务调度中心(Admin)功能详解
作为XXL-JOB分布式调度系统的核心控制中枢,任务调度中心(Admin)承担着全局任务编排、状态监控、调度决策与用户交互等关键职责。在Oracle数据库环境下,其运行稳定性与性能表现高度依赖于底层数据访问的兼容性设计以及内部组件间的协同机制。本章将深入剖析Admin模块从启动初始化到任务全生命周期管理的技术实现细节,并重点探讨其与Oracle数据库集成时的关键配置策略、MyBatis映射优化路径、调度引擎工作机制及安全权限体系构建方式。
通过本章内容的学习,读者不仅能够掌握如何在企业级Oracle环境中稳定部署和运维XXL-JOB Admin服务,还能理解其背后支撑高可用、高性能调度能力的核心架构逻辑,为后续执行器集群扩展与Web控制台深度使用奠定坚实基础。
4.1 Admin模块启动与Oracle数据源集成
当 xxl-job-admin 应用启动时,首要任务是完成与后端数据库的连接建立,确保所有持久化操作具备可靠的数据支撑。在默认情况下,XXL-JOB采用MySQL作为推荐数据库,但在金融、电信等对事务一致性要求极高的行业场景中,Oracle仍是主流选择。因此,将Admin模块适配至Oracle环境,需围绕数据源配置、连接池调优及持久层SQL语句改造三大方面进行精细化处理。
4.1.1 application-oracle.yml配置要点
为了启用Oracle数据源支持,必须在Spring Boot的配置文件中定义独立的 application-oracle.yml ,替代原有的MySQL配置。该文件应包含JDBC URL、驱动类名、用户名密码以及必要的连接参数。
spring:
datasource:
url: jdbc:oracle:thin:@//192.168.1.100:1521/ORCLCDB.localdomain
username: xxljob_user
password: EncryptedPassword@123
driver-class-name: oracle.jdbc.OracleDriver
type: com.alibaba.druid.pool.DruidDataSource
druid:
initial-size: 5
min-idle: 5
max-active: 50
max-wait: 60000
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
validation-query: SELECT 1 FROM DUAL
test-while-idle: true
test-on-borrow: false
test-on-return: false
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
filters: stat,wall
参数说明:
| 参数 | 含义 | 推荐值 |
|---|---|---|
url |
Oracle连接字符串,使用SID或Service Name | 根据实际实例配置 |
validation-query |
连接有效性检测SQL | 必须改为 SELECT 1 FROM DUAL (Oracle语法) |
max-active |
最大活跃连接数 | 建议设置为业务并发量的1.5倍 |
max-wait |
获取连接最大等待时间(毫秒) | 避免线程无限阻塞,建议≤60s |
time-between-eviction-runs-millis |
空闲连接回收检测周期 | 每分钟一次(60000ms) |
⚠️ 注意事项:
- Oracle不支持SELECT 1而需使用FROM DUAL表;
- 若启用了DRUID防火墙(wall filter),需配合白名单规则防止合法SQL被拦截;
- 密码若涉及敏感信息,建议结合Jasypt等工具加密存储。
4.1.2 Druid连接池参数调优(最大连接数、等待超时)
Druid连接池是阿里巴巴开源的高性能数据库连接池组件,在生产环境中广泛用于Java应用与Oracle的对接。针对高并发调度场景下的长连接维持与短时突发流量应对,合理的参数调优至关重要。
以下是典型调优后的Druid连接池核心参数设定及其作用分析:
| 参数 | 默认值 | 生产建议值 | 说明 |
|---|---|---|---|
initialSize |
0 | 5~10 | 初始连接数避免冷启动延迟 |
minIdle |
0 | 5~10 | 保持最小空闲连接,减少频繁创建开销 |
maxActive |
8 | 30~50 | 控制最大并发连接,防止单点压垮数据库 |
maxWait |
-1(无限) | 30000~60000 | 超时抛出异常而非永久阻塞 |
removeAbandoned |
false | true | 开启废弃连接回收 |
removeAbandonedTimeout |
300 | 600 | 连接占用超过10分钟视为泄漏 |
@Bean
public DataSource druidDataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(env.getProperty("spring.datasource.url"));
dataSource.setUsername(env.getProperty("spring.datasource.username"));
dataSource.setPassword(env.getProperty("spring.datasource.password"));
dataSource.setDriverClassName(env.getProperty("spring.datasource.driver-class-name"));
// 基础连接池配置
dataSource.setInitialSize(5);
dataSource.setMinIdle(5);
dataSource.setMaxActive(50);
dataSource.setMaxWait(60000);
// 连接有效性检查
dataSource.setValidationQuery("SELECT 1 FROM DUAL");
dataSource.setTestWhileIdle(true);
// 防止连接泄露
dataSource.setRemoveAbandoned(true);
dataSource.setRemoveAbandonedTimeout(600); // 单位秒
// SQL监控与防火墙
dataSource.setFilters("stat,wall");
return dataSource;
}
代码逻辑逐行解读:
-
setInitialSize(5):预热5个连接,提升首次请求响应速度; -
setMinIdle(5):保证至少有5个空闲连接可用,降低获取连接延迟; -
setMaxActive(50):限制总连接数不超过50,防止Oracle端资源耗尽; -
setMaxWait(60000):若所有连接都被占用,则最多等待60秒,否则抛出SQLException; -
setValidationQuery(...):每次从池中取出连接前执行此查询以验证有效性; -
setRemoveAbandoned(true):开启“遗弃连接”自动清理功能,防止程序未正确关闭Connection导致连接泄漏; -
setFilters("stat,wall"):启用统计监控(stat)和SQL防火墙(wall),便于后期排查慢查询或恶意注入。
📈 性能提示:
在Oracle RAC环境下,可进一步启用连接池的负载均衡策略,通过TNS配置实现多节点分发,提升整体吞吐能力。
4.1.3 MyBatis映射文件针对Oracle的定制修改
由于Oracle与MySQL在语法层面存在显著差异,原生XXL-JOB的MyBatis XML映射文件无法直接运行于Oracle之上。主要问题集中在分页、自增主键、函数调用等方面。
分页查询改写示例:
原始MySQL分页:
<select id="pageList" parameterType="map" resultType="XxlJobInfo">
SELECT * FROM xxl_job_info
<where>
job_group = #{jobGroup}
</where>
ORDER BY id DESC
LIMIT #{offset}, #{pagesize}
</select>
Oracle兼容版本(使用ROWNUM嵌套):
<select id="pageList" parameterType="map" resultType="XxlJobInfo">
SELECT * FROM (
SELECT TMP_PAGE.*, ROWNUM ROW_ID FROM (
SELECT * FROM xxl_job_info
<where>
job_group = #{jobGroup}
</where>
ORDER BY id DESC
) TMP_PAGE WHERE ROWNUM <= #{pagesize} + #{offset}
) WHERE ROW_ID > #{offset}
</select>
主键生成策略调整:
MySQL使用 AUTO_INCREMENT ,而Oracle需借助序列(Sequence)+触发器(Trigger)模拟自增行为。
CREATE SEQUENCE seq_xxl_job_info START WITH 1 INCREMENT BY 1;
CREATE OR REPLACE TRIGGER tri_xxl_job_info_id
BEFORE INSERT ON xxl_job_info
FOR EACH ROW
BEGIN
IF :NEW.id IS NULL THEN
SELECT seq_xxl_job_info.NEXTVAL INTO :NEW.id FROM DUAL;
END IF;
END;
/
对应的MyBatis插入语句也需移除 useGeneratedKeys="true" 属性,并显式调用序列:
<insert id="save" parameterType="XxlJobInfo" useGeneratedKeys="false">
INSERT INTO xxl_job_info (id, job_desc, add_time, update_time)
VALUES (seq_xxl_job_info.NEXTVAL, #{jobDesc}, SYSDATE, SYSDATE)
</insert>
流程图:MyBatis Oracle适配流程
graph TD
A[读取 application-oracle.yml] --> B{是否使用Oracle?}
B -- 是 --> C[加载Oracle专用Mapper XML]
B -- 否 --> D[加载默认MySQL Mapper]
C --> E[替换LIMIT为ROWNUM嵌套分页]
C --> F[禁用useGeneratedKeys]
C --> G[引入Sequence生成ID]
C --> H[修改函数如NOW()->SYSDATE]
E --> I[执行SQL通过Druid连接池]
F --> I
G --> I
H --> I
I --> J[返回结果集]
函数映射对照表:
| MySQL函数 | Oracle等价写法 | 用途 |
|---|---|---|
NOW() |
SYSDATE |
当前时间戳 |
UNIX_TIMESTAMP() |
ROUND((SYSDATE - TO_DATE('1970-01-01','YYYY-MM-DD')) * 86400) |
时间戳转换 |
CONCAT(a,b) |
a || b 或 CONCAT(a,b) |
字符串拼接 |
LIMIT m,n |
嵌套ROWNUM查询 | 分页 |
通过对MyBatis映射文件的系统性重构,可以确保XXL-JOB Admin在Oracle环境下的CRUD操作完全兼容,避免因语法错误导致服务启动失败或数据写入异常。
4.2 任务生命周期管理机制
任务的新增、暂停、恢复、删除等操作构成了完整的生命周期管理体系,是调度中心对外提供服务能力的基础。这些操作的背后涉及数据库状态变更、内存缓存刷新、调度线程通知等多个环节的协同工作。
4.2.1 任务新增、暂停、恢复的后台处理流程
当用户通过Web界面提交一个新任务时,Admin模块会经历以下完整处理链路:
@PostMapping("/add")
public ReturnT<String> add(@RequestBody XxlJobInfo jobInfo) {
int ret = xxlJobService.add(jobInfo);
if (ret > 0) {
JobScheduleHelper.getInstance().refreshJobRegistry(); // 触发调度器重载
return ReturnT.SUCCESS;
}
return ReturnT.FAIL;
}
处理流程分解:
- 前端传参校验 :包括Cron表达式合法性、路由策略、执行器地址非空等;
- 持久化入库 :调用
XxlJobInfoDao.insert(jobInfo)写入job_info表; - 触发调度器刷新 :通知
JobScheduleHelper重新加载任务列表; - 广播更新事件 :若为集群部署,通过Zookeeper或Redis发布配置变更消息;
- 返回结果给前端 :成功则跳转至任务列表页,失败则提示具体原因。
对于“暂停”与“恢复”操作,本质是对 trigger_status 字段的更新:
-- 暂停任务
UPDATE xxl_job_info SET trigger_status = 0 WHERE id = ?;
-- 恢复任务
UPDATE xxl_job_info SET trigger_status = 1 WHERE id = ?;
随后调度线程会在下一轮扫描中感知状态变化并停止/启动对应任务的触发逻辑。
生命周期状态转换表:
| 当前状态 | 可执行操作 | 新状态 | 触发动作 |
|---|---|---|---|
| 停止(0) | 启动 | 运行(1) | 加入调度队列 |
| 运行(1) | 暂停 | 停止(0) | 移出调度队列 |
| 运行(1) | 删除 | 已删除(-1) | 清理内存定时器 |
| 故障(2) | 恢复 | 运行(1) | 重置失败计数 |
4.2.2 Cron表达式合法性校验与动态加载
XXL-JOB采用Quartz风格的Cron表达式格式(共6位:秒 分 时 日 月 周),并在保存任务时进行严格校验:
try {
CronExpression.isValidExpression(jobInfo.getCronExpression());
} catch (ParseException e) {
return ReturnT.FAIL.setMessage("非法Cron表达式:" + e.getMessage());
}
一旦校验通过,该表达式会被解析为具体的下次触发时间,并交由调度线程定期比对。
✅ 示例:
0 0 12 * * ?表示每天中午12点整触发。
在任务更新后,系统不会立即重启整个调度器,而是采用 增量更新机制 :
public void update(XxlJobInfo jobInfo) {
// 更新DB
xxlJobInfoDao.update(jobInfo);
// 动态刷新单个任务
JobScheduleHelper.removeJob(jobInfo.getId());
JobScheduleHelper.addJob(jobInfo);
}
这种方式避免了全量任务重新加载带来的性能抖动,尤其适用于大规模任务环境。
4.2.3 触发器状态同步与失败重试策略
为防止网络波动或节点宕机造成任务状态失步,Admin模块内置了 心跳+状态拉取 双保险机制:
sequenceDiagram
participant Admin
participant Executor
Admin->>Executor: HTTP GET /beat (每30s)
Executor-->>Admin: 返回RUNNING/IDLE状态
Admin->>Executor: 定期POST /run 记录失败则标记为FAILING
loop 失败重试
Admin->>Executor: 第1次重试(+5s)
Admin->>Executor: 第2次重试(+30s)
Admin->>Executor: 第3次重试(+5min)
end
同时,针对任务执行失败的情况,系统支持最多三次自动重试,间隔呈指数增长,最大限度提高最终成功率。
(其余章节继续展开……)
5. 执行器集群(Executor)部署与通信机制
在分布式任务调度系统中,执行器(Executor)是实际承载任务运行的物理节点。作为 XXL-JOB 架构中的核心组成部分,执行器集群不仅承担着任务的具体执行职责,还需与调度中心(Admin)保持稳定通信、及时上报状态并接收调度指令。本章节将深入剖析执行器集群在企业级 Oracle 环境下的完整部署流程与底层通信机制,涵盖注册发现、上下文传递、多语言支持及高可用保障等关键环节。
随着微服务架构的普及和业务复杂度的提升,单一执行器已无法满足大规模定时任务的并发处理需求。因此,构建一个具备弹性伸缩能力、容错性强且通信高效的执行器集群成为系统设计的重点。尤其在基于 Oracle 数据库的企业环境中,网络延迟、连接池瓶颈以及事务一致性等问题对执行器的行为提出了更高要求。为此,必须从协议层、线程模型、序列化机制等多个维度进行精细化调优。
本章内容将以 XXL-JOB 2.4.0 版本为基础,结合 Spring Boot 框架集成实践,详细解析执行器启动时如何完成自动注册、心跳维持机制的设计原理、任务参数如何跨进程安全传递,并进一步探讨其在多语言环境下的扩展能力。最终通过高可用策略的落地,确保即使在部分节点宕机或网络波动的情况下,整体调度系统的稳定性仍可得到有效保障。
5.1 Executor注册与心跳维持流程
执行器的注册与心跳机制是整个分布式调度体系得以正常运转的基础。只有当执行器成功向调度中心注册并持续发送心跳包后,Admin 才能将其纳入调度资源池,进而分配任务。该过程涉及 HTTP 协议交互、注册信息封装、超时控制与重试逻辑等多个技术点。
5.1.1 应用启动时向Admin注册的HTTP交互细节
当执行器应用(如 xxl-job-executor-sample-springboot )启动完成后,会通过内置的 ExecutorRegistryThread 线程主动发起注册请求至调度中心 Admin 的 /registry 接口。此过程基于标准 HTTP POST 协议,使用 JSON 格式传输注册元数据。
// 示例:注册请求构造逻辑(简化版)
Map<String, Object> params = new HashMap<>();
params.put("registryGroup", "EXECUTOR");
params.put("registryKey", executorAddress); // 如 http://192.168.1.10:9999/
params.put("registryValue", appName);
HttpUtil.post(adminAddresses + "/api/registry", JSON.toJSONString(params), timeout = 3000);
代码逻辑逐行分析:
- 第1~3行:构建注册参数映射表,包含三要素:
registryGroup:注册分组类型,固定为EXECUTOR;registryKey:执行器访问地址,通常由 IP + 端口构成;registryValue:执行器名称(对应配置文件中的xxl.job.executor.appname),用于标识所属应用。- 第5行:调用
HttpUtil.post()方法发起同步 POST 请求,目标 URL 为 Admin 的注册接口路径。
该请求由 Admin 的 JobApiController.registry() 方法接收处理:
@RequestMapping("/api/registry")
public ReturnT<String> registry(@RequestBody Map<String, String> data) {
String registryGroup = data.get("registryGroup");
String registryKey = data.get("registryKey");
String registryValue = data.get("registryValue");
if (!"EXECUTOR".equals(registryGroup)) {
return ReturnT.FAILURE;
}
// 存入注册表(数据库 or 缓存)
xxlJobRegistryDao.registryUpdate(registryKey, registryValue, System.currentTimeMillis());
return ReturnT.SUCCESS;
}
参数说明:
- data :前端传入的 JSON 对象,需包含上述三个字段;
- ReturnT<String> :统一返回结构体,SUCCESS 表示注册成功;
- xxlJobRegistryDao :DAO 层对象,在 Oracle 环境下操作 XXL_JOB_REGISTRY 表。
| 字段名 | 类型 | 描述 |
|---|---|---|
| registry_group | VARCHAR2(50) | 注册分组,值为 EXECUTOR |
| registry_key | VARCHAR2(255) | 执行器地址(URL) |
| registry_value | VARCHAR2(255) | 执行器名称(appname) |
| update_time | DATE | 最近更新时间 |
注意 :Oracle 数据库中应为
update_time设置索引以加速查询,避免全表扫描影响注册性能。
sequenceDiagram
participant Executor
participant Admin
participant OracleDB
Executor->>Admin: POST /api/registry (JSON)
Admin->>OracleDB: INSERT INTO XXL_JOB_REGISTRY
OracleDB-->>Admin: 成功写入
Admin-->>Executor: HTTP 200 {code: 200, msg: null}
Executor->>Admin: 启动心跳线程(每30s一次)
该流程图展示了完整的注册生命周期,包括数据落库与响应反馈。
5.1.2 心跳包发送频率与超时判定阈值
注册成功后,执行器并不会终止动作,而是开启一个后台线程周期性地向 Admin 发送“心跳”信号,表明自身处于活跃状态。默认情况下,心跳间隔设置为 30秒 ,可在 application-oracle.yml 中通过以下配置调整:
xxl:
job:
executor:
heartbeat-interval: 30
Admin 接收到每次心跳后,会更新 XXL_JOB_REGISTRY 表中对应记录的 update_time 字段。若连续 90秒 内未收到任何心跳(即超过三次周期),则认为该执行器失联,将其从可用列表中移除。
这种“三振出局”的机制兼顾了网络抖动容忍性和故障检测效率。以下是心跳判断的核心逻辑片段:
-- 查询最近90秒内有心跳的执行器
SELECT DISTINCT registry_value
FROM XXL_JOB_REGISTRY
WHERE registry_group = 'EXECUTOR'
AND update_time >= SYSDATE - INTERVAL '90' SECOND;
| 参数 | 默认值 | 建议值(Oracle 高负载场景) |
|---|---|---|
| 心跳间隔(秒) | 30 | 15~30(视网络质量而定) |
| 超时阈值(倍数) | 3x | 可动态调整为 2x 或 4x |
| 连接超时(ms) | 3000 | 建议设为 5000 防止瞬断失败 |
在 Oracle RAC 环境下,由于可能存在读写分离延迟,建议适当延长超时阈值至 120 秒,防止误判。
5.1.3 注册失败自动重试机制设计
在实际生产环境中,网络中断、防火墙拦截、数据库锁等待等情况可能导致首次注册失败。为增强健壮性,XXL-JOB 设计了指数退避式重试机制。
其核心实现位于 ExecutorRegistryThread.run() 方法中:
while (!executorStopped) {
try {
boolean success = XxlJobExecutor.register();
if (success) {
LOGGER.info("Executor注册成功");
TimeUnit.SECONDS.sleep(heartbeatInterval);
} else {
LOGGER.warn("注册失败,{}秒后重试", retryInterval);
TimeUnit.SECONDS.sleep(retryInterval);
retryInterval = Math.min(retryInterval * 2, 60); // 最大不超过60s
}
} catch (Exception e) {
LOGGER.error("注册异常", e);
retryInterval = Math.min(retryInterval * 2, 60);
}
}
逻辑分析:
- 使用 while 循环持续尝试注册或发送心跳;
- 若失败,则休眠当前 retryInterval (初始为 3s),然后翻倍重试;
- 最大退避时间为 60 秒,防止无限增长造成资源浪费;
- 异常被捕获后不会中断线程,保证长期存活。
该机制有效提升了弱网环境下的适应能力,同时减少了因短暂故障导致的任务调度中断风险。
5.2 任务执行上下文传递与结果反馈
调度任务一旦被触发,Admin 将选择合适的执行器并通过 HTTP 协议下发任务指令。执行器接收后需还原任务上下文,执行具体逻辑,并将结果回传给 Admin。这一过程涉及参数序列化、远程调用、异常捕获与日志持久化等多个环节。
5.2.1 参数序列化与反序列化过程(JSON→Map)
当 Admin 触发任务时,会将任务 ID、参数、执行器地址等信息打包成 JSON 格式,通过 POST 请求发送至执行器的 /run 接口:
{
"jobId": 1001,
"executorHandler": "demoJobHandler",
"executorParams": "{\"batchId\": \"BATCH_20241001\"}",
"logId": 10000001,
"logDateTime": 1730380800000
}
执行器端使用 XxlJobRequest 实体类接收该数据:
public class XxlJobRequest {
private int jobId;
private String executorHandler;
private String executorParams; // JSON 字符串
private long logId;
private long logDateTime;
// getter/setter...
}
随后通过 Jackson 反序列化工具将其转换为 Map<String, Object> :
ObjectMapper mapper = new ObjectMapper();
Map<String, Object> paramMap = mapper.readValue(request.getExecutorParams(), Map.class);
注意事项:
- executorParams 虽为字符串,但内容必须符合 JSON 标准;
- Oracle 存储过程中若需调用外部脚本,可通过此 Map 注入变量;
- 建议对敏感字段加密传输,防止泄露业务信息。
5.2.2 执行结果回传协议(HTTP POST响应结构)
任务执行完毕后,执行器需立即向 Admin 提交执行结果,调用 /callback 接口:
Map<String, Object> callbackParam = new HashMap<>();
callbackParam.put("logId", logId);
callbackParam.put("handleCode", 200); // 200=成功, 500=失败
callbackParam.put("handleMsg", "执行完成,共处理100条记录"); // 最多1KB
callbackParam.put("executeTime", System.currentTimeMillis() - startTime);
HttpUtil.post(adminAddresses + "/api/callback", JSON.toJSONString(callbackParam));
Admin 接收后更新 XXL_JOB_LOG 表:
UPDATE XXL_JOB_LOG
SET handle_code = :handleCode,
handle_msg = SUBSTR(:handleMsg, 1, 1024),
execute_time = :executeTime,
trigger_time = trigger_time,
update_time = SYSDATE
WHERE log_id = :logId;
| 字段 | 类型 | 含义 |
|---|---|---|
| handle_code | NUMBER | 执行状态码 |
| handle_msg | VARCHAR2(1024) | 执行日志摘要 |
| execute_time | NUMBER | 耗时(毫秒) |
因 Oracle VARCHAR2 最大长度限制为 4000 字节(AL32UTF8 下约 1333 汉字),故
handle_msg需截断以防插入失败。
5.2.3 异常堆栈信息截取与日志落盘策略
当任务抛出异常时,执行器应捕获完整堆栈并写入本地日志文件,同时将简要错误信息回传 Admin:
try {
jobHandler.execute(paramMap);
} catch (Exception e) {
StringWriter sw = new StringWriter();
PrintWriter pw = new PrintWriter(sw);
e.printStackTrace(pw);
String stackTrace = sw.toString();
// 截取前1024字符上传
String errorMsg = stackTrace.length() > 1024 ?
stackTrace.substring(0, 1024) : stackTrace;
callback.setHandleMsg(errorMsg);
callback.setHandleCode(500);
// 同时写入本地日志
LOGGER.error("任务执行失败", e);
}
优化建议:
- 使用 Logback 配合 <rollingPolicy> 实现日志轮转;
- 定期归档 executor_log 到独立表空间,减轻主库压力;
- 结合 ELK 收集日志,便于集中检索与告警。
5.3 多语言任务支持的技术实现
XXL-JOB 不仅支持 Java 任务,还可通过脚本方式运行 Shell、Python 等非 JVM 语言任务,极大增强了平台通用性。
5.3.1 Java Bean任务的反射调用机制
Java 类型任务通过 @XxlJob("methodName") 注解注册到容器中:
@XxlJob("dataSyncJob")
public void execute(String param) throws Exception {
Map<String, Object> paramMap = parseParam(param);
dataSyncService.sync((String) paramMap.get("date"));
}
执行器启动时扫描所有带有 @XxlJob 的方法,并注册到 initJobHandlerRepository() :
Method method = bean.getClass().getDeclaredMethod(jobName);
method.setAccessible(true);
XxlJobExecutor.registJobHandler(jobName, new MethodJobHandler(bean, method));
调用时通过反射执行:
((MethodJobHandler) handler).execute(param);
5.3.2 Shell脚本执行的安全沙箱控制
Shell 任务通过 Runtime.exec() 执行:
Process proc = Runtime.getRuntime().exec(new String[]{"/bin/sh", "-c", scriptContent});
安全加固措施:
- 禁止使用 rm , shutdown , chmod 等危险命令;
- 限制脚本最大执行时间(如 30 分钟);
- 设置独立运行用户,最小权限原则。
5.3.3 Python脚本环境变量注入与依赖管理
Python 任务示例:
import os
print(f"Batch ID: {os.getenv('BATCH_ID')}")
# do something...
执行前注入环境变量:
Map<String, String> env = new HashMap<>();
env.put("BATCH_ID", paramMap.get("batchId").toString());
ProcessBuilder pb = new ProcessBuilder("python", scriptPath);
pb.environment().putAll(env);
建议配合 virtualenv 或 conda 管理依赖,避免版本冲突。
graph TD
A[Admin下发任务] --> B{任务类型?}
B -->|Java Bean| C[反射调用Spring Bean]
B -->|Shell| D[Runtime.exec("/bin/sh -c script")]
B -->|Python| E[ProcessBuilder启动解释器]
C --> F[结果回传+日志输出]
D --> F
E --> F
5.4 高可用与容错机制保障
5.4.1 失联节点自动剔除与流量切换
Admin 每隔 10 秒扫描 XXL_JOB_REGISTRY 表,清理超时记录:
DELETE FROM XXL_JOB_REGISTRY
WHERE registry_group = 'EXECUTOR'
AND update_time < SYSDATE - INTERVAL '90' SECOND;
调度时仅从存活节点中选择目标执行器,实现自动故障转移。
5.4.2 并发执行阻塞控制(串行/并行模式)
通过 @XxlJob 注解的 blockingQueue 属性控制并发策略:
@XxlJob(value = "orderSync", concurrent = false)
public void execute() { ... }
底层使用 ConcurrentHashMap<String, Semaphore> 控制同一任务实例的并发数。
5.4.3 断点续传与幂等性保证设计
对于长耗时任务(如大数据导入),可通过 jobContext.getJobId() 获取上下文,在 Oracle 中记录中间状态:
INSERT INTO JOB_PROGRESS (job_id, step, status, last_update)
VALUES (:jobId, :step, 'RUNNING', SYSDATE)
ON DUPLICATE KEY UPDATE ...
结合唯一索引与状态标记,防止重复提交。
stateDiagram-v2
[*] --> Idle
Idle --> Running: 开始执行
Running --> Paused: 用户暂停
Running --> Failed: 抛出异常
Running --> Success: 正常结束
Paused --> Running: 恢复执行
Failed --> Retry: 重试策略生效
Retry --> Running
Success --> [*]
Failed --> [*]
综上所述,执行器集群不仅是任务执行的终点,更是保障调度系统可靠性的重要防线。通过对注册、通信、容错等机制的深度优化,可在 Oracle 环境下实现高性能、高可用的分布式任务调度能力。
6. Web控制台任务管理与监控能力
6.1 任务可视化操作界面功能解析
XXL-JOB的Web控制台为开发者和运维人员提供了直观、高效的任务管理入口。其前端基于Vue.js构建,后端通过Spring MVC暴露RESTful接口,前后端分离架构确保了系统的可维护性和扩展性。
6.1.1 任务列表分页展示与条件筛选
在“任务管理”页面中,系统默认采用分页方式加载 job_info 表中的记录,每页显示10条数据。为适配Oracle数据库,其SQL查询使用 ROWNUM 进行分页控制,避免MySQL风格的 LIMIT 语法错误:
SELECT * FROM (
SELECT ROWNUM AS rn, t.* FROM (
SELECT job_id, job_desc, author, schedule_type, trigger_status
FROM xxl_job_info
WHERE job_group = :jobGroup
AND job_desc LIKE '%' || :keyword || '%'
ORDER BY job_id DESC
) t WHERE ROWNUM <= :endRow
) WHERE rn > :startRow;
参数说明:
- :jobGroup :执行器分组ID,用于定位具体微服务集群。
- :keyword :任务描述模糊匹配关键字。
- :startRow 和 :endRow :实现分页的起止行号(如第1~10行为 startRow=0 , endRow=10 )。
此外,控制台支持多维度筛选,包括:
- 按调度状态(运行中/暂停)
- 按任务负责人(author字段)
- 按报警邮箱是否配置
这些查询均建立在复合索引之上,例如在 job_info 表上创建如下索引以提升性能:
CREATE INDEX idx_status_group ON xxl_job_info(trigger_status, job_group);
6.1.2 实时日志查看与滚动刷新机制
当用户点击“查看日志”按钮时,系统发起长轮询请求获取最新执行日志。该过程涉及以下组件交互:
sequenceDiagram
participant Browser
participant Admin
participant Executor
participant DB
Browser->>Admin: GET /joblog/getLog?logId=123
Admin->>DB: 查询xxl_job_log中logId=123的记录
alt 日志未完成
DB-->>Admin: 返回部分日志 + 进度标识
Admin-->>Browser: 流式响应(chunked encoding)
Browser->>Admin: 每3秒重发请求
else 日志已完成
DB-->>Admin: 返回完整日志内容
Admin-->>Browser: 关闭连接并渲染全文
end
Note right of Executor: 执行过程中实时写入CLOB字段
日志存储于 executor_log 表的 log_content CLOB 字段中,支持最大4GB文本容量。为防止频繁读取影响性能,Admin端引入二级缓存(Redis),缓存最近5分钟活跃任务的日志片段。
6.1.3 手动触发与参数动态传入
手动触发任务调用的是 /jobapi/run 接口,提交JSON格式参数:
{
"jobId": 10,
"executorParam": "env=prod&retryCount=3",
"triggerDate": "2025-04-05 10:00:00"
}
后台处理逻辑如下:
1. 校验用户权限(RBAC)
2. 构造 TriggerParam 对象并序列化为JSON
3. 调用 ExecutorBiz.run() 远程方法(HTTP POST)
4. 记录调度日志到 xxl_job_log
此过程支持传递业务级参数(如环境变量、重试次数),由执行器应用自行解析使用。
6.2 分布式调度监控指标体系
6.2.1 调度成功率、平均耗时趋势图展示
系统通过定时聚合 xxl_job_log 表数据生成监控报表,关键SQL示例如下:
| 统计维度 | SQL语句片段 |
|---|---|
| 日成功率 | SELECT TRUNC(trigger_time) dt, AVG(CASE WHEN handle_code=200 THEN 1 ELSE 0 END) rate FROM xxl_job_log GROUP BY TRUNC(trigger_time) |
| 平均耗时 | SELECT job_id, AVG(handle_cost_time) avg_cost FROM xxl_job_log WHERE trigger_time >= SYSDATE - 7 GROUP BY job_id |
| 失败TOP5 | SELECT job_id, COUNT(*) fail_count FROM xxl_job_log WHERE handle_code != 200 AND trigger_time >= SYSDATE - 1 GROUP BY job_id ORDER BY fail_count DESC FETCH FIRST 5 ROWS ONLY |
上述结果通过ECharts渲染为折线图、柱状图等形式,支持按天、小时粒度切换。
6.2.2 执行器负载均衡状态监控
调度中心定期收集各执行器节点的运行时指标(通过 /actuator/metrics 端点),主要包括:
| 指标名称 | 数据来源 | 告警阈值 |
|---|---|---|
| activeThreads | ThreadPoolTaskExecutor.getActiveCount() | >80% |
| memoryUsedRate | MemoryUsage.getUsed() / getMax() | >90% |
| loadAverage | OperatingSystemMXBean.getSystemLoadAverage() | >CPU核心数×2 |
这些数据被持久化至 xxl_job_registry 扩展字段中,并在控制台以热力图形式呈现,便于识别热点节点。
6.2.3 数据库连接池使用率预警
集成Druid监控模块后,可实时采集Oracle数据源状态:
DataSourceStatManager dsMgr = DataSourceStatManager.getInstance();
List<DruidDataSourceStatValue> stats = dsMgr.getDataSourceList()
.stream().map(DataSourceUtils::toStatValue).collect(Collectors.toList());
监控面板展示:
- 当前活跃连接数
- 等待队列长度
- 慢SQL数量(>1s)
当连接池使用率持续超过90%达5分钟,触发企业微信/钉钉告警通知。
6.3 日志文件分析与故障定位
6.3.1 xxl-job-executor-sample-springboot.log日志结构解读
典型日志条目格式如下:
2025-04-05 10:02:33.125 [xxl-job, JobThread-15] INFO c.x.e.core.thread.JobThread - >>>>>> xxl-job execute start, param: env=test, retry=2
2025-04-05 10:02:33.150 [xxl-job, JobThread-15] DEBUG c.x.e.p.i.ServiceImpl - 开始处理订单同步...
2025-04-05 10:02:35.780 [xxl-job, JobThread-15] ERROR c.x.e.core.thread.JobThread - >>>>>> xxl-job execute error for job: java.lang.NullPointerException
可通过正则提取关键信息:
(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{3}) \[(.*?)\] (INFO|DEBUG|ERROR) (.*) - (.+)
6.3.2 常见错误码排查手册
| 错误码 | 含义 | 排查建议 |
|---|---|---|
| 502 | 执行器无法访问 | 检查网络ACL、防火墙规则、注册IP是否正确 |
| 504 | 执行超时(默认10min) | 查看GC日志、优化SQL、调整timeout参数 |
| 401 | Token认证失败 | 检查 executor.accessToken 配置一致性 |
| 429 | 请求限流 | 提升执行器QPS阈值或增加实例数 |
| 303 | 任务阻塞(串行模式) | 改为并行执行或清理积压任务 |
| 204 | 无可用执行器 | 检查执行器心跳、group绑定关系 |
| 202 | 触发失败(Misfire) | 调整调度线程数或降低任务密度 |
| 200 | 成功但业务异常 | 结合handle_msg判断实际执行结果 |
| 100 | 非法请求 | 参数缺失或格式错误 |
| 0 | 系统内部异常 | 查阅admin日志定位底层Exception |
6.3.3 GC频繁导致任务丢失的日志特征识别
在高负载场景下,若JVM频繁GC可能导致任务线程中断,典型表现如下:
2025-04-05 09:15:22.345 [JobThread-8] INFO JobThread - execute start
2025-04-05 09:15:22.350 [GC pause (G1 Evacuation Pause)] ...
2025-04-05 09:15:25.780 [Full GC (Metadata GC Threshold)] ...
...(长时间STW)
2025-04-05 09:16:10.110 [JobThread-8] INFO JobThread - execute end (missing!)
此时虽无显式异常,但任务执行时间异常延长且未返回结果。解决方案包括:
- 升级JVM至G1GC优化版本
- 设置 -XX:+UseStringDeduplication
- 调整 -Xmx 避免频繁扩容
- 引入熔断机制(Hystrix/Sentinel)
6.4 性能优化与弹性伸缩实践
6.4.1 高并发场景下线程池参数调优建议
对于大批量任务调度场景,需调整Admin端调度线程池配置:
xxl:
job:
admin:
threads: 30 # 默认10,高并发建议设为CPU核数×3
queue-capacity: 10000 # 使用有界队列防OOM
Executor端也应优化本地执行线程池:
@JobHandler("demoHandler")
public class DemoJobHandler extends IJobHandler {
private final ThreadPoolExecutor executor = new ThreadPoolExecutor(
10, // corePoolSize
100, // maxPoolSize
60L, // keepAliveTime(s)
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000),
new ThreadFactoryBuilder().setNameFormat("batch-job-thread-%d").build()
);
}
6.4.2 执行器水平扩展与Kubernetes部署集成
推荐使用Helm Chart部署执行器集群,实现自动扩缩容:
# values.yaml
replicaCount: 3
autoscaling:
enabled: true
minReplicas: 3
maxReplicas: 20
targetCPUUtilizationPercentage: 70
并通过Service注册到XXL-JOB Admin:
kubectl get pods -l app=xxl-executor --template '{{range .items}}{{.status.podIP}} {{.metadata.name}}\n{{end}}'
所有实例共享同一 appName (即 xxl.job.executor.appname ),由调度中心实现负载均衡。
6.4.3 Oracle数据库读写分离与缓存引入方案
针对高频读操作(如日志查询、任务状态获取),建议引入Redis作为二级缓存层:
@Cacheable(value = "jobInfo", key = "#jobId")
public XxlJobInfo loadById(int jobId) {
return xxlJobInfoDao.loadById(jobId);
}
@CacheEvict(value = "jobInfo", key = "#jobId")
public void update(XxlJobInfo jobInfo) {
xxlJobInfoDao.update(jobInfo);
}
同时,在Oracle侧配置ADG(Active Data Guard)实现读写分离:
- 写操作走主库( jdbc:oracle:thin:@primary-scan:1521/ORCL )
- 读操作路由至备库( jdbc:oracle:thin:@standby-scan:1521/ORCL_RO )
结合MyBatis Plugin拦截 SELECT 语句,实现透明化读写分离。
简介:XXL-JOB是一款轻量级分布式任务调度平台,其2.4.0版本针对Oracle数据库进行了SQL语法优化与兼容性增强,支持在企业级Oracle环境中稳定运行。该版本包含适配Oracle的建表脚本、核心调度模块及执行器组件,提供任务管理、分布式执行、日志追踪等功能。通过Admin控制台与Executor执行器的协同工作,开发者可实现Java、Shell、Python等类型任务的定时调度。本资源适用于需在Oracle环境下部署高可用定时任务系统的开发与运维人员,具备良好的扩展性与维护性。
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)