
深入浅出分布式系统:从原理到实践
分布式锁的核心思想是通过一个中心化的锁服务或基于特定的算法(如 ZooKeeper 的分布式锁机制、Redis 的红锁等),确保同一时刻只有一个节点能够获取到锁并操作共享资源。备份节点会定期从主节点同步数据和状态信息,当主节点故障时,备份节点可以迅速接管任务,确保服务的连续性。例如,在计算一个复杂的数学模型时,一个节点可能负责计算某个部分的中间结果,然后将结果传递给另一个节点进行后续处理。分布式系
一、分布式系统:构建现代软件的基石
简单来说,分布式系统是由一组通过网络互联的独立计算机节点组成,这些节点相互协作,以实现共同的计算目标,对外表现为一个统一的系统。
举个例子,像我们熟悉的电商平台,在双十一购物节期间,需要处理海量的用户请求、订单处理和数据存储。单台服务器根本无法应对如此庞大的任务负载。而分布式系统通过将任务分散到多个服务器节点上,实现并行处理,从而轻松应对高并发场景。
二、分布式系统的核心原理剖析
1. 任务分配与协作机制
这是分布式系统的核心运作逻辑。系统会根据一定的策略(如轮询、随机、最少连接数等),将任务合理分配到各个节点上。
具体来说,当一个任务进入系统时,首先由调度器(Scheduler)进行分析和判断。调度器就像是一个交通指挥官,它会根据当前各个节点的负载情况、资源使用率等信息,决定将任务发送到哪个节点进行处理。例如,采用轮询策略时,调度器会依次将任务分配给每个节点,确保每个节点都能均匀地处理任务。
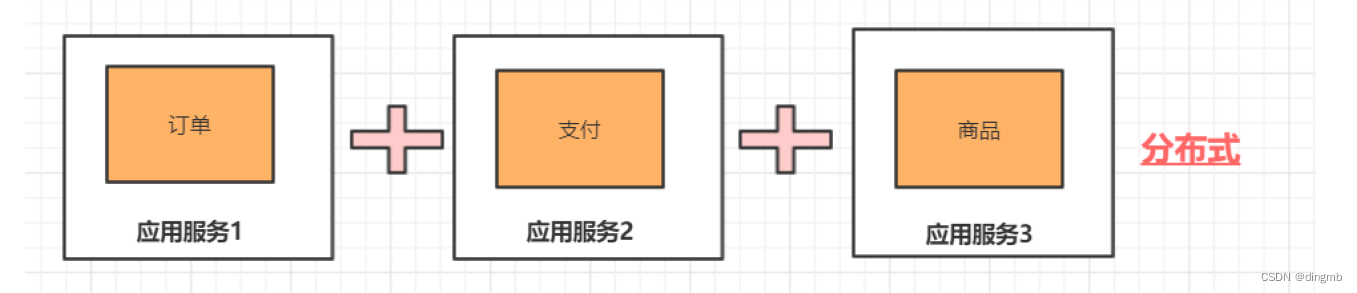
分布式与集群的区别
集群: 多个服务器做同一个事情
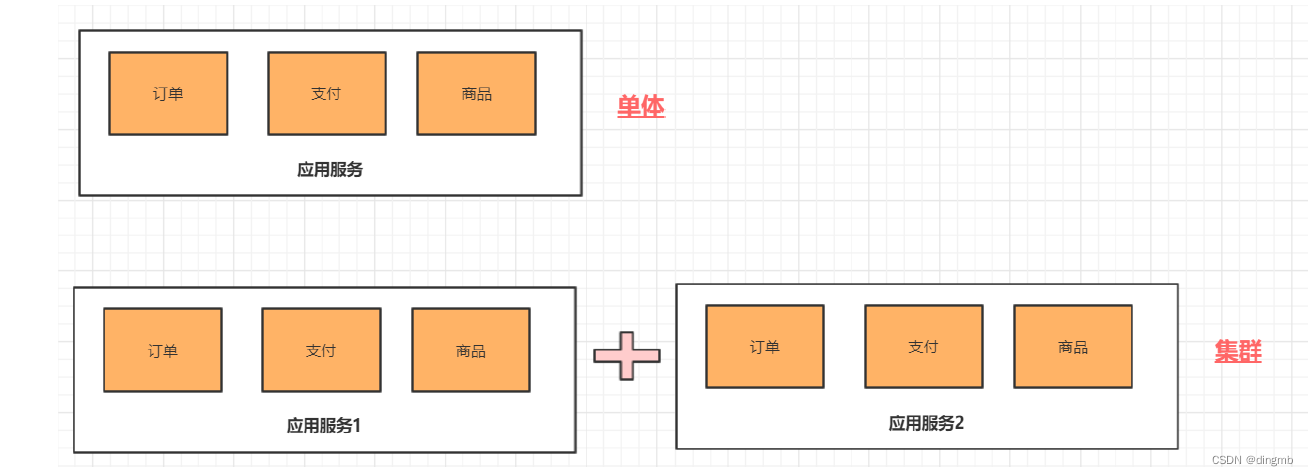
分布式: 多个服务器做不同的事情
任务分配完成后,各个节点就开始独立处理自己的任务。每个节点会执行相应的计算逻辑,如数据处理、算法运算等。在处理过程中,节点之间可能需要进行数据交互和通信,以确保任务的正确完成。例如,在计算一个复杂的数学模型时,一个节点可能负责计算某个部分的中间结果,然后将结果传递给另一个节点进行后续处理。
2. 网络通信原理
节点之间的协作依赖于高效的网络通信。分布式系统通常采用客户端 - 服务器(Client - Server)模式或对等网络(P2P)模式进行通信。
在客户端 - 服务器模式中,客户端向服务器发送请求,服务器接收请求并进行处理,最后将结果返回给客户端。例如,一个分布式文件存储系统中,客户端向文件服务器发送文件读写请求,文件服务器根据请求操作文件,并将结果返回给客户端。
对等网络模式则更加灵活,每个节点既是客户端又是服务器。节点之间可以直接进行通信和数据传输,无需通过中心服务器。例如,在一些分布式下载工具中,用户可以同时从多个其他用户节点下载文件片段,并将自己的文件片段提供给其他用户下载。
为了保证网络通信的可靠性和效率,分布式系统会使用各种网络协议,如 TCP/IP 协议、HTTP 协议等。这些协议定义了数据传输的格式、规则和错误处理机制,确保数据能够在复杂的网络环境中准确无误地传输。
3. 容错与恢复机制
分布式系统中,节点故障是不可避免的。为了保证系统的高可用性,容错与恢复机制至关重要。
首先,系统会实时监控各个节点的状态。通过心跳检测(Heartbeat)机制,节点会定期向其他节点或监控中心发送信号,表明自己处于正常运行状态。如果某个节点在一定时间内没有发送心跳信号,系统就会判断该节点可能出现了故障。
一旦检测到节点故障,系统会立即启动故障转移(Failover)机制。故障转移的核心思想是将故障节点上的任务重新分配给其他正常运行的节点。例如,通过使用备份节点来接管故障节点的任务。备份节点会定期从主节点同步数据和状态信息,当主节点故障时,备份节点可以迅速接管任务,确保服务的连续性。
同时,分布式系统还会采用数据冗余存储的方式提高容错性。例如,将数据同时存储在多个节点上,当某个节点的数据丢失或损坏时,可以从其他节点获取数据副本进行恢复。
三、分布式系统的关键技术与挑战
1. 一致性哈希(Consistent Hashing)
在分布式系统中,数据通常会被分布在多个节点上进行存储。为了实现数据的高效存储和访问,一致性哈希算法应运而生。
一致性哈希的基本原理是将数据和节点都映射到一个哈希环上。通过哈希函数计算数据的哈希值,然后在哈希环上找到顺时针方向最近的节点来存储该数据。当节点加入或离开系统时,只需要调整少量数据的存储位置,减少了数据迁移的开销。
比如,一个分布式缓存系统中,使用一致性哈希算法可以确保缓存数据在多个缓存节点之间的均匀分布。当新增一个缓存节点时,只有部分数据需要从其他节点迁移到新节点,而不会导致大量数据重新分布。
2. 分布式锁(Distributed Lock)
在多节点并发访问共享资源时,需要使用分布式锁来保证数据的一致性和正确性。
分布式锁的核心思想是通过一个中心化的锁服务或基于特定的算法(如 ZooKeeper 的分布式锁机制、Redis 的红锁等),确保同一时刻只有一个节点能够获取到锁并操作共享资源。
例如,在一个分布式任务调度系统中,多个节点可能会同时尝试更新任务的状态。通过使用分布式锁,可以确保同一任务的状态更新操作只能由一个节点执行,避免了多个节点同时修改数据导致的冲突和数据不一致问题。
3. 挑战:CAP 定理与权衡
分布式系统面临着著名的 CAP 定理的约束。CAP 定理指出,在一个分布式系统中,不可能同时完全满足以下三个特性:
-
一致性(Consistency):所有节点在同一时间看到的数据是一致的。
-
可用性(Availability):每个请求都能在有限时间内得到响应,无论数据是否成功获取。
-
分区容错性(Partition tolerance):系统在网络分区(部分节点之间无法通信)的情况下仍然能够继续运行。
在实际的分布式系统设计中,需要根据应用场景对这三个特性进行权衡。例如,对于一个金融交易系统,一致性通常更为重要,宁可牺牲部分可用性也要保证数据的准确性和一致性;而对于一个社交媒体平台,可能更注重可用性,允许在某些情况下出现短暂的数据不一致,但要确保用户能够快速发布和获取信息。
四、分布式系统代码示例:基于 Python 的分布式任务队列
以下是一个使用 Python 和 Redis 实现的简单分布式任务队列示例,用于演示分布式系统中任务的分配与执行。
1. 任务生产者代码(发送任务):
Python
复制
import redis
import time
# 连接 Redis 服务器
r = redis.Redis(host='localhost', port=6379, db=0)
def produce_task(task_id, task_data):
"""
发送任务到任务队列
:param task_id: 任务 ID
:param task_data: 任务数据
"""
task = {'task_id': task_id, 'task_data': task_data}
# 将任务添加到 Redis 队列中
r.rpush('task_queue', str(task))
print(f"任务 {task_id} 已发送到队列")
if __name__ == '__main__':
# 模拟生产多个任务
for i in range(10):
produce_task(i, f"任务数据 {i}")
time.sleep(1)2. 任务消费者代码(执行任务):
Python
复制
import redis
import ast
# 连接 Redis 服务器
r = redis.Redis(host='localhost', port=6379, db=0)
def process_task(task):
"""
处理任务逻辑
:param task: 任务内容
"""
task_id = task['task_id']
task_data = task['task_data']
print(f"正在处理任务 {task_id},数据:{task_data}")
# 模拟任务处理时间
time.sleep(2)
print(f"任务 {task_id} 处理完成")
def consume_task():
"""
从队列中获取任务并处理
"""
while True:
# 从 Redis 队列中获取任务
task_str = r.blpop('task_queue', 0)[1].decode('utf-8')
task = ast.literal_eval(task_str)
process_task(task)
if __name__ == '__main__':
consume_task()五、总结
分布式系统是现代软件架构的核心组成部分,通过多个节点的协同工作,实现了高可用性、高扩展性和高容错性。深入理解分布式系统的核心原理,包括任务分配与协作、网络通信、容错与恢复机制等,是构建可靠、高效的分布式应用的关键。
在实际应用中,我们需要根据业务需求合理选择和应用分布式系统的各项技术,同时面对 CAP 定理等约束进行有效的权衡。通过不断的学习和实践,我们能够更好地掌握分布式系统的精髓,为解决复杂的软件架构问题提供有力的支持。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)