
Hadoop之mr分布式计算机框架
Hadoop之mr分布式计算机框架Hadoop核心组件–MRHadoop 分布式计算框架1.MapReduce设计理念何为分布式计算移动计算,而不是移动数据2.计算机框架MR
·
Hadoop之mr分布式计算机框架
Hadoop核心组件–MR
- Hadoop 分布式计算框架
1.MapReduce设计理念
- 何为分布式计算
- 移动计算,而不是移动数据
2.计算机框架MR
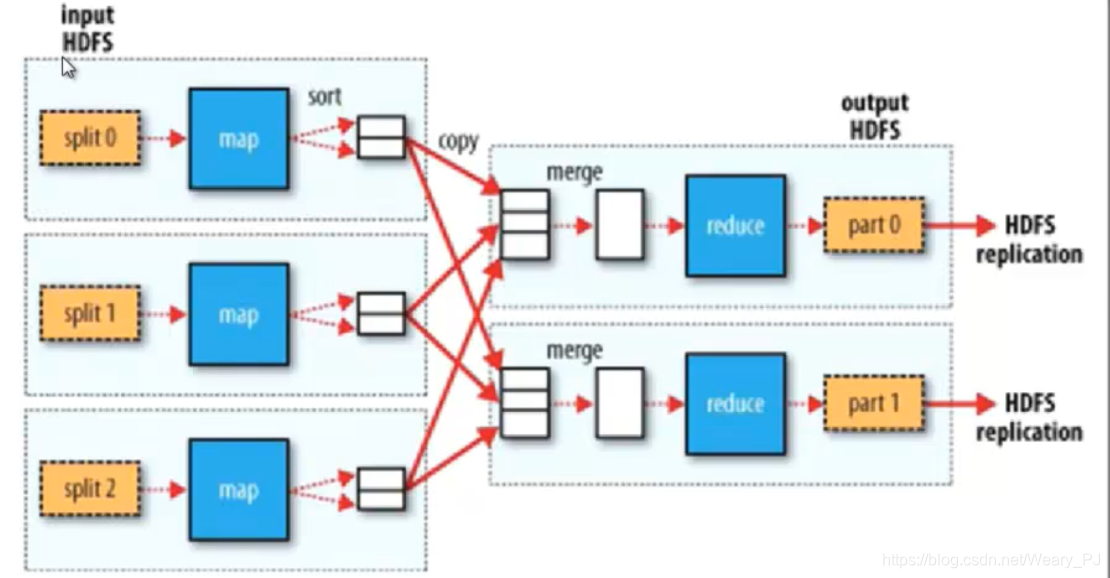
从HDFS存储的数据/文件作为输入(MR的数据来源)
对于这些数据首先要处理成一个个片段 split
每个片段都有个map线程去执行
reduce步骤
生成数据默认也保存在HDFS上
MR对很大的数据统计所有单词出现的次数的过程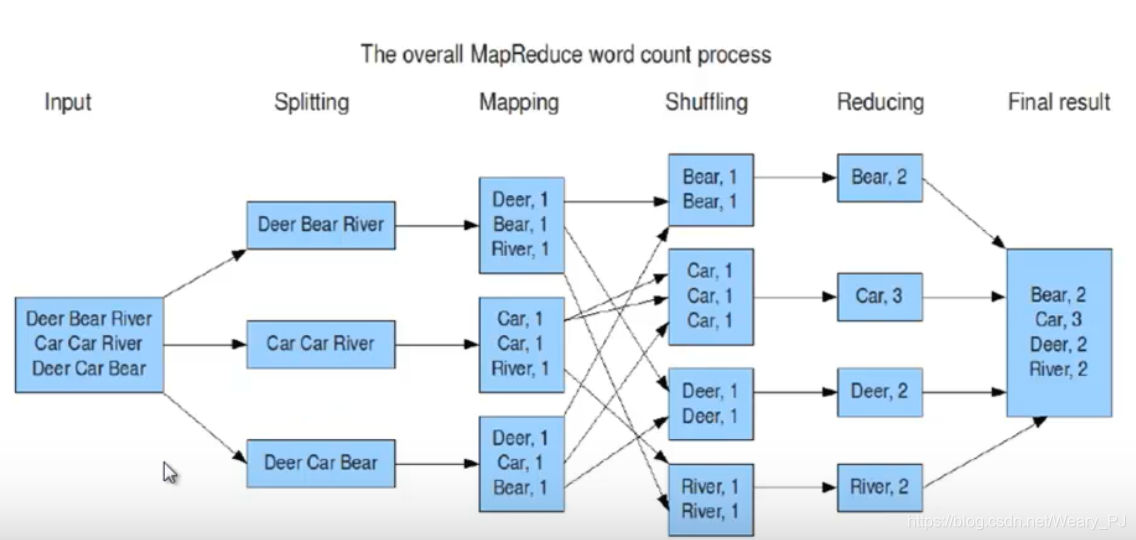
分为四个步骤
- splitting
- mapping(java线程执行分析数据片段,并发的同时执行)(根据写的代码执行)(将split中的每个单词都取出来,单词的本身作为键,1作为值)
注意:在map中出现的键值对 值只会是1 - shuffling 键值相同的数据移动到同一个block中
- reducing 对shuff的结果合并整理
reduce的个数由代码决定
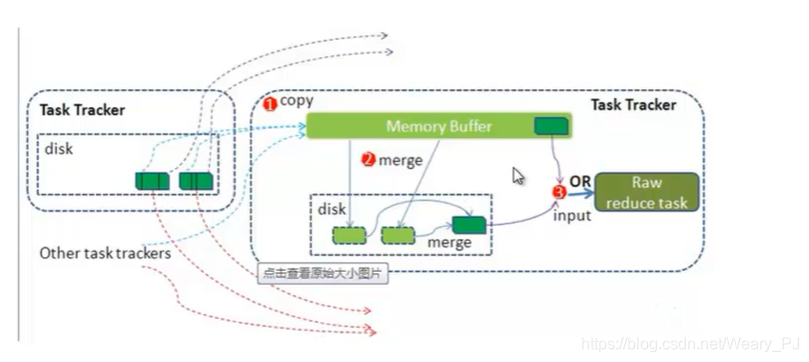
3.Hadoop计算框架Shuffler

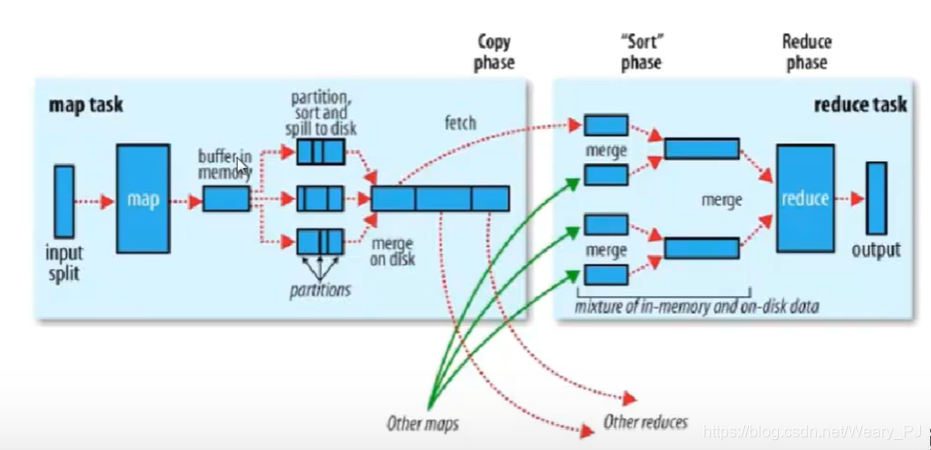
对map的输出数据(都在本地完成的)
- partition: 分区(默认的分区规则:哈希模运算,也可以由程序员自己写)
- sort 排序 字典排序
- spill to disk 溢写到磁盘


4.MapReduce的Split大小
- max.split(100M)
- min.split(10M)
- block(64M)
- max(min.split,min(max.split,block)) # 默认算法
5.MapReduce的架构

更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)