
运维必会!选型必备!主流分布式存储方案:HDFS、Ceph、MinIO 深度剖析
Ceph 是一个高度可扩展、高性能、开源的分布式存储系统,提供统一的分布式存储解决方案,支持对象存储、块存储和文件系统存储。:HDFS 通过数据块的多副本机制实现容错,默认每个数据块存储 3 个副本,分布在不同的数据节点(DataNode)上。当某个数据节点故障时,系统会自动从其他副本恢复数据,确保数据的可靠性和可用性。MinIO 是一款专为云原生和容器化环境设计的高性能、轻量级对象存储系统,以其
戳下方名片,关注并星标!
回复“1024”获取2TB学习资源!
👉体系化学习:运维工程师打怪升级进阶之路 4.0
— 特色专栏 —
MySQL / PostgreSQL / MongoDB
ElasticSearch / Hadoop / Redis
Kubernetes / Docker / DevOps
Nginx / Git / Tools / OpenStack
大家好,我是民工哥!
前面我们介绍了有关对象存储的选型参考:主流对象存储方案大比拼:本地存储、OSS、MinIO、Ceph、Apache Ozone 与 OpenIO。
在分布式存储领域,HDFS(Hadoop Distributed File System)、Ceph 和 MinIO 是三种具有代表性的技术方案,它们各有优劣,适用于不同的场景。

HDFS
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目中的核心子项目,是一个高度容错、可扩展的分布式文件系统,专为存储超大规模数据集而设计。它借鉴了 Google 文件系统(GFS)的设计思想,能够在廉价硬件上运行,并提供高吞吐量的数据访问,适用于大数据处理场景。
HDFS 的架构
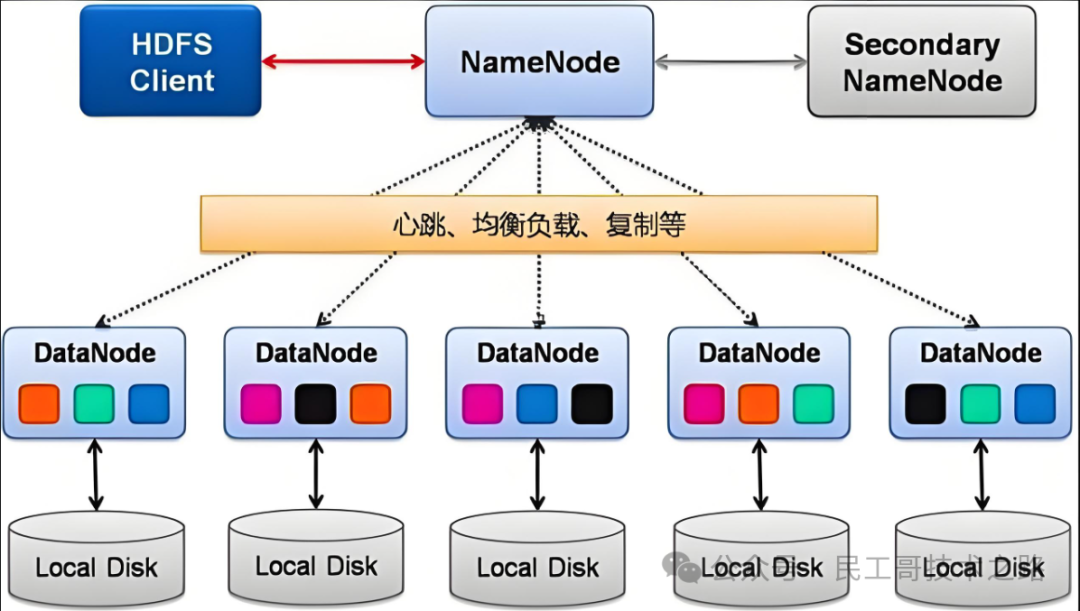
HDFS 的架构由以下组件构成:
NameNode(名称节点)
管理文件系统的命名空间,维护文件和目录的元数据(如权限、修改时间、文件块映射等)。监控数据节点的状态,协调数据块的复制和恢复。也是 HDFS 的单点故障所在,但我们可以通过 NameNode 高可用(HA)配置解决。
DataNode(数据节点)
存储实际的数据块,并定期向 NameNode 发送心跳信号和块报告,执行客户端的数据读写请求。
Secondary NameNode(辅助名称节点)
定期合并 NameNode 的元数据(FsImage 和 EditLog),防止 EditLog 过大导致 NameNode 启动缓慢。
HDFS 的核心特性
高容错性:HDFS 通过数据块的多副本机制实现容错,默认每个数据块存储 3 个副本,分布在不同的数据节点(DataNode)上。当某个数据节点故障时,系统会自动从其他副本恢复数据,确保数据的可靠性和可用性。
可扩展性:HDFS 支持横向扩展,可以通过增加数据节点来扩展存储容量和计算能力。理论上,HDFS 可以管理 PB 级甚至 EB 级的数据。
流式数据访问:HDFS 针对大文件的顺序读写进行了优化,适合批量数据处理,如 MapReduce 作业。但需要注意的它并不适合低延迟的随机读写场景。
数据局部性:HDFS 尽量将计算任务调度到数据所在的节点上,减少数据在网络中的传输,提高处理效率。
简单的数据一致性模型:HDFS 采用“一次写入,多次读取”的模型,文件一旦写入后便不可修改,简化了数据一致性管理。
HDFS 部署
集群节点:至少 1 个 NameNode、1 个 Secondary NameNode、多个 DataNode。
网络要求:节点间网络互通,推荐使用万兆以太网。
磁盘配置:DataNode 节点需配置多块磁盘,用于存储数据块。
操作系统:Linux(如 CentOS、Ubuntu)。
依赖软件:Java(推荐 OpenJDK 11+)、SSH(用于节点间通信)。
Ceph
Ceph 是一个高度可扩展、高性能、开源的分布式存储系统,提供统一的分布式存储解决方案,支持对象存储、块存储和文件系统存储。去中心化架构,基于 RADOS(Reliable Autonomic Distributed Object Store)。
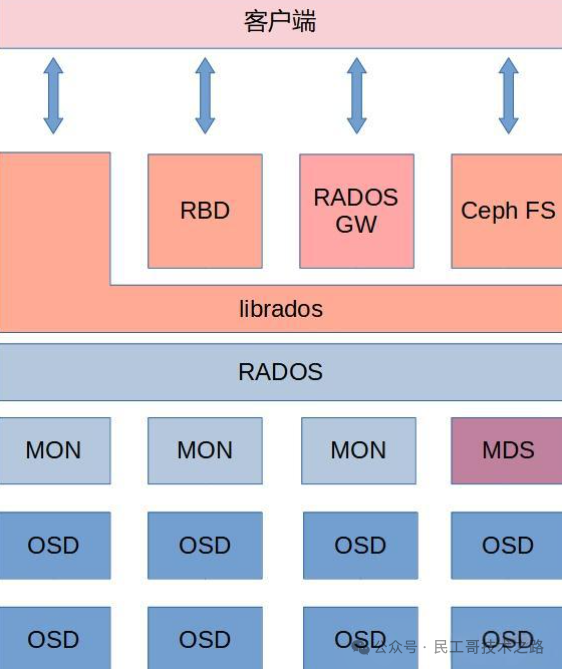
核心架构与组件
RADOS(Reliable Autonomic Distributed Object Store)
RADOS 它是 Ceph 的底层存储系统,主要负责数据的存储、复制、分布和恢复。
核心组件包括:
-
OSD(Object Storage Daemon):每个 OSD 对应一个物理磁盘,负责存储数据、处理数据复制和恢复。
-
Monitor(Mon):维护集群状态、认证信息和集群成员关系。
-
Manager(Mgr):提供集群监控、性能统计和 REST API 接口。
存储接口
-
RBD(RADOS Block Device):提供块存储服务,支持精简配置、快照和克隆,适用于虚拟机磁盘和数据库存储。
-
RGW(RADOS Gateway):提供对象存储服务,兼容 Amazon S3 和 OpenStack Swift API,适用于云存储和大规模非结构化数据存储。
-
CephFS:提供 POSIX 兼容的分布式文件系统,支持高性能计算和企业存储场景。
关键特性
高可用性与容错性:数据通过副本或纠删码(Erasure Code)实现冗余,默认 3 副本,同时也支持自定义副本数。当节点故障时,数据自动恢复,无单点故障。
弹性扩展:线性扩展存储容量和性能,支持数千个节点和 PB 级数据存储,当有新节点加入后,数据自动重新平衡。
统一存储:同一集群同时支持对象存储、块存储和文件存储多种存储类型,简化管理。
自管理:通过 CRUSH 算法自动分配数据,避免集中式元数据瓶颈。集群自动监控和修复,减少运维负担。
部署
部署方式:支持物理机、虚拟机或容器化部署。ceph-deploy(传统方式)、cephadm(容器化部署)。
硬件要求:推荐使用企业级硬盘(HDD/SSD)和万兆网络。最低配置:3 个 Monitor 节点、多个 OSD 节点。
MinIO
MinIO 是一款专为云原生和容器化环境设计的高性能、轻量级对象存储系统,以其兼容 Amazon S3 的 API 和卓越的扩展性,成为现代分布式存储场景的理想选择。
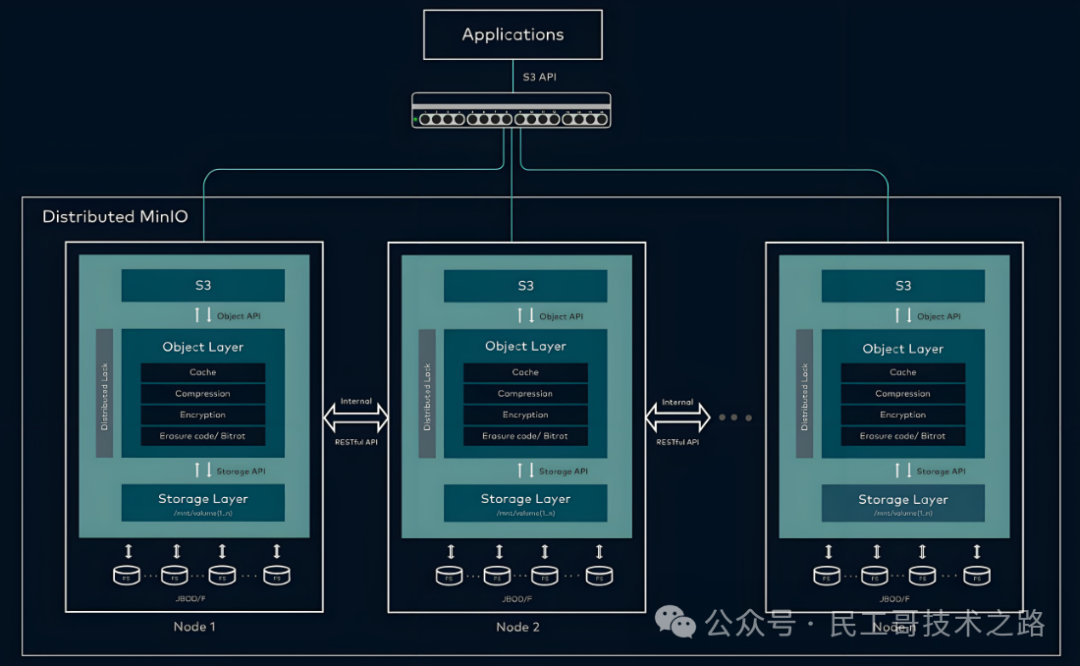
核心架构与组件
去中心化架构
MinIO 采用去中心化、无共享架构,所有节点平等参与数据存储和访问,无需中心节点协调,提升系统可用性和扩展性。
一致性哈希算法
用于数据分布和负载均衡,确保数据均匀分布在各个节点上,同时支持节点的动态增减,减少数据迁移开销。
存储服务器(Storage Nodes)
每个 MinIO 节点是独立的存储服务器,具备数据存储和访问能力。节点间无主从之分,所有节点平等参与数据存储和访问,提升系统可用性和扩展性。
集群管理器(Cluster Manager)
负责管理存储集群,包括节点加入/离开、数据均衡和迁移等操作,确保数据在节点间的一致性和系统可靠性。
客户端库(Client Libraries)
提供多种编程语言的客户端 SDK,支持与存储服务器的交互,方便用户上传、下载和管理对象数据。
锁管理器(Lock Manager)
采用无主节点的分布式锁管理机制,确保并发操作中的数据一致性,避免数据竞争和冲突。
核心特性
高性能与低延迟:基于分布式架构,利用多核 CPU 和 SSD 实现并行读写,支持高吞吐量与低延迟的数据访问。通过纠删码技术(Erasure Code)在多节点间分布数据,确保即使集群中有部分节点故障,数据仍可完整恢复。
轻量级与云原生支持:单二进制文件部署,资源占用低,且易于扩展。与 Kubernetes、Docker 等容器化平台无缝集成,支持 Helm Chart 自动化部署。
高可用性与数据保护:支持数据的复制和备份,提供跨节点或跨地域的冗余存储。内置纠删码功能,可承受多个节点或驱动器故障,确保数据持久性。
S3 兼容性与生态集成:完全兼容 Amazon S3 API,现有 S3 应用程序无需修改即可迁移至 MinIO。支持与 AWS KMS、Hashicorp Vault 等密钥管理服务集成,提供服务器端和客户端加密。
部署
单机模式:适用于开发和测试环境,资源占用低,但存储容量有限。
分布式模式:生产环境推荐模式,支持多节点集群部署,数据分散存储在多个驱动器或服务器上,提供高可用性和数据保护。
NAS 网关模式:将 Amazon S3 兼容性添加到现有 NAS 存储中,实现传统存储与云存储的无缝集成。
功能与特性对比
| 特性 | HDFS | Ceph | MinIO |
|---|---|---|---|
| 存储类型 |
文件系统存储 |
对象存储、块存储、文件系统存储 |
对象存储 |
| 数据冗余 |
三副本机制 |
可配置副本数或纠删码 |
纠删码(默认 4+2 配置) |
| 扩展性 |
有限扩展(数千节点) |
高扩展性(支持 PB 级存储) |
高扩展性(按需扩展) |
| 性能 |
高吞吐量,适合批量处理 |
高性能,低延迟 |
高性能,支持高并发 |
| 兼容性 |
专为 Hadoop 设计 |
支持多种接口(S3、Swift、iSCSI 等) |
完全兼容 S3 API |
| 运维复杂度 |
较高(需管理 NameNode) |
较高(需管理多个组件) |
较低(单二进制文件部署) |
| 生态支持 |
深度集成 Hadoop 生态系统 |
支持 OpenStack、Kubernetes 等 |
云原生友好,支持 Kubernetes |
适用场景
HDFS
-
适用场景:大数据处理、日志存储、数据仓库。
-
优势:与 Hadoop 生态系统无缝集成,适合批量数据处理。
-
劣势:不适合小文件存储,实时读写性能较低。
Ceph
-
适用场景:云计算、虚拟化、大数据存储、企业级存储。
-
优势:统一的存储平台,支持多种存储类型,高扩展性。
-
劣势:部署和运维复杂度较高,资源占用较大。
MinIO
-
适用场景:云原生应用、容器存储、数据湖、备份与归档。
-
优势:轻量级、高性能、易扩展,完全兼容 S3 API。
-
劣势:主要支持对象存储,功能相对单一。
优缺点总结
HDFS
-
优点:高可靠性、高吞吐量、与 Hadoop 深度集成。
-
缺点:不适合小文件存储,实时读写性能差,NameNode 单点故障风险。
Ceph
-
优点:功能全面、高扩展性、高性能、支持多种存储类型。
-
缺点:部署和运维复杂,资源占用大,学习曲线陡峭。
MinIO
-
优点:轻量级、高性能、易扩展、完全兼容 S3 API、云原生友好。
-
缺点:主要支持对象存储,功能相对单一,社区支持相对较弱。
选型建议
-
如果需要与 Hadoop 生态系统深度集成,且主要处理批量数据,HDFS 是最佳选择。
-
如果需要统一的存储平台,支持多种存储类型,且对扩展性和性能有较高要求,Ceph 是更合适的选择。
-
如果需要轻量级、高性能的对象存储,且希望与云原生应用无缝集成,MinIO 是理想的选择。
👍 如果你喜欢这篇文章,请点赞并分享给你的朋友!

公众号读者专属技术群
构建高质量的技术交流社群,欢迎从事后端开发、运维技术进群(备注岗位,已在技术交流群的请勿重复添加微信好友)。主要以技术交流、内推、行业探讨为主,请文明发言。广告人士勿入,切勿轻信私聊,防止被骗。
扫码加我好友,拉你进群


超越 Xshell!号称下一代终端神器,太好用了,好用到抽耳光都不愿放手
还在用千篇一律的 Windows 程序?来试试这款颜值与性能兼具的开源神器吧!
Docker 命令大全:启动、停止、重启、备份、Docker compose,都帮你总结好了
主流对象存储方案大比拼:本地存储、OSS、MinIO、Ceph、Apache Ozone 与 OpenIO
告别 Docker 依赖!是时候拥抱 Dockerless 了
再有谁说不会 k8s 四种 Service 类型!就把这个给他扔过去

PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!
更多推荐


 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)