
多机多卡分布式训练(Distributed Data DataParallel, DDP)安装踩坑记录
最近在做目标跟踪的训练时,需要对backbone做一个在imagenet上的预训练模型。众所周知,140GB+的imagenet数据集上训练网络很是考验算力。刚开始在单机双卡(2080Ti)上试了一下,1个epoch需要6个小时,跑完100 epoch大约100*6/24=25天。瞬间放弃单机多卡,将目光放在了多机多卡训练,特撰文记录这段时间的工作,方便以后查询。一、准备工作因为之前配置单机的深度
最近在做目标跟踪的训练时,需要对backbone做一个在imagenet上的预训练模型。众所周知,140GB+的imagenet数据集上训练网络很是考验算力。刚开始在单机双卡(2080Ti)上试了一下,1个epoch需要6个小时,跑完100 epoch大约100*6/24=25天。瞬间放弃单机多卡,将目光放在了多机多卡训练,特撰文记录这段时间的工作,方便以后查询。
一、准备工作
因为之前配置单机的深度学习环境时,备份了许多安装包,所以后续大多数都是离线安装
安装包目录:
-
cuda_10.2.89_440.33.01_linux.run
-
cudnn-10.2-linux-x64-v8.0.1.13.tgz
-
nccl-repo-ubuntu1804-2.7.5-ga-cuda10.2_1-1_amd64.deb
-
Anaconda3-2020.02-Linux-x86_64.sh
-
torch-1.8.1-cp36-cp36m-manylinux1_x86_64.whl
-
torchvision-0.9.1-cp36-cp36m-manylinux1_x86_64.whl
-
pycharm-community-2021.1.tar.gz
对backbone需要增加参数(分类数num_classes)和全连接层:
-
x = self.avgpool(p4)
-
x = torch.flatten(x, 1)
-
x = self.fc(x)
二、深度学习环境配置
1.集群:5台电脑各有1张卡,共5张卡,都为2080Ti
PS:因为多机多卡训练是将数据集均分和每训练完一个epoch后传递梯度等参数进行平均,所以每台电脑都要配置深度学习和代码环境!!!
2.系统:本来5台电脑都装上了win10
-
首先在win10上装Ubuntu18.04系统。参考的是:
 https://www.cnblogs.com/masbay/p/11627727.html
https://www.cnblogs.com/masbay/p/11627727.htmlps:如果装完双系统,发现启动时没有ubuntu选项。参考:
 https://blog.csdn.net/chekongfu/article/details/84872841
https://blog.csdn.net/chekongfu/article/details/84872841-
装完系统更新一下sudo,sudo apt-get update
-
sudo apt-get install make
-
sudo apt-get install gcc(本来我的nvidia驱动适配的是gcc7.3,可我发现gcc7.5也没什么大碍)
3.Nvidia显卡驱动(离线安装)
4.安装cuda及cudnn
首先安装cuda10.2
sudo sh cuda_10.2.89_440.33.01_linux.run安装完毕后,配置一下环境变量,并将其写入到 ~/.bashrc 的尾部和/etc/profile尾部:
sudo vim ~/.bashrc 如果电脑没装vim,可以
sudo gedit ~/.bashrc然后在文件末尾添加
export PATH="/usr/local/cuda-10.2/bin:$PATH"
export LD_LIBRARY_PATH="/usr/lcoal/cuda-10.2/lib64:$LD_LIBRARY_PATH"保存关闭后source文件使配置生效:
source ~/.bashrc在 /etc/profile末尾添加这两句的方法和.bashrc一样
然后安装cudnn8.0.1
解压安装包,然后
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*5.安装Anaconda
sh Anaconda3-2020.02-Linux-x86_64.shconda 换国内的镜像源:
6.nccl库安装
sudo dkpg -i nccl-repo-ubuntu1804-2.7.5-ga-cuda10.2_1-1_amd64.deb
sudo apt update
sudo apt install libnccl2 libnccl-dev7.安装pycharm,并设置快捷方式
8.按照磁盘IO信息查看工具
sudo apt-get sysstat
iostat -m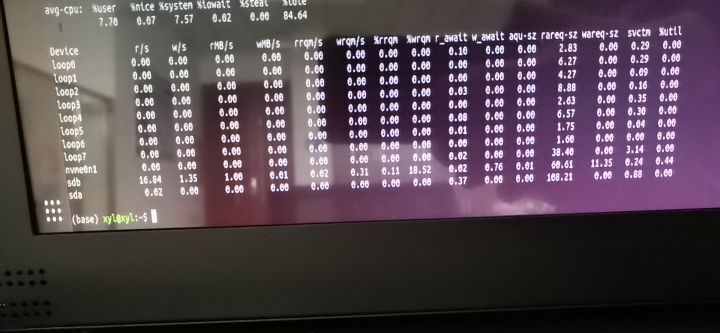
三、代码环境配置
代码:
base model第二弹:使用pytorch分布式训练在ImageNet上训练ResNet - 知乎下列代码均在pytorch1.4版本中测试过,确认正确无误。 分布式训练代码我们仍然在ImageNet上训练ResNet50,但这次使用pytorch的nn.parallel.DistributedDataParallel分布式训练。训练中其他超参数仍然和base model… https://zhuanlan.zhihu.com/p/144565571本来终端不显示训练的过程,在生成的日志log显示。我修改了一下logger的显示级别。
https://zhuanlan.zhihu.com/p/144565571本来终端不显示训练的过程,在生成的日志log显示。我修改了一下logger的显示级别。
位置: pytorch-ImageNet-CIFAR-COCO-VOC-training-master\public\imagenet\utils.py line15
logging.basicConfig(level=logging.INFO) https://github.com/zgcr/simpleAICV-pytorch-ImageNet-COCO-training
https://github.com/zgcr/simpleAICV-pytorch-ImageNet-COCO-training1.torch==1.4.0
2.torchvision==0.5.0
3.python==3.6.9
4.numpy==1.17.0
5.opencv-python==4.1.1.26
6.tqdm==4.46.0
7.thop
8.Cython==0.29.19
9.matplotlib==3.2.1
10.apex==0.1
-
创建虚拟环境
conda create -n imagenet python=3.6.9-
然后对pip换镜像源
-
离线安装pytorch:
pip install torch和torchvision的绝对路径
-
其它的都是pip install
-
apex混合精度训练库安装
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --no-cache-dir ./四、分布式的电脑配置
-
设置静态IP地址
五台电脑IP地址分别为:192.168.56.111~115
组成局域网后有的电脑可以上互联网,有的不行。
-
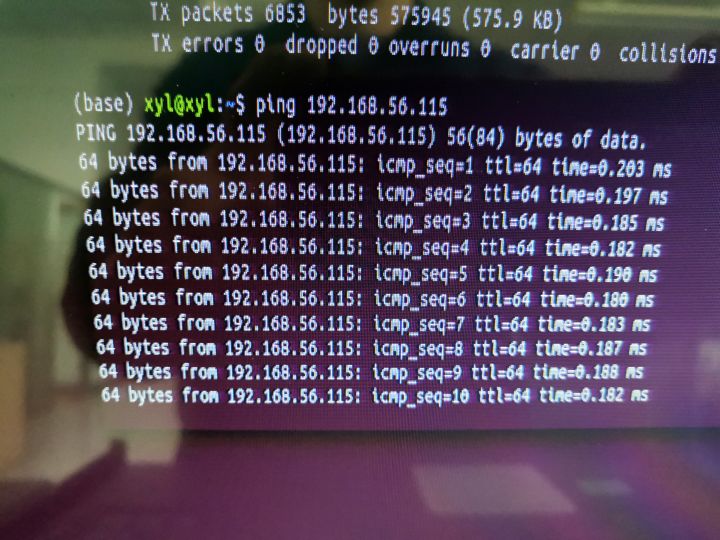
测试是否组成局域网
ifconfig 查看电脑IP
ping 另外电脑的IP地址
2.共享home里面的文件夹(共享其它磁盘里的文件夹,权限不够)
-
首先设置要共享文件夹的电脑
 https://jingyan.baidu.com/article/2f9b480dd15f4241cb6cc2d8.html
https://jingyan.baidu.com/article/2f9b480dd15f4241cb6cc2d8.html-
其它要访问共享文件夹的电脑
在Ubuntu计算机上打开"主文件夹“,然后选择网络下的”连接到服务器“。在服务器地址中输入”smb://目标ip“
在 other location的服务器地址栏输入 smb:\\192.168.56.113(192.168.56.113为有共享文件夹的电脑静态IP地址)
五、分布式训练imagenet
分布式训练原理参考:
-
准备数据集imagenet
-
更改代码里的数据集路径
-
运行代码(貌似电脑数量为奇数会报error)
参考torch.distributed.launch.py设置:四台电脑的命令依次为(以第一台192.168.56.111为主机):
python -m torch.distributed.launch --nnodes=4 --node_rank=0 --nproc_per_node=1 --master_addr 192.168.56.111 --master_port 29500 train.py --per_node_batch_size 24
python -m torch.distributed.launch --nnodes=4 --node_rank=1 --nproc_per_node=1 --master_addr 192.168.56.111 --master_port 29500 train.py --per_node_batch_size 24
python -m torch.distributed.launch --nnodes=4 --node_rank=2 --nproc_per_node=1 --master_addr 192.168.56.111 --master_port 29500 train.py --per_node_batch_size 24
python -m torch.distributed.launch --nnodes=4 --node_rank=3 --nproc_per_node=1 --master_addr 192.168.56.111 --master_port 29500 train.py --per_node_batch_size 24
PS:
-
--nnodes为总的节点数即电脑数量;
-
--node_rank为电脑的全局序号,rank=0的电脑必须是主机;
-
--nproc_per_node为每个电脑上的进程数量,一般一个GPU为一个进程;
-
--master_addr和--master_port为主机的IP地址和空闲端口地址;
-
train.py为通过launch.py启动的代码文件;(在后面的才是train.py的参数)
-
--per_node_batch_size为每个节点的batch size。
总进程数:world_size = args.nproc_per_node * args.nnodes
六、训练心得
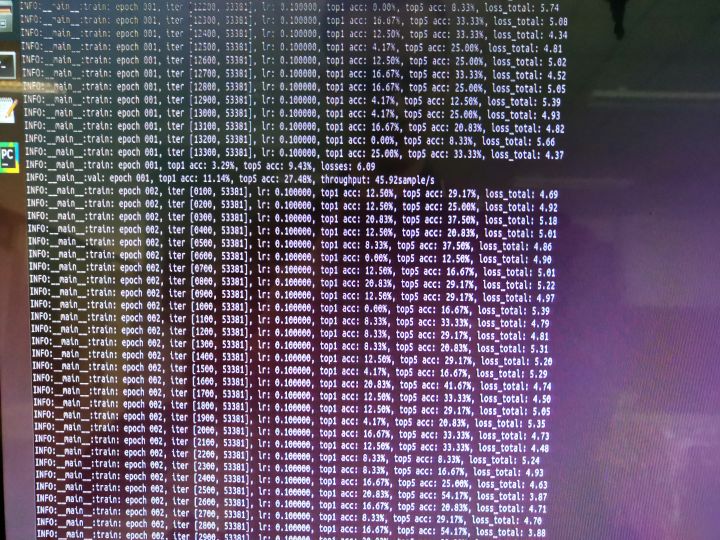
- 每个电脑都会保存权重文件,都是一样的参数,所以用哪一个都可。DDP原理应该就是将多台电脑在均分的数据集上进行分布式训练的梯度平均,再输入给各个电脑继续训练。(数据集均分,独立训练,计算平均梯度再独立训练)
- 迭代次数减少至原来的1/4
- 但是训练速度大大变慢
-
硬盘IO成为瓶颈 --> 通过iostat命令,查询硬盘读写速度为1MB/s,应该不足以成为瓶颈
-
或许是多个机器之间的通信耗费时间
最后通过测试每次迭代的时间计算100个epoch的时间发现:
多机多卡的训练网络resnet50-SA-DSI的速度结果如下:

apex混合精度训练(每次迭代的速度变慢,但bs可以调大)
sync_bn跨卡同步BN层(训练速度变慢)
最终采用apex+bs64的多机多卡训练
后记
感谢上述各位大佬分享的文章!自己,一个什么都不懂的小白,逐渐对多机多卡DDP有了一定的理解。虽然结果差强人意、远远没达到我的预期,但是掌握了多机多卡分布式训练也算是研究生生涯一大成就!由于笔者水平有限,文章中存在许多不专业、甚至错误的地方,欢迎批评指正!
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)