
一文读懂Spring Cloud Sleuth:分布式链路追踪利器
Spring Cloud Sleuth的核心价值:快速排障:通过TraceID串联分布式日志性能洞察:精确统计各服务处理耗时架构治理:可视化服务依赖关系通过简单的依赖引入和配置,开发者即可获得生产级的链路追踪能力。结合Zipkin等可视化工具,Sleuth成为微服务可观测性体系的重要基石。
·
一、Sleuth是什么?
Spring Cloud Sleuth是Spring Cloud生态中的分布式链路追踪组件,专为解决微服务架构中的调用链追踪问题而生。它通过自动生成和传递唯一请求标识,将分散在不同服务中的日志串联成完整的调用链路,帮助开发者快速定位跨服务的问题。
核心能力
- 自动埋点:对HTTP请求、消息队列、Feign/RestTemplate等通信方式自动注入追踪信息
- 上下文传递:通过Trace ID和Span ID标识请求链路,支持线程池、异步调用等场景
- 可视化分析:与Zipkin等工具集成,生成调用拓扑图和耗时统计
二、Sleuth有什么用?
1. 故障快速定位
当请求涉及多个服务时,通过Trace ID可快速关联各服务日志,精确定位故障节点。
示例场景:
用户下单请求依次经过网关 → 订单服务 → 库存服务 → 支付服务。当支付失败时,通过Trace ID可立即查看各服务状态。
2. 性能瓶颈分析
统计每个服务(Span)的耗时,识别系统瓶颈。
3. 服务依赖梳理
自动生成服务调用拓扑图,清晰展示服务间依赖关系。
三、快速上手Sleuth
环境准备(Spring Boot 3.x)
<!-- pom.xml -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>3.1.9</version>
</dependency>基础示例代码
1. 服务A(调用方)
@RestController
public class ServiceAController {
private final RestTemplate restTemplate;
public ServiceAController(RestTemplate restTemplate) {
this.restTemplate = restTemplate;
}
@GetMapping("/start")
public String startWorkflow() {
// 调用服务B
String result = restTemplate.getForObject(
"http://localhost:8081/process", String.class);
return "Trace: " + result;
}
}2. 服务B(被调用方)
@RestController
public class ServiceBController {
@GetMapping("/process")
public String process() {
// 获取当前Trace信息
Span span = SleuthUtils.getCurrentSpan();
return "TraceID: " + span.context().traceId();
}
}查看日志输出
2024-02-20 14:30:45.123 INFO [service-a,7e2585c7f5e1a363,7e2585c7f5e1a363] 12345 --- [nio-8080-exec-1] c.e.ServiceAController : Calling service B
2024-02-20 14:30:45.456 INFO [service-b,7e2585c7f5e1a363,2d1a8c3f4b6e5a79] 12346 --- [nio-8081-exec-2] c.e.ServiceBController : Processing request日志格式说明:
[应用名,TraceID,SpanID] 自动添加到日志中,实现跨服务日志串联
四、高级用法:集成Zipkin可视化
1. 添加Zipkin依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>2. 配置Zipkin服务地址
spring:
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
probability: 1.0 # 采样率(1.0=100%)3. 启动Zipkin Server
docker run -d -p 9411:9411 openzipkin/zipkin4. 查看可视化界面
访问http://localhost:9411,可以看到完整的调用链路:
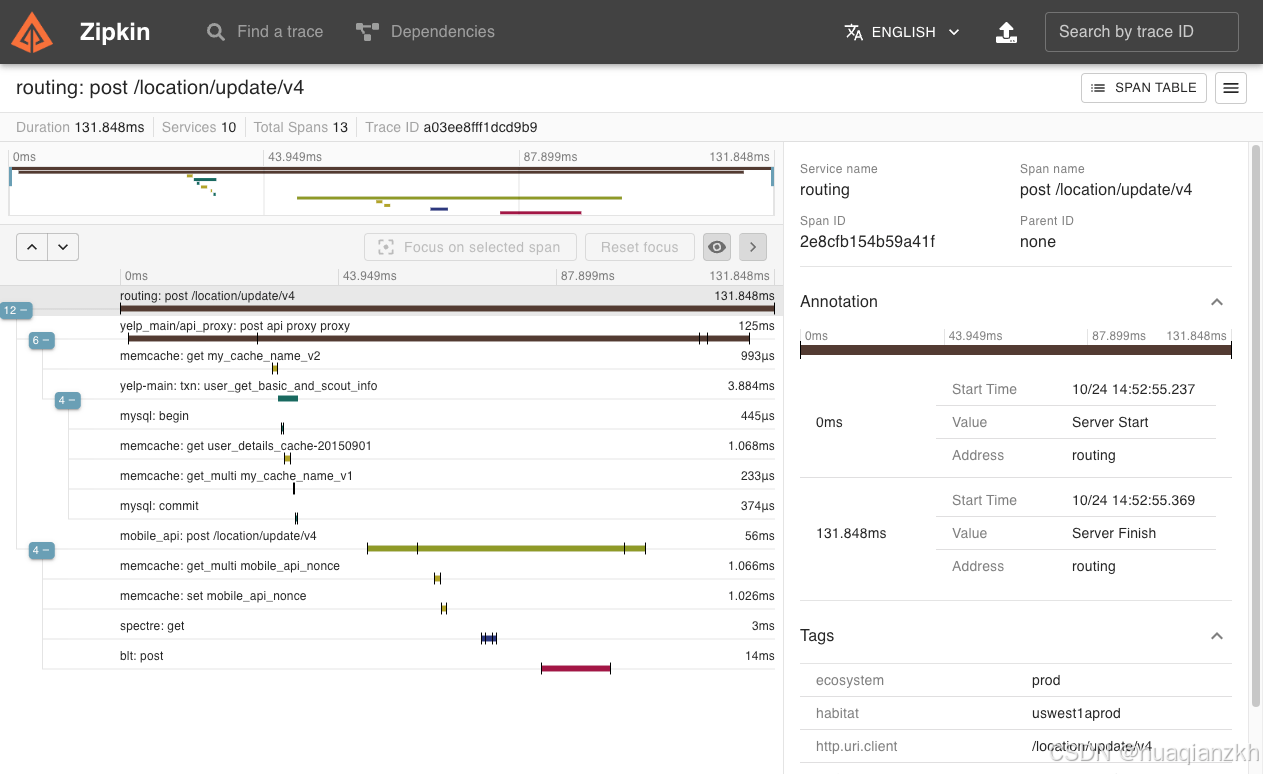
五、生产实践建议
1. 采样策略配置
# 生产环境推荐动态采样
spring.sleuth.sampler.rate=100 # 每秒最大采样数2. 自定义Span信息
@Autowired private Tracer tracer;
void businessOperation() {
Span span = tracer.nextSpan().name("custom_operation");
try (SpanInScope ws = tracer.withSpan(span.start())) {
// 业务逻辑...
span.tag("order_type", "VIP");
} finally {
span.end();
}
}3. 异步调用处理
@Async
public CompletableFuture<String> asyncCall() {
// 手动传递上下文
Span parentSpan = tracer.currentSpan();
return CompletableFuture.supplyAsync(() -> {
try (SpanInScope ws = tracer.withSpan(parentSpan)) {
return restTemplate.getForObject("http://service-c", String.class);
}
});
}总结
Spring Cloud Sleuth的核心价值:
- 快速排障:通过TraceID串联分布式日志
- 性能洞察:精确统计各服务处理耗时
- 架构治理:可视化服务依赖关系
通过简单的依赖引入和配置,开发者即可获得生产级的链路追踪能力。结合Zipkin等可视化工具,Sleuth成为微服务可观测性体系的重要基石。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)