
重点:HDFS的文件读写流程+简讲HDFS分布式文件系统
在单台计算机上存储文件,存在容量限制、性能低和可靠性低的问题。
目录
一、文件系统的分类
1. 单机文件系统
在单台计算机上存储文件,存在容量限制、性能低和可靠性低的问题。
2. 网络文件系统
通过网络共享文件,解决了部分存储容量问题,但仍存在性能和可靠性问题。
3. 分布式文件系统
多台服务器组成集群,将大文件分成小块存储在不同服务器上,采用副本机制保证可靠性。
二、HDFS架构
1. 主要组件
NameNode(主节点):管理文件系统命名空间、维护元数据、处理客户端请求。
DataNode(数据节点):存储数据块、执行数据块操作、定期报告状态。
SecondaryNameNode(辅助节点):定期合并镜像文件,作为NameNode的冷备份。
2. 特点
支持大文件存储、高容错性、简单一致性模型、高效的数据访问等。
三、HDFS的文件读写流程
1. 写入流程
客户端发起请求
NameNode进行权限检查
文件被分块
建立数据传输管道
数据块写入和确认
2. 读取流程
客户端请求读取文件
NameNode检查权限
按就近原则读取数据块
合并所有数据块
四、HDFS的健壮性机制
心跳机制:定期检查节点状态
副本机制:维护多个数据副本
数据完整性校验:确保数据正确性
安全模式:保护系统状态
快照:数据备份和恢复
五、HDFS的Shell操作 常用命令包括
ls:查看目录信息
mkdir:创建目录
du:查看文件大小
mv:移动/重命名文件
cp:复制文件
rm:删除文件
put:上传文件
get:下载文件
cat:查看文件内容
★重点:HDFS的文件读写流程
★一、客户端向HDFS中写文件的具体流程
以下图为例讲解:
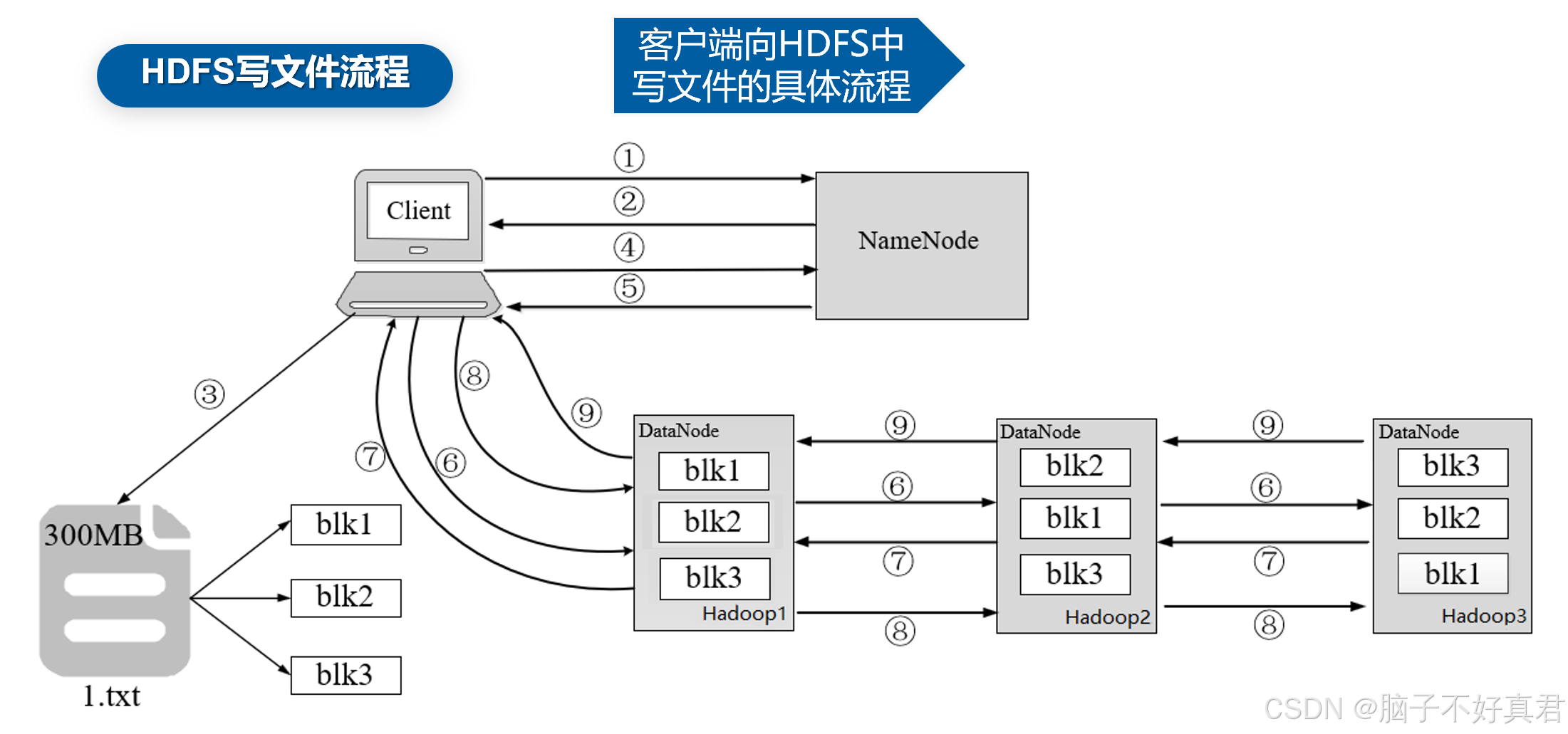
以300MB大小的1.txt文件为例,介绍HDFS写文件流程:
(1)客户端发起上传1.txt文件到指定目录的请求,与NameNode建立通信。
(2)NameNode检查客户端是否有上传文件的权限,以及文件是否存在。
(3)客户端根据分块策略对文件1.txt进行切分,形成3个Block,分别是blk1、blk2和blk3。(每块128MB,最后一块不足128MB也单独为一块)
(4)客户端向NameNode请求上传第一个Block,即blk1。
(5)NameNode根据副本机制和机架感知向客户端返回可上传blk1的DataNode列表。
(6)客户端从NameNode接收到blk1上传的DataNode列表,并与虚拟机建立管道。
(7)Hadoop3向Hadoop2汇报管道建立成功,Hadoop2与Hadoop1汇报管道建立成功;Hadoop1与客户端汇报管道建立成功,客户端与所有DataNode列表中的所有DataNode都建立了管道。
(8)客户端开始传输blk1,传输过程是以流式写入的方式实现。
1)将blk1写入到内存中进行缓存。
2)将blk1按照packet(默认为64K)为单位进行划分。
3)将第一个packet通过管道发送给Hadoop1。
4)Hadoop1接收完第一个packet之后,客户端会将第二个packet发送给Hadoop1,同时Hadoop1通过管道将第一个packet发送给Hadoop2。
5)Hadoop2接收完第一个packet之后,Hadoop1会将第二个packet发送给Hadoop2,同时Hadoop2通过管道将第一个packet发送给Hadoop3。
6)依次类推直至blk1上传完成。
(9)Hadoop3向Hadoop2发送blk1写入完成的信息,Hadoop2向Hadoop1发送blk1写入完成的信息最后,Hadoop1向客户端发送blk1写入完成的信息。
客户端成功上传blk1后,重复第4~9步的流程,依次上传blk2和blk3,最终完成1.txt文件的上传。

★二、客户端从HDFS中读文件的流程
以下图为例讲解:
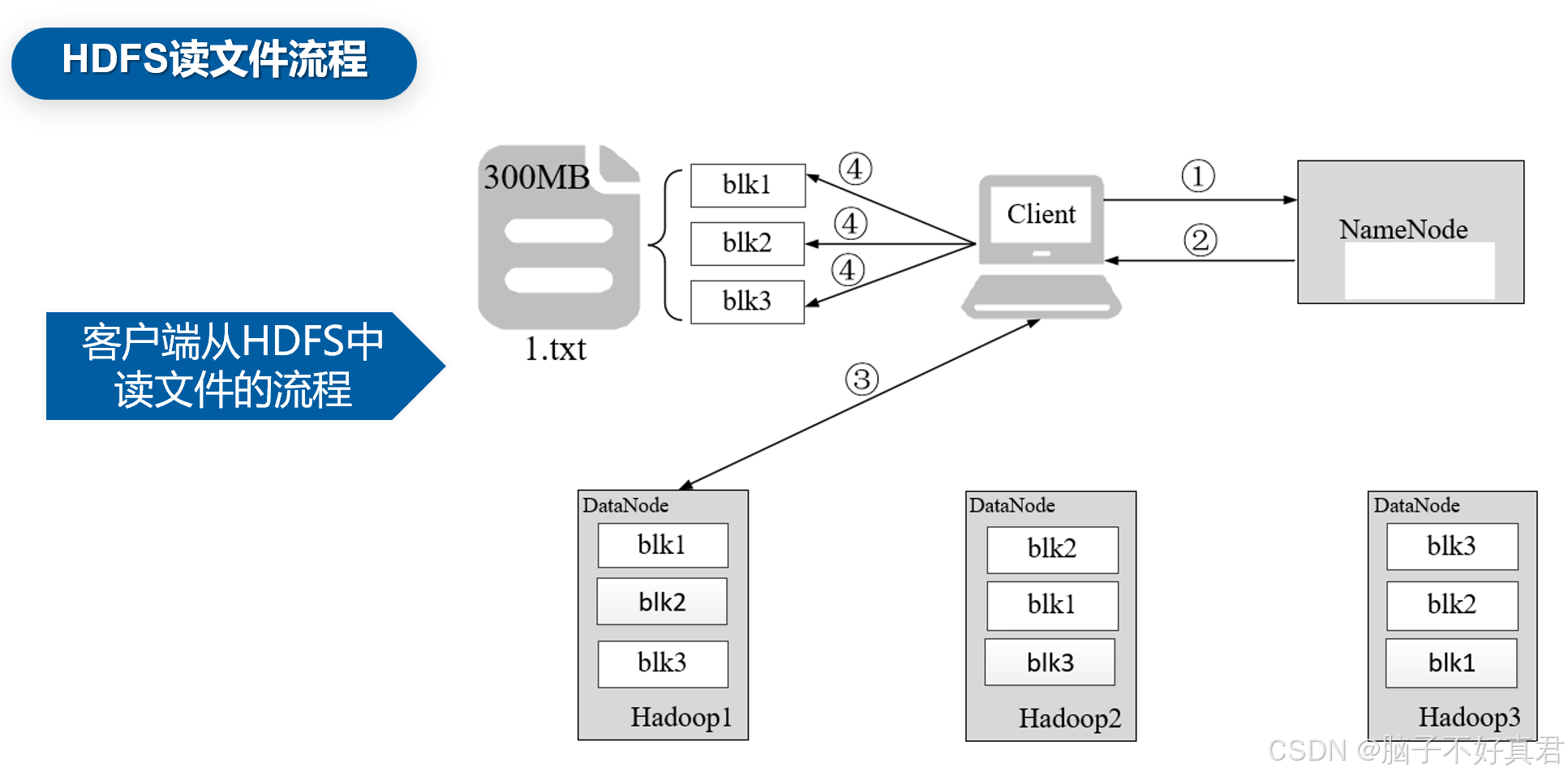
(1)客户端发起读取1.txt文件的请求,与NameNode建立通信。
(2)NameNode检查客户端是否有读取文件的权限,以及文件是否存在。
(3)客户端按照就近原则从NameNode返回的Block列表读取Block。
(4)客户端将读取所有的Block按照顺序进行合并,最终形成1.txt文件。

更多推荐


 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)