
内核级支持的分布式存储ceph
一:什么是cephceph是一种分布式存储系统, Ceph可以将多台服务器组成一个超大集群,把这些机器中的磁盘资源整合到一块 儿,形成一个大的资源池(支持PB级别),然后按需分配给客户端应用使用。我们之前讲过的FastDFS也是一个分布式的存储系统,但是FastDFS是一个弱一致性存储,而Ceph是一个强一致性存储。下面是ceph的一些特点:,称之为统一存储2.采用CRUSH 算法,数据分布均衡,
目录
有了块设备接口存储和文件系统接口存储,为什么还整个对象存储呢?
一:什么是ceph
ceph是一种分布式存储系统, Ceph可以将多台服务器组成一个超大集群,把这些机器中的磁盘资源整合到一块 儿,形成一个大的资源池(支持PB级别),然后按需分配给客户端应用使用。我们之前讲过的FastDFS也是一个分布式的存储系统,但是FastDFS是一个弱一致性存储,而Ceph是一个强一致性存储。下面是ceph的一些特点:
1.支持三种存储方式:对象存储,块存储,文件存储接口,称之为统一存储
2.采用CRUSH 算法,数据分布均衡,并行度高,不需要维护固定的元数据结构
3.数据具有强一致性,确保所有副本写入完成后才返回确认,适合读多写少的场景
4.去中心化,没有固定的中心节点,集群扩展灵活
二:块存储,文件存储,对象存储
下面我们讲一下三种存储:
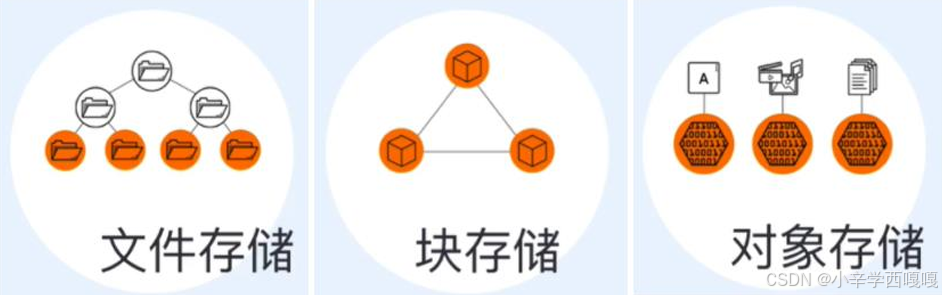
文件存储:对于文件存储,我们还是很常见的,在linux中,我们访问一个文件,需要知道这个文件的具体路径,才可以去访问:/home/xin/nihao.txt。操作的对象是文件和文件夹。存储协议是NFS,SAMBA,POSIX等。我们的FastDFS就是这一类的。
块存储:块存储也就是我们使用的硬盘一类,我们将数据拆分成快,块是一段标准长度的字节或比特。操作对象是磁盘,协议是SCSI等,在SCSI协议中主要的命令接口有read/write等。我们linux中也有一些挂在的磁盘如:/dev/bda等。
对象存储:
1:把数据全部分解成成为“对象”的离散单元,并保持在单个存储空间中。对象存储,顾名思义,就是在云端,可以存放任意对象的存储服务。这里的“对象”指的 是任意的二进制对象,保存到云上通常是以二进制文件的形式。
2:对象存储,本质是一个网络化的服务,调用方通过高层的API 和SDK 来和它进行交互。 不管是面向外部公开互联网服务,还是和内部应用程序对接,对象存储都是通过提供像 HTTP 这样的网络接口来实现的。http post/ get put 对象存储内本身不存在一个真正的文件系统,而是接近一个键值(Key-Value)形式的存 储服务。
3:对象存储的具有巨大容量的存储能力,并能不断水平扩展。对象存储能够轻松地容纳上 PB 的超大容量数据。
4:对象存储中的数据组成对象存储呈现出来的是一个“桶”(bucket),你可以往“桶” 里面放“对象(Object)”。这个对象包括三个部分:Key、Data、Metadata。每个桶都有自己的存储类别、访问权限、所属区域等属性,用户可以在不同区域创 建不同存储类别和访问权限的桶,并配置更多高级属性来满足不同场景的存储诉求 。
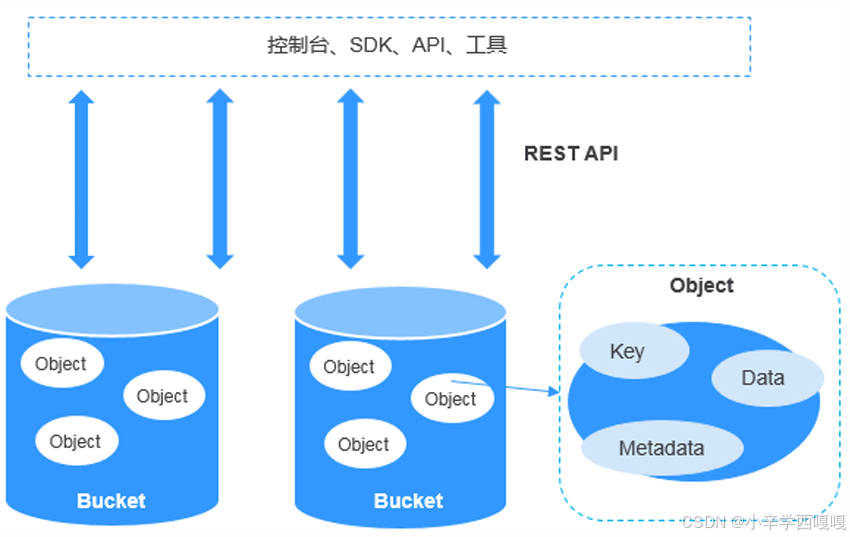
5:Object的变量
Key:可以理解文件名,是该对象的全局唯一标识符(UID)。 Key是用于检索对象,服务器和用户不需要知道数据的物理地址,也能通过它找到对象。这 种方法极大地简化了数据存储。我们使用一个URL网址进行访问这个数据。如果该对象被设置为“公开”,所有互联网用户都可以通过这个 地址访问它。
Data:也就是用户数据本体。
Metadata :叫做元数据,它是对象存储一个非常独特的概念。 元数据有点类似数据的标签,标签的条目类型和数量是没有限制的,可以是对象的各种描 述信息。
三:ceph的架构
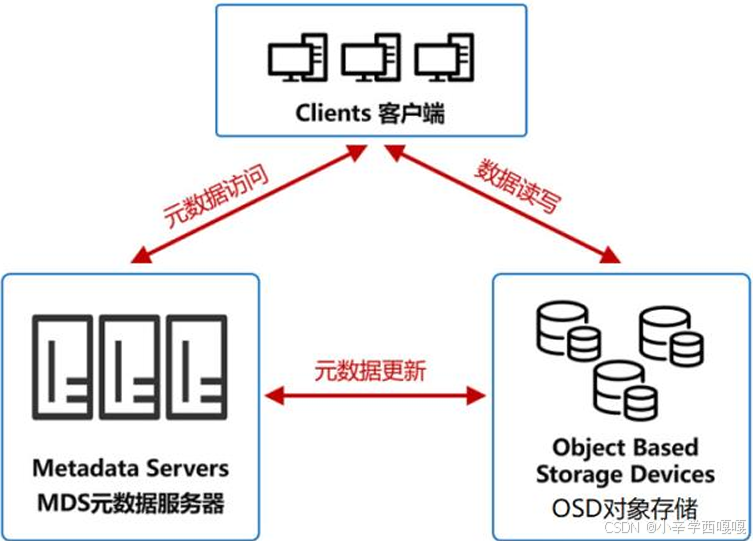
OSD 对象存储设备
这是对象存储的核心,具有自己的CPU、内存、 网络和磁盘系统。它的主要功能当然是存储数 据。同时,它还会利用自己的算力,优化数据 分布,并且支持数据预读取,提升磁盘性能。
MDS元数据服务器
它控制Client和OSD的交互,还会管理着限额 控制、目录和文件的创建与删除,以及访问控制权限。
Client客户端
提供文件系统接口,方便外部访问。
对象存储的优点:
容量无限大
1:对象存储的容量可以是EB级以上。EB有多大?大家的硬盘普遍是TB级别。1EB约等于 1TB的一百万倍
2:集群可以水平扩容
数据安全可靠
1:对象存储采用了分布式架构,对数据进行多设备冗余存储(至少三个以上节点),实现异地容灾和资源隔离
2:根据云服务商的承诺,数据可靠性至少可以达到99.999999999%(11个9)(强一致性)
对象存储的应用场景
费用高-标准类型:移动应用| 大型网站| 图片分享| 热点音视频 湖北汽车降价
低频访问类型:移动设备| 应用与企业数据备份| 监控数据| 网盘应用
费用低-归档类型:各种长期保存的档案数据| 医疗影像| 影视素材 机械硬盘
四:Ceph的三种存储接口
1:块存储接口
我们通过查看Linux中所有的块存储:
ls /dev
sda sda2 sdb sdb1 hda rdb1 rdb2我们可以看到有很多种类型的块存储,sda,sdb,hda等,他们是对应SATA接口的硬盘。而rdb1,和rdb2是ceph提供出来的接口(rdb是可靠的自主分布式对象存储)。但是我们其他硬盘是通过数据线连接的硬盘,而ceph提供的接口是通过网络连接的。当我们向rdb设备写入数据的时候,会被最终存储到ceph集群的这块区域中。
2:文件系统接口
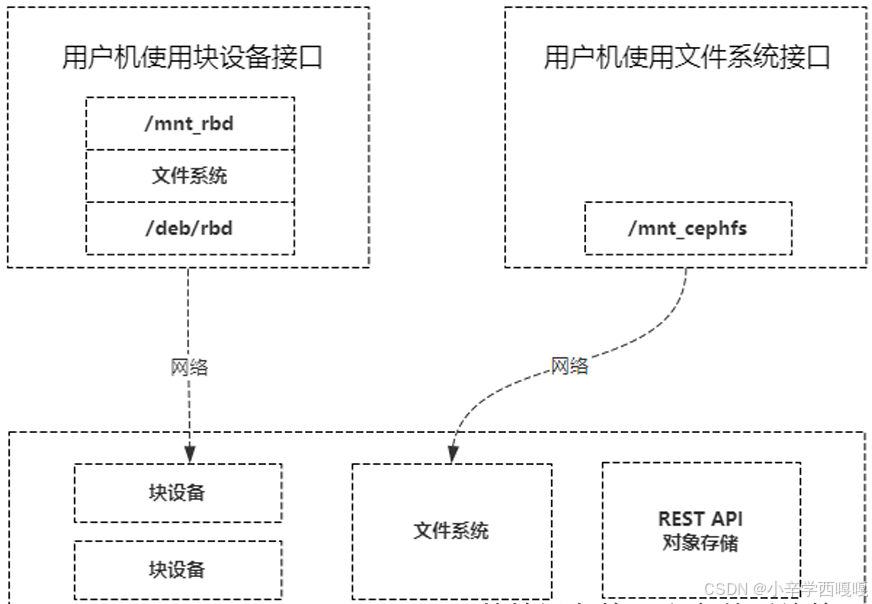
Ceph有了块设备接口,在块设备上完全可以构建一个文件系统,那么Ceph为什么还需要文件系统接口呢? 主要是因为应用场景的不同,Ceph的块设备具有优异的读写性能,但不能多处挂载同时读写, 目前主要用在OpenStack上作为虚拟磁盘,而Ceph的文件系统接口读写性能较块设备接口差, 但具有优异的共享性。
3:对象存储接口
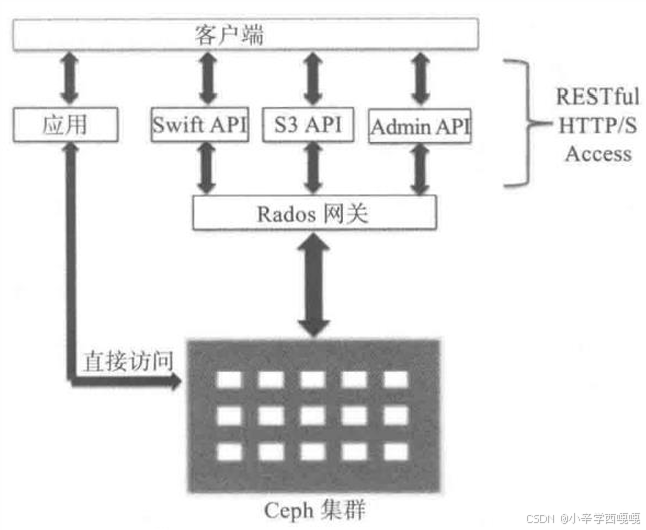
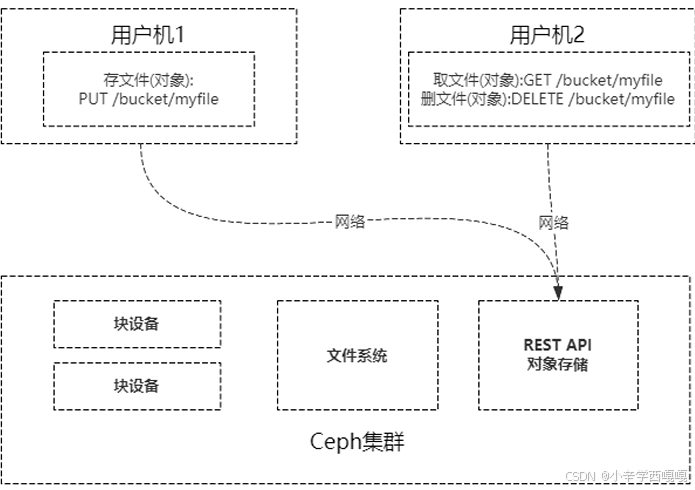
有了块设备接口存储和文件系统接口存储,为什么还整个对象存储呢?
1:Ceph的块设备存储具有优异的存储性能但不具有共享性,而Ceph的文件系统具有共 享性然而性能较块设备存储差,对象存储能权衡存储性能和共享性。
2:文件存储、对象存储的管理也是在ceph集群。 块设备的客户机管理。
对象存储为什么性能会比文件系统好?
1:对象存储组织数据的方式相对简单,只有bucket(桶)和对象两个层次(对象存储在bucket 中),对对象的操作也相对简单。
2:而文件系统存储具有复杂的数据组织方式,目录和文件层次可具有无限深度,对目录和文件的操作也复杂的多,因此文件系统存储在维护文件系统的结构数据时会更 加繁杂,从而导致文件系统的存储性能偏低。
五:ceph核心架构组件
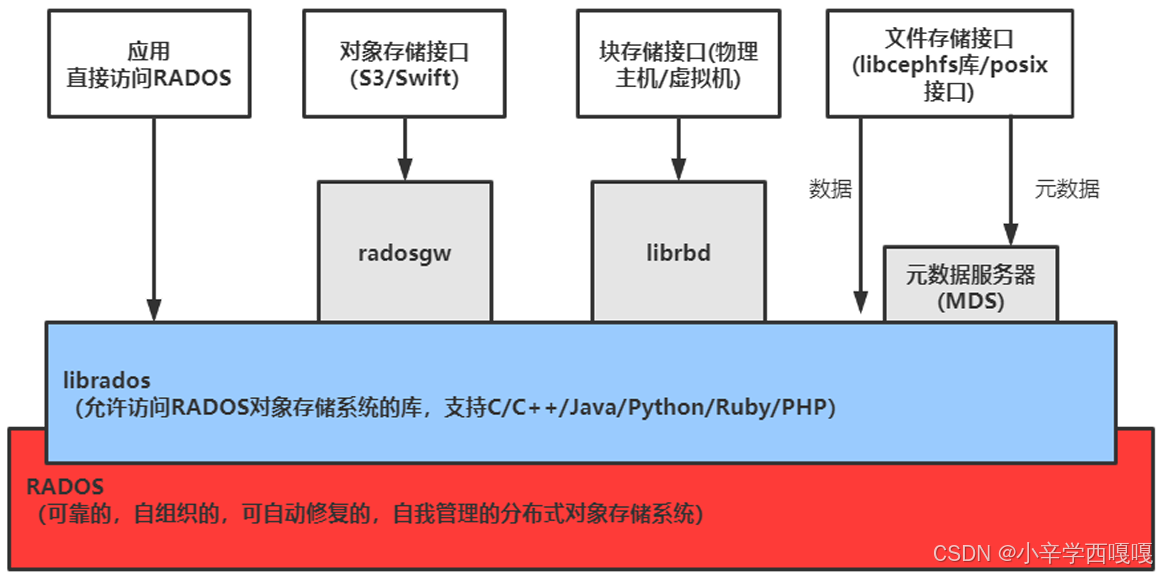
由上图所示,自下往上,逻辑上可以分为以下层次:
基础存储系统RADOS(Reliable Autonomic Object Store,可靠、自动、分布式对象存储)
基础库LIBRADOS
上层接口RADOSGW、RBD和CEPHFS
1:基础存储系统RADOS
基础存储系统RADOS(Reliable Autonomic Object Store,可靠、自动、分布式对象存储) RADOS是ceph存储集群的基础,这一层本身就是一个完整的对象存储系统。Ceph的高 可靠、高可扩展、高性能、高自动化等等特性本质上也都是由这一层所提供的,在 ceph中,所有数据都以对象的形式存储,并且无论什么数据类型, RADOS对象存储都将负责保存这些对象,确保了数据一致性和可靠性。RADOS系统主要由两部分组成,分别是OSD(对象存储设备)和Monitor(监控OSD)。 Osd集群依赖Monitor。
2:基础库LIBRADOS
LIBRADOS基于RADOS之上,它允许应用程序通过访问该库来与RADOS系统进行交 互,支持多种编程语言,比如C、C++、Python等。
3:三个上层接口
基于LIBRADOS层开发的三个接口,其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。
◼ RADOS GW(简称RGW)提供对象存储服务,是一套基于RESTFUL协议的网关,支持对象存储,兼容S3和Swift
◼ RBD提供分布式的块存储设备接口,主要面向虚拟机提供虚拟磁盘,可以被映射、格 式化,像磁盘一样挂载到服务器使用。
◼ CephFS是一个POSIX兼容的分布式文件系统,依赖MDS来跟踪文件层次结构,基于 librados封装原生接口,它跟传统的文件系统如Ext4 是一个类型的,但区别在于分布 式存储提供了并行化的能力,像NFS等也是属于文件系统存储。
4:核心组件
Monitor(ceph-mon)高可用三个起 维护集群Cluster Map的状态,维护集群的Cluster MAP二进制表,保证集群数据的一 致性。Cluster MAP描述了对象块存储的物理位置,以及一个将设备聚合到物理位置 的桶列表,map中包含monitor组件信息,manger 组件信息,osd组件信息,mds组 件信息,crush 算法信息。还负责ceph集群的身份验证功能,client 在连接ceph集群 时通过此组件进行验证。
OSD(ceph-osd) OSD全称Object Storage Device,用于集群中所有数据与对象的存储。ceph管理物理 硬盘时,引入了OSD概念,每一块盘都会针对的运行一个OSD进程。换句话说,ceph 集群通过管理OSD 来管理物理硬盘。负责处理集群数据的复制、恢复、回填、再均 衡,并向其他osd守护进程发送心跳,然后向Mon提供一些监控信息。当Ceph存储集 群设定数据有两个副本时(一共存两份),则至少需要三个OSD守护进程即三个OSD 节点,集群才能达到active+clean状态,实现冗余和高可用。
Manager(ceph-mgr):用于收集ceph集群状态、运行指标,比如存储利用率、 当前性能指标和系统负载。对外提供cephdashboard(ceph ui,网页访问ceph集 群)和resetful api。Manager组件开启高可用时,至少2个实现高可用性。
MDS(ceph-mds):Metadata server,元数据服务。为ceph 文件系统提供元数 据计算、缓存与同步服务(ceph对象存储和块存储不需要MDS)。同样,元数据 也是存储在osd节点中的,mds类似于元数据的代理缓存服务器,为posix文件 系统用户提供性能良好的基础命令(ls,find等)不过只是在需要使用CEPHFS时, 才需要配置MDS节点。
Object:Ceph最底层的存储单元是Object对象,每个Object包含元数据和原始数据
PG:PG全称Placement Grouops,是一个逻辑的概念,一个PG包含多个OSD。引 入PG这一层其实是为了更好的分配数据和定位数据。
Libradio驱动库:Librados是Rados提供库,因为RADOS是协议很难直接访问,因 此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、 Java、Python、C和C++支持。
CRUSH:CRUSH是Ceph使用的数据分布算法,类似一致性哈希,让数据分配到预 期的地方。
RBD:RBD全称RADOSblock device,是Ceph对外提供的块设备服务。
CephFS:CephFS全称Ceph File System,是Ceph对外提供的文件系统服务。
六: ceph的底层存储过程
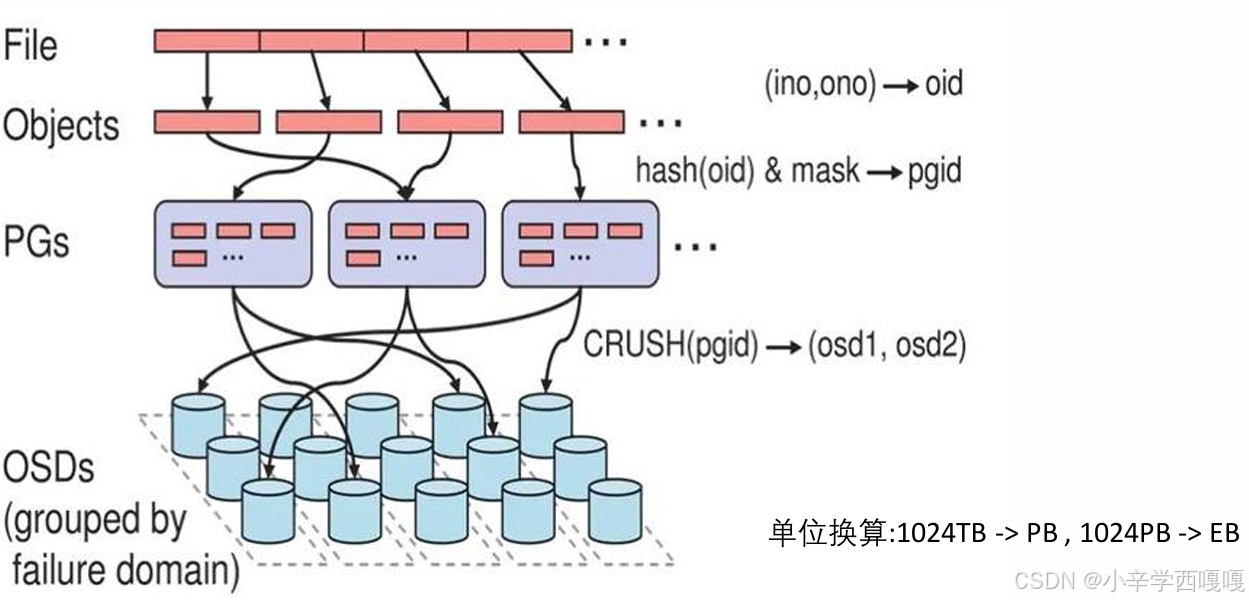
无论使用哪种存储方式(对象,块,文件),存储的数据当底层保存时,都会被切分成一 个个大小固定的对象(Objects),对象大小可以由管理员自定义调整,RADOS中基本的存储 单位就是Objects,一般为2MB或4MB(最后一个对象大小有可能不同)(比如文件9M, 4M 4M1M)。
如上图,一个个文件(File)被切割成大小固定的Objects后,将这些对象分配到一 个PG(Placement Group)中,然后PG会通过多副本的方式复制几份,随机分派给 不同的存储节点(也可指定)。 当新的存储节点(OSD)被加入集群后,会在已有数据中随机抽取一部分数据迁移 到新节点,这种概率平衡的分布方式可以保证设备在潜在的高负载下正常工作,更 重要的事,数据的分布过程仅需要做几次随机映射,不需要大型的集中式分配表, 方便且快速,不会对集群产生大的影响。
用户通过客户端存储一个文件时,在RAODS中,该File(文件)会被分割为多个 2MB/4MB大小的Objects(对象)。而每个文件都会有一个文件ID,例如A,那么这 些对象的ID就是A0,A1,A2等等。然而在分布式存储系统中,有成千上万个对象,只 是遍历就要花很久时间,所以对象会先通过hash-取模运算,存放到一个PG中。
PG相当于数据库的索引(PG的数量是固定的,不会随着OSD的增加或者删除而改 变),这样只需要首先定位到PG位置,然后在PG中查询对象即可。之后PG中的对象 又会根据设置的副本数量进行复制,并根据CRUSH算法存储到OSD节点上。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)