
并行计算 用MPI进行分布式内存编程(三)I/O处理
下面给出的并行梯形积分法程序中有个严重的不足:只能用于1024个梯形计算[0, 3]区间内的积分。与简单地输入三个新值相比,编译和重新编辑代码这种方法的工作量是相当大的、因此我们要解决用户输入的问题。顺带把用户输出的问题也一并解决。输出大部分的MPI实现都允许所有进程执行printf和fprintf,但是MPI的实现并不提供对这些I/O设备访问的自动调度。也就是说,如果多个进程试图写标准输出std
下面给出的并行梯形积分法程序中有个严重的不足:只能用于1024个梯形计算[0, 3]区间内的积分。与简单地输入三个新值相比,编译和重新编辑代码这种方法的工作量是相当大的、因此我们要解决用户输入的问题。顺带把用户输出的问题也一并解决。
输出
大部分的MPI实现都允许所有进程执行printf和fprintf,但是MPI的实现并不提供对这些I/O设备访问的自动调度。也就是说,如果多个进程试图写标准输出stdout,那么这些进程的输出顺序是无法预测的,甚至会发生一个进程的输出被另一个进程打断的情况。
梯形积分法MPI程序的第一个版本
test2.c
#include <stdio.h>
#include <string.h>
#include <mpi.h>
#include "test02.h"
int main(void){
int my_rank, comm_sz, n = 1024, local_n;
double a = 0.0, b = 3.0, h, local_a, local_b;
double local_int, total_int;
int source;
MPI_Init(NULL,NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
h = (b-a)/n;
local_n = n/comm_sz;
local_a = a + my_rank*local_n*h;
local_b = local_a + local_n*h;
local_int = Trap(local_a, local_b, local_n, h);
if(my_rank != 0){
MPI_Send(&local_int, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
} else {
total_int = local_int;
for(source=1; source<comm_sz; source++){
MPI_Recv(&local_int, 1, MPI_DOUBLE, source, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
total_int += local_int;
}
}
if(my_rank == 0){
printf("With n = %d trapezoids, our estimate\n", n);
printf("of the integral from %f to %f = %.15e\n", a, b, total_int);
}
MPI_Finalize();
return 0;
}
test2.h(为了便于验证,设置函数 “ f(x) = x ” )
//
// Created by root123 on 10/14/21.
//
#ifndef FIRST_TEST02_H
#define FIRST_TEST02_H
double f(double x){
double temp = x;
return temp;
}
double Trap(double left_endpt, double right_endpt, int trap_count, double base_len){
double estimate, x;
int i;
estimate = (f(left_endpt) + f(right_endpt))/2;
for(i=1; i<=trap_count-1; i++){
x = left_endpt + i*base_len;
estimate += f(x);
}
estimate = estimate*base_len;
return estimate;
}
#endif //FIRST_TEST02_H
运行结果

f(x) = x在区间[0, 3]之间的面积为4.5,与程序运行结果是一致的。
竞争输出
运行下面的MPI程序,每个进程只是简单的打印一条消息。
//
// Created by root123 on 10/14/21.
//
#include <stdio.h>
#include <mpi.h>
int main(void){
int my_rank, comm_sz;
MPI_Init(NULL,NULL);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
printf("Proc %d of %d > Does anyone have a toothpick?\n", my_rank, comm_sz);
MPI_Finalize();
return 0;
}当有6个进程运行程序时,输出行的顺序就不可预测了:
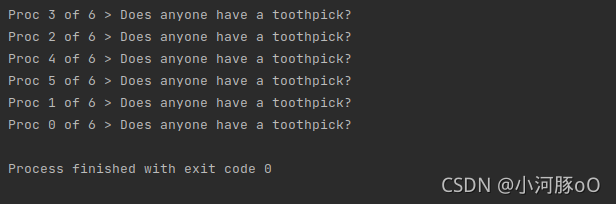
或者:
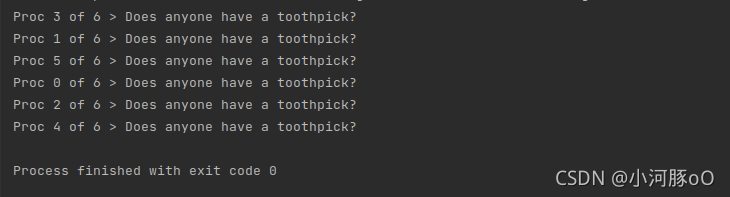 这一现象产生的原因是MPI进程都在互相“竞争”,以取得对共享输出设备、标准输出stdout的访问。我们不可能预测进程的输出是以怎样的顺序排列。这种竞争会导致不正确性,即每次运行的实际输出可能会变化。
这一现象产生的原因是MPI进程都在互相“竞争”,以取得对共享输出设备、标准输出stdout的访问。我们不可能预测进程的输出是以怎样的顺序排列。这种竞争会导致不正确性,即每次运行的实际输出可能会变化。
如果不希望进程的输出以随机顺序出现,那么我们就应该按自己的想法去修改代码。例如,让除了0号进程之外的其他进程向0号进程发送它的输出,然后让0号进程根据进程号的顺序打印输出结果。
输入
与输出不同,大部分的MPI实现只允许MPI_ COMM_ WORLD 中的0号进程访问标准输人stdin。这是有道理的:如果多个进程都能访问标准输人stdin,那么哪个进程应该得到输人数据的哪个部分呢? 0号进程应该得到第一个字符吗?
为了编写能够使用 scanf 的MPI程序,我们根据进程号来选取转移分支。0号进程负责读取数据,并将数据发送给其他进程。例如,在梯形积分法的并行程序中的Get_ input函数,0号进程只是简单地读取a、b和 n的值,并将这三个值发送给其他每个进程。
为了使用该函数,我们可以在主程序中简单地插入对该函数的调用。要注意的是,我们必须在初始化my_rank和comm_sz后,才能调用该函数:
. . .
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
Get_data(my_rank, comm_sz, &a, &b, &n);
h = (b-a)/n;
. . .
一个用于读取用户输入的函数
#include <stdio.h>
#include <mpi.h>
void Get_input(int my_rank, int comm_sz, double* a_p, double* b_p, int* n_p){
int dest;
if(my_rank == 0){
printf("Enter a, b and n\n");
scanf("%f %f %d", a_p, b_p, n_p);
for(dest=1; dest<comm_sz; dest++){
MPI_Send(a_p, 1, MPI_DOUBLE, dest, 0, MPI_COMM_WORLD);
MPI_Send(b_p, 1, MPI_DOUBLE, dest, 0, MPI_COMM_WORLD);
MPI_Send(n_p, 1, MPI_INT, dest, 0, MPI_COMM_WORLD);
}
} else {
MPI_Recv(a_p, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Recv(b_p, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Recv(n_p, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
}
}更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)