
【KWDB 创作者计划】产品解读 - KWDB分布式多模数据库架构深度剖析:打通数据管理的“任督二脉”,掌握数据管理的“武林秘籍”
随着物联网(IoT)和人工智能(AI)技术的快速发展,AIoT(人工智能物联网)在各行业的应用日益广泛,尤其在智能家居、智慧城市和工业4.0等领域。时序数据库在处理大规模时间序列数据中的重要性不断凸显,尤其是在IoT场景下,数据量庞大且复杂。传统数据库在处理海量数据时逐渐显现瓶颈,而时序数据库因其高压缩率、高读写速度和高可视化分析能力,成为企业实现智能化转型的关键路径。 KWDB作为一款国产分布式
【KWDB 创作者计划】实操体验 - KWDB分布式多模数据库深度探索:高效部署安装指南与TSBS性能压测技巧全攻略
【KWDB 创作者计划】场景案例 - KWDB分布式多模数据库在净水机物联网IoT方案落地最佳实践:GoLang时序IoT数据 + 香橙派Orange Pi AI Pro 开发板场景案例测试
【KWDB 创作者计划】产品解读 - KWDB分布式多模数据库架构深度剖析:打通数据管理的“任督二脉”,掌握数据管理的“武林秘籍”
一、序列概括:
随着物联网技术在各行业的使用将越来越广,物联网与人工智能的深度结合,特别是在智能家居、智慧城市、工业4.0等领域有着广泛的应用,AIoT(Artificial Intelligence of Things)正成为企业实现智能化转型的关键路径。
上面二篇长文已经介绍了KWDB的安装以及踩过的坑,而且也对TSBS专门针对时间序列场景做了压力测试,同时,也使用了GoLang时序IoT数据 + 香橙派Orange Pi AI Pro 开发板场景案例测试的最佳实践。
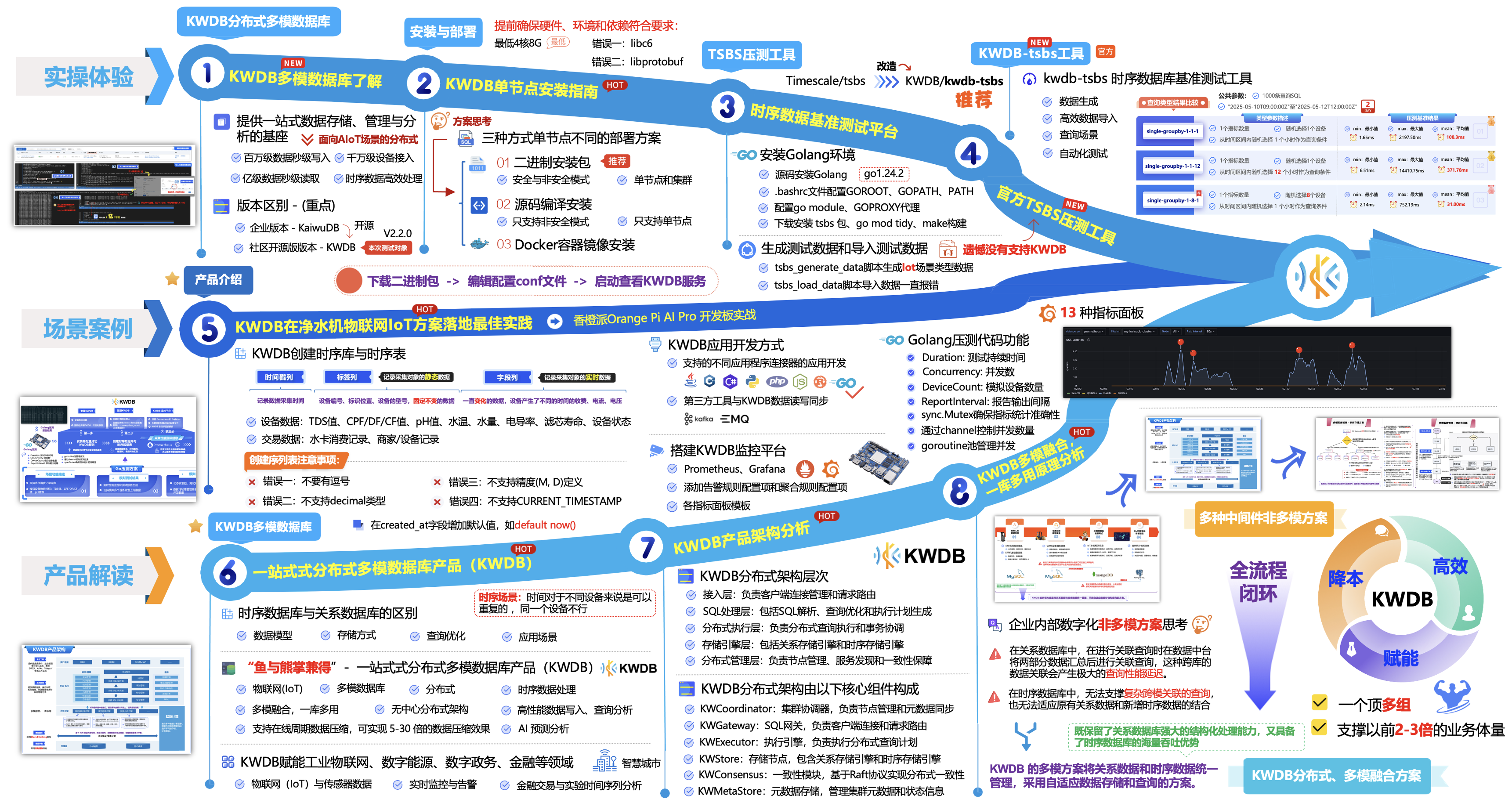
接下来,将从第3个方向“产品解读”一起来探索KWDB产品架构与原理上带着大家一起来解锁数据管理新境界。
一、正文前言:
近年来,随着物联网、人工智能和设备的普及,以及物联网(IoT)规模持续不断的增长,IoT 领域的数据管理需求变得越来越复杂,时间序列数据在各个领域的应用越来越广泛,时序数据库的重要性也日益凸显。迫切的需要一款高性能、可扩展、强安全、低成本的数据管理系统为底座,向上承托大数据分析、数据资产化、资产服务化等增值应用,以数据驱动生产管理效率提升,赋能行业数智化发展。

传统数据库在面对海量数据处理时逐渐显现瓶,伴随着时序数据库的用例不断增加,已成为企业中增长最快的数据库类型之一。那么,怎么样拥有一款时序数据库,可以为更多领域提供更高效、更可靠的数据处理和分析能力呢?
今天给大家推荐一款作为国产数据库的新锐代表,KWDB是一款分布式、多模、支持云边端协同的数据库产品,以 AIoT 为一大核心场景,提供高性能、高可用、高兼容、高扩展的数据管理服务及能力,旨在以现代数据库架构,与前沿智能化技术的融合创新赋能工业物联网、数字能源、车联网、智慧产业等新兴数字领域,助力传统产业从容步入 IoT 时代。
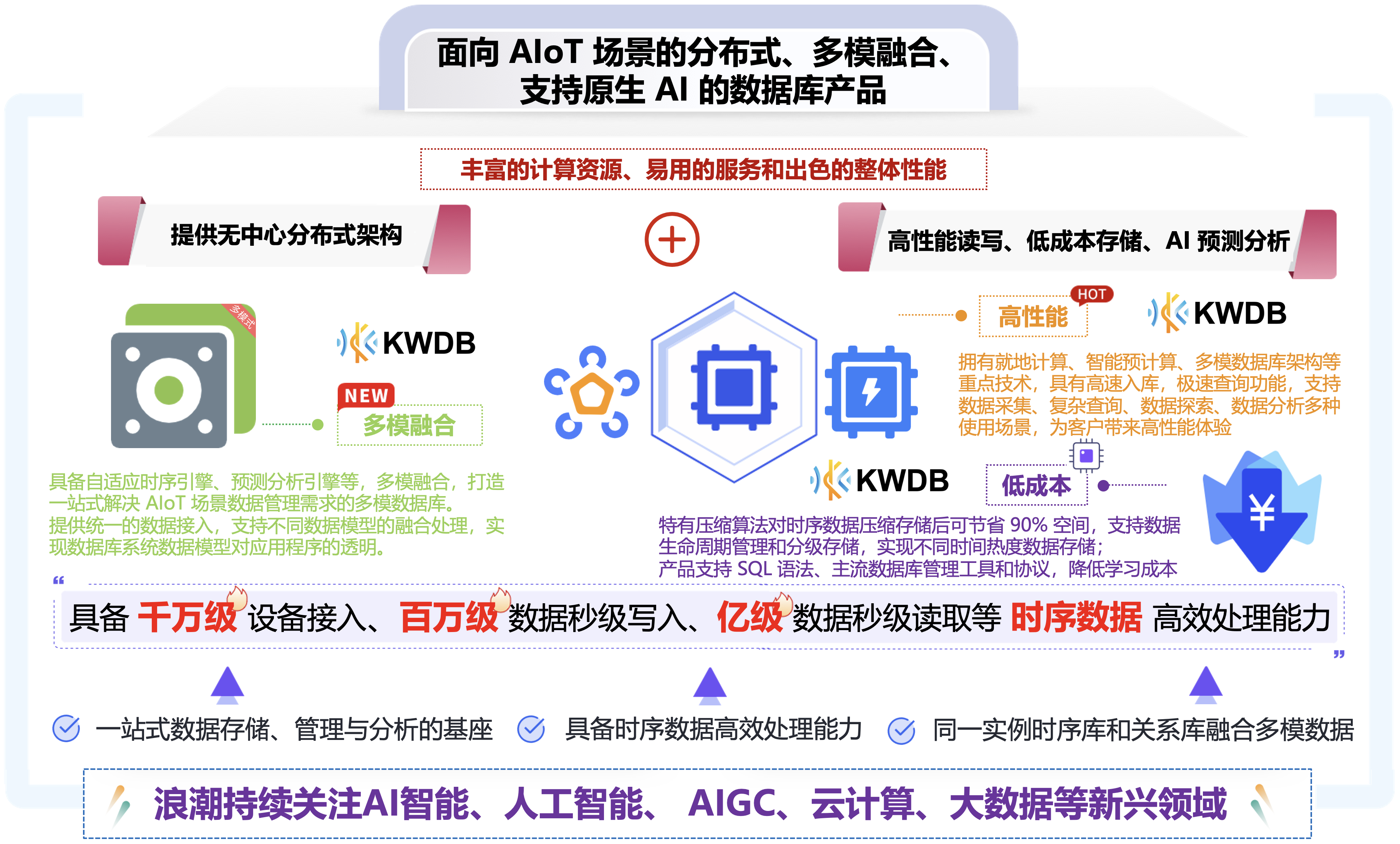
-
①. “就地计算”技术赋能时序数据处理性能大幅提升,轻松应对 PB 级、甚至 ZB 级时序数据高速写入、复杂查询。
-
②. 主打“面向行业的多模”,将多个不同类型数据库的功能充分融合,实现“一库多用”,大幅简化传统复杂化的运维管理流程。
二、时序数据库是什么?
时序数据库是用于处理带有时间戳数据的数据库。与其他数据库相比,时序数据库在处理大规模时间序列数据时有支持高压缩率、高读写速度、高可视化分析能力等优势,是近年来发展最快的数据库产品之一。
为什么会衍生时序数据库这一种新趋势呢?一般常规项目使用的是PostgreSQL或MySQL这种关系型数据库对于短期需求不大的情况下下还是可以满足的,但是一旦数据量增长,其性能不足以支持频繁的添加和读取需求。运用时间模型来构造的应用非常需要时序数据库的加持,包括未来大数据的趋势,时序数据库必然会成为一个新潮流。
时序数据库(Time Series Database, TSDB)和关系数据库(Relational Database, RDBMS)是两种针对不同数据需求设计的数据库类型,它们在数据模型、存储方式、查询优化和应用场景等方面有显著区别。
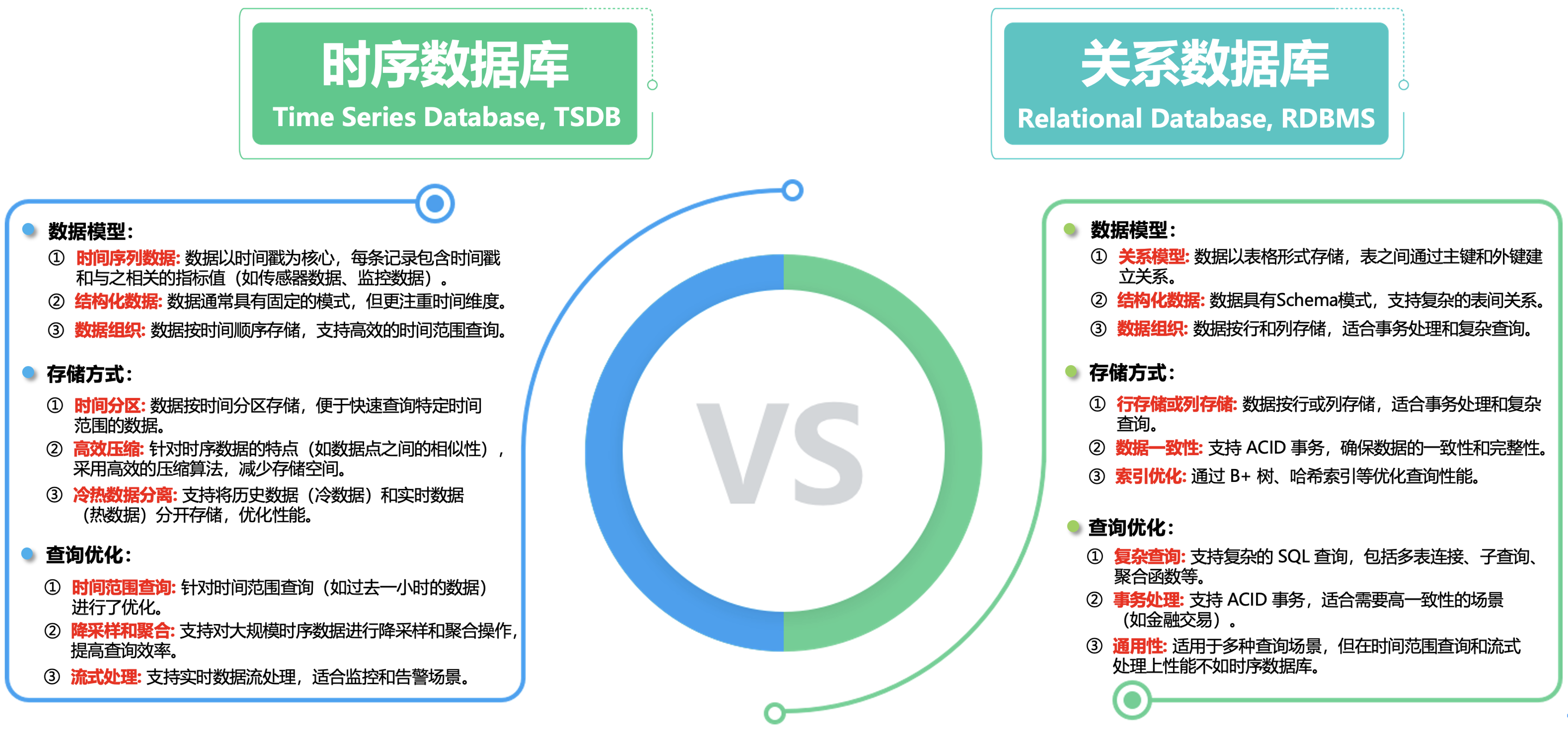
-
①. 时序数据库:专门存储带时间戳的序列化数据,要求表结构包含主时间戳字段和标签字段,更适合处理时间序列数据,具有高写入吞吐量、高效的时间范围查询和低存储成本的特点。
-
②. 关系型数据库:支持传统关系模型,可定义主键、外键、索引等约束,适用于非时间序列数据,更适合处理复杂的事务和查询,支持强一致性和复杂的数据关系。

时序数据库则面向工业物联网场景,数据由传感器设备产生,其接入终端规模可能达到数万至百万量级,数据采集频率可达秒级、毫秒级。因此,时序数据库需稳定维持每秒数十万至千万级的数据写入吞吐,针对高通量、高并发的写入需求进行性能优化。
三、“鱼与熊掌兼得” - 一站式式分布式多模数据库产品(KWDB):
上面我们了解了KWDB不仅仅是“时序数据库”, KWDB 透过内核内置一套通用的数据模型,将时序与关系数据模型融于一体。KWDB提供统一的数据接入,支持不同数据模型的融合处理,实现数据库系统数据模型对应用程序的透明。这既可以满足各种场景下用户对单一数据模型的管理需求,也能够满足用户大型复杂系统对多模数据的管理需求。
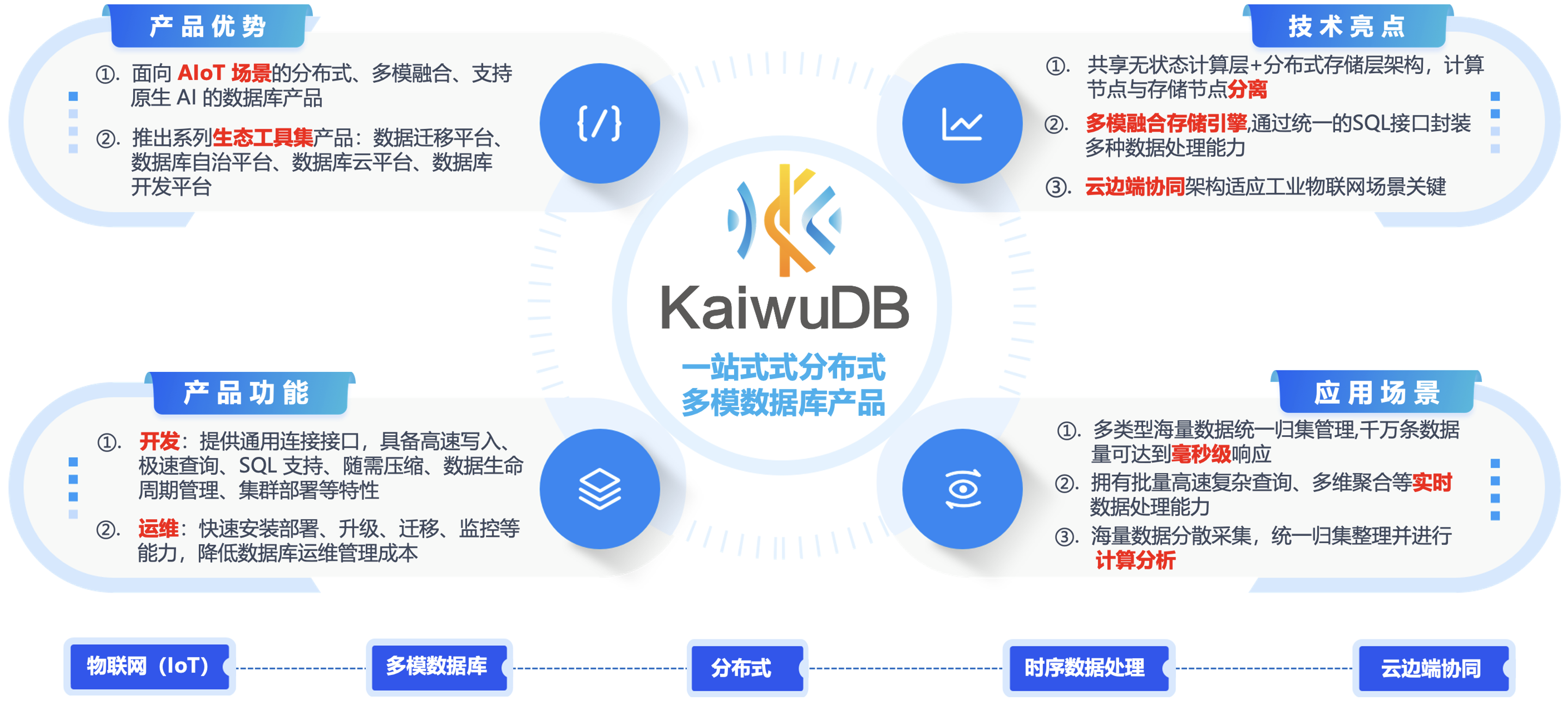
3.1 KWDB产品优势:
KWDB具备完善的功能和优异的性能,充分满足不同的应用场景需求,赋能行业企业的数字化建设和转型。
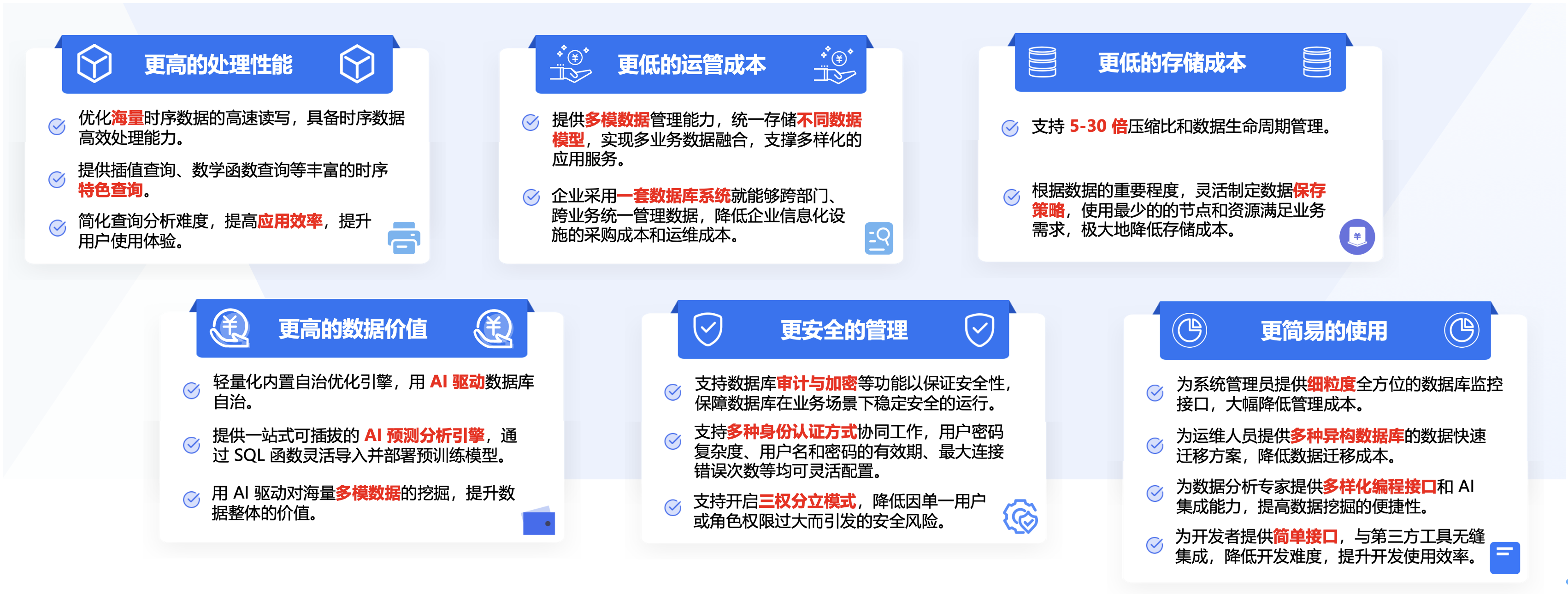
相比传统的数据库,KWDB 提供多模数据管理能力,支持不同数据模型的统一存储,助力企业跨部门、跨业务统一管理数据,实现多业务数据融合,支撑多样化的应用服务,KWDB 的产品架构如下图所示:
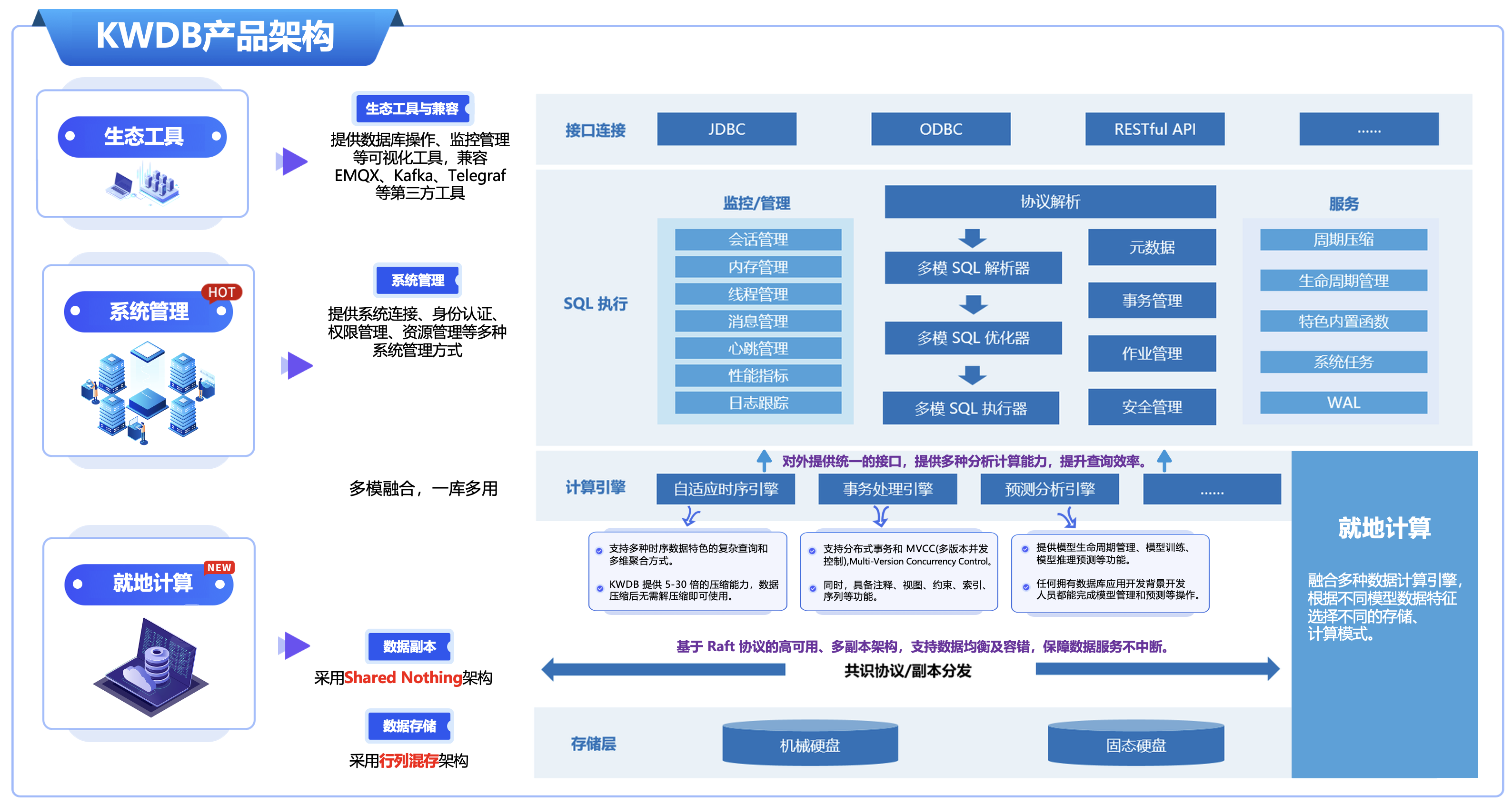
- ①. 数据存储:采用行列混存架构,支持固态硬盘、机械硬盘等各类存储设备。
- ②. 数据副本:采用 Shared Nothing 架构,基于 Raft 协议的高可用、多副本架构,支持数据均衡及容错,保障数据服务不中断。
- ③. 执行计算:融合多种数据计算引擎,根据不同模型数据特征选择不同的存储、计算模式,对外提供统一的接口,提供多种分析计算能力,提升查询效率。
- ④. 系统管理:提供系统连接、身份认证、权限管理、资源管理等多种系统管理方式。
- ⑤. 生态工具与兼容:提供数据库操作、监控管理等可视化工具,兼容 EMQX、Kafka、Telegraf 等第三方工具。
3.2 KWDB应用场景:
工业物联网IoT场景下,数据是最重要的资源之一,企业需要对各种机器、设备和传感器产生的时序数据进行采集、存储与分析。上述场景对数据库提出包括高可靠性、实时性、大规模、高并发、高精度、易扩展等在内的各种要求。同时,这些数据也带来了新的挑战,如数据安全、数据质量、数据管理等,KWDB可以覆盖众多行业应用场景,助力用户从数据中挖掘更大的商业价值。
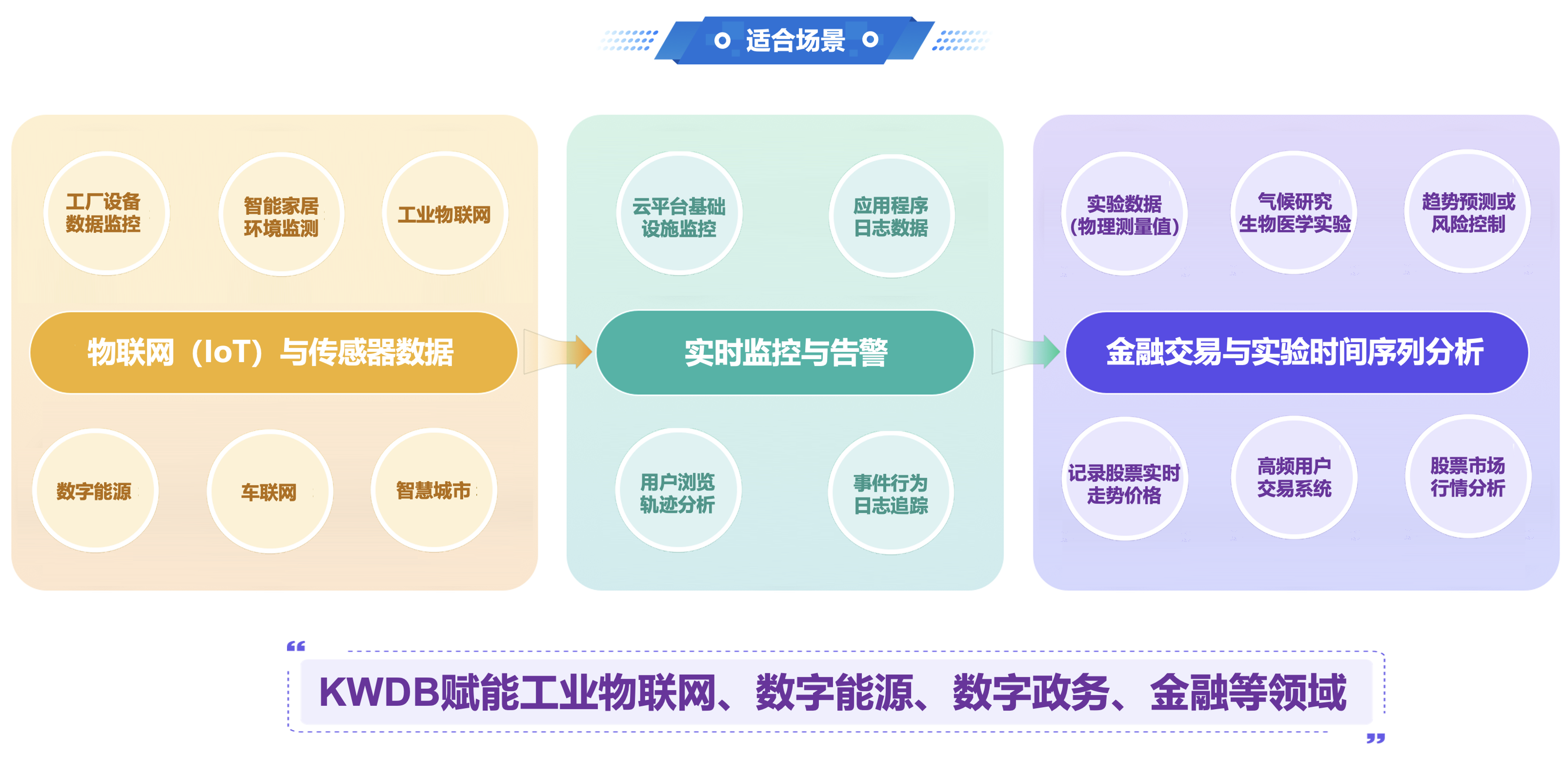
四、KWDB多模融合,一库多用原理分析:
KWDB 透过内核内置一套通用的数据模型,将时序与关系数据模型融于一体。KWDB 提供统一的数据接入,支持不同数据模型的融合处理,实现数据库系统数据模型对应用程序的透明。这既可以满足各种场景下用户对单一数据模型的管理需求,也能够满足用户大型复杂系统对多模数据的管理需求。
企业内部净水机数字化体系建设思考:
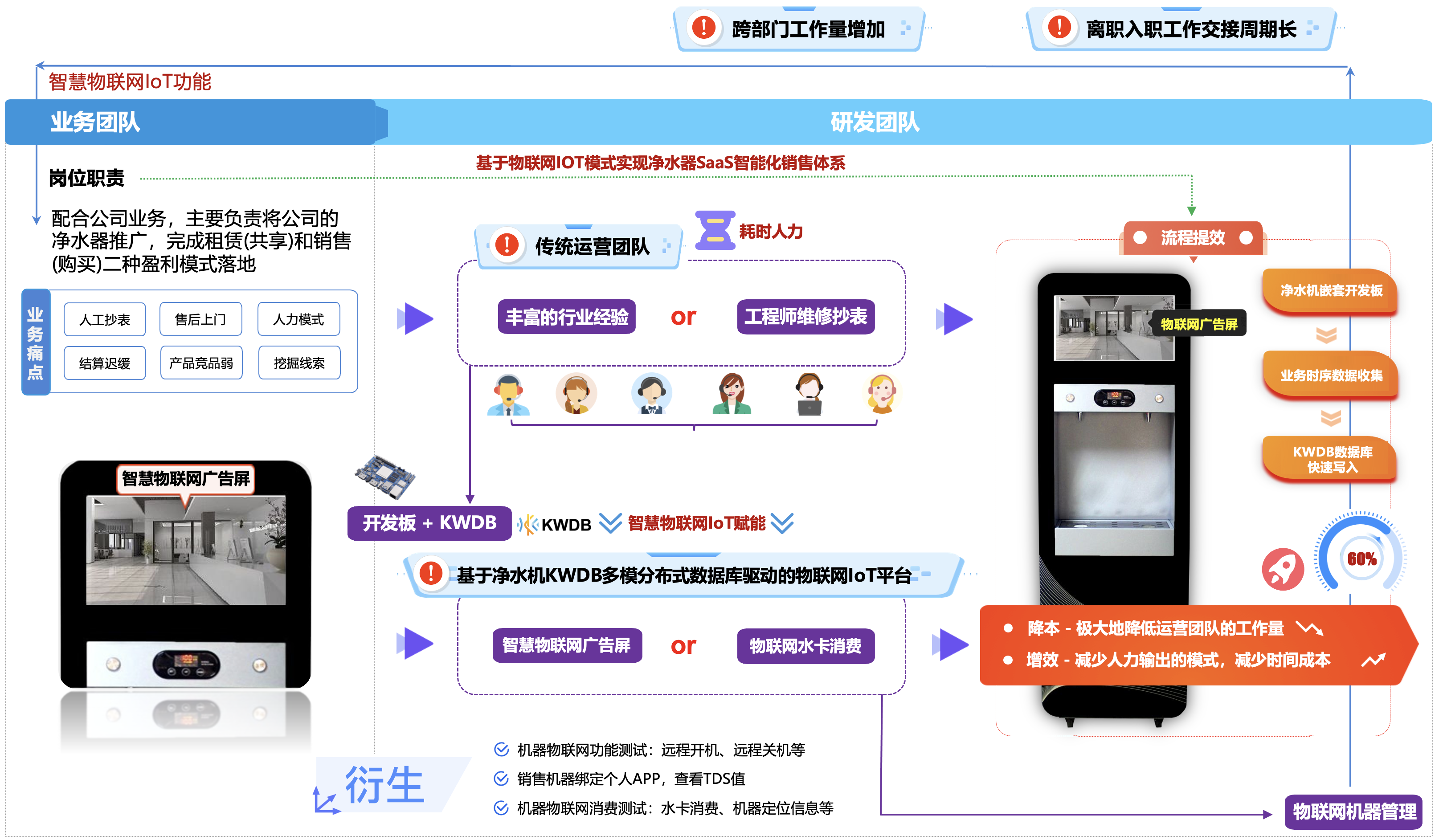
以净水机物联网IoT场景为例,因为设备产生的数据通常都会带有时间戳,如净水器的编号、设备状态、TDS值、设备交易数据等,数据管理通常以时序数据为核心。但是,物联网系统不仅限于时序数据,还包括净水机的类型、销售渠道归属、用户信息、日志记录等非时序数据。因此,在企业内部物联网业务场景下,存在着非多模方案。
以下为企业内部数字化体系建设的数据流向,用于从不同的数据源中提取数据,对其进行清洗和转换,最后加载到目标数据库或数据仓库中。应用于数据仓库、数据湖、数据分析等领域,为分析、报表、机器学习等应用提供一致、清洗后的数据。
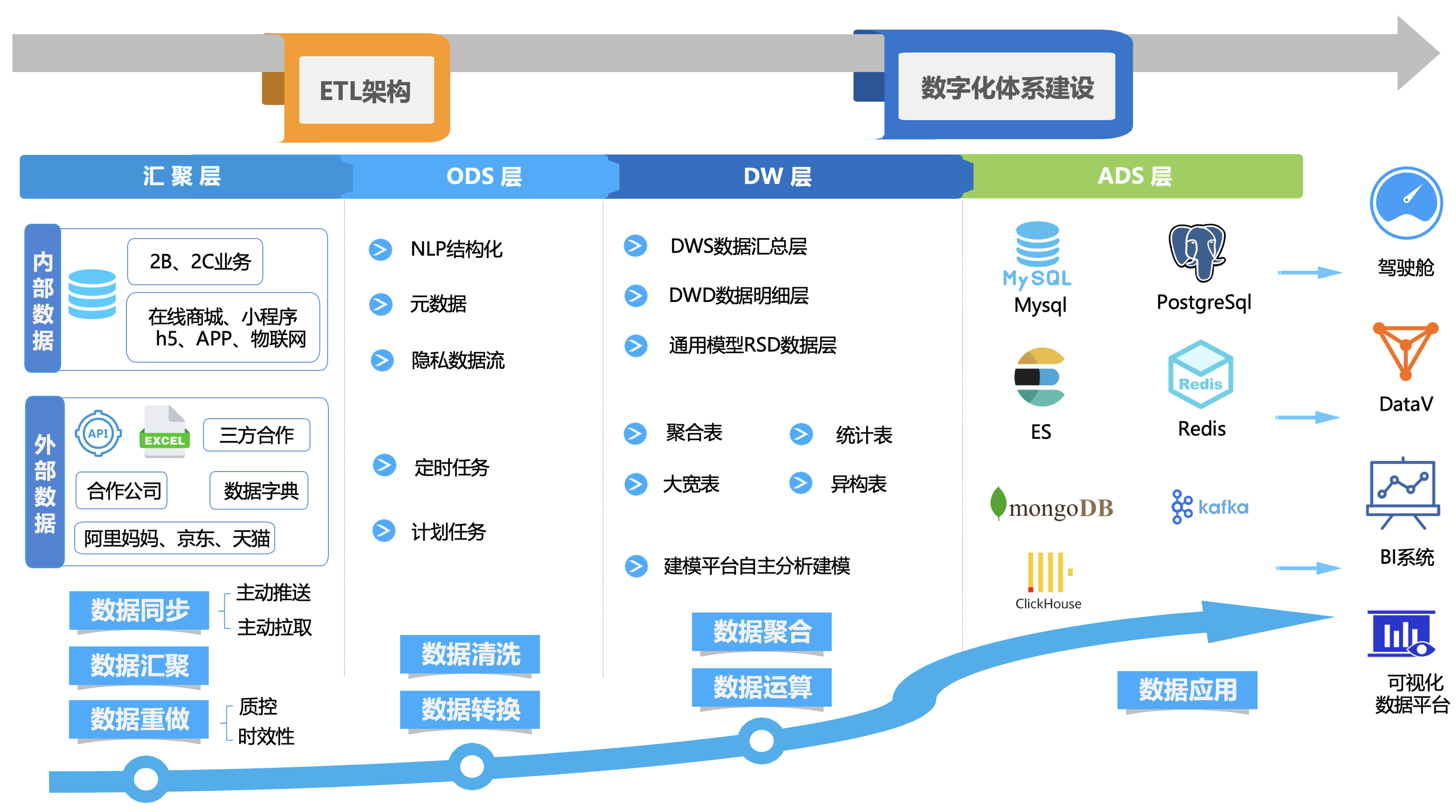
-
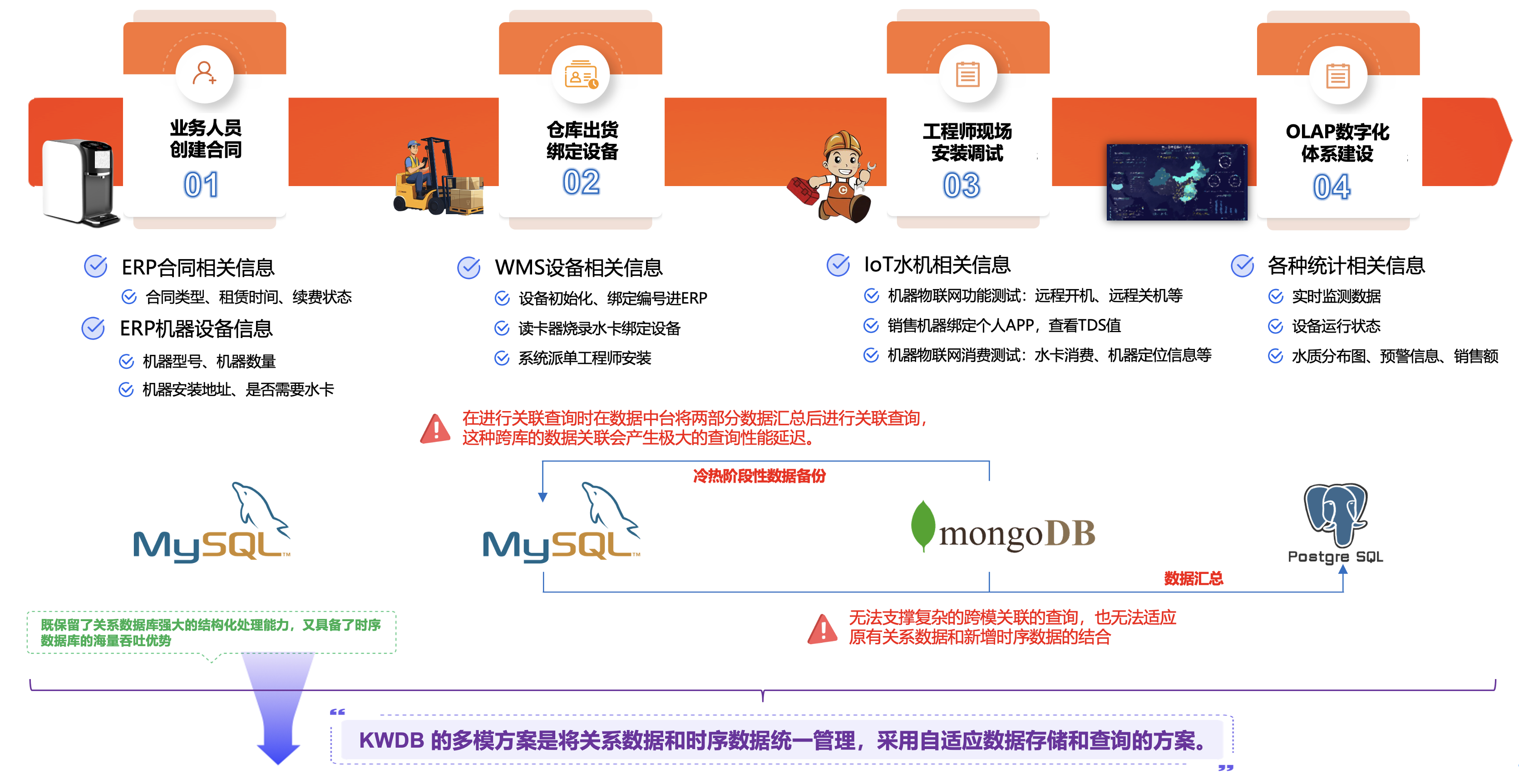
①. 在机器出厂工程师在用户现场安装前,会对机器进行一些出厂的初始化设置,比如:由销售人员在ERP系统建立机器合同(租赁或销售),合同包含合同的租赁期限、续费状态、机器的类型、数量,再由仓库人员录入机器编码绑定设备到ERP系统内,如果是租赁设备还需要专门进行净水机读卡、充值、绑定等操作。这些信息是存储在关系型数据库MySQL中。
-
②. 净水机在使用过程中,产生的时序数据会通过自带的开发板,将数据收集并且发送到MongoDB文档数据库上,在一定的期限范围内,会进行冷热数据备份,将一部分旧的数据同步保存到MySQL服务器上。
-
③. 针对于数据报表系统,则会将数据统一清洗到PostgreSQL数据中,为了应付查询速度与效率,可能会额外增加其它的中间件,比如:Elasticsearch、ClickHouse、Redis等技术手段。
-
①. 我们可以看到在MySQL 等的关系数据库中,时序数据存储在 MongoDB等时序数据库中,在进行关联查询时在数据中台将两部分数据汇总后进行关联查询,这种跨库的数据关联会产生极大的查询性能延迟。
-
②. 而在时序数据库保存部分关系数据,使得关系数据和时序数据保存在一起,再采用优化手段,降低关系数据带来的冗余存储,这样虽然能提高部分关联查询的速度,但是由于关系数据和时序数据存储的特性,其无法支撑复杂的跨模关联的查询,也无法适应原有关系数据和新增时序数据的结合。
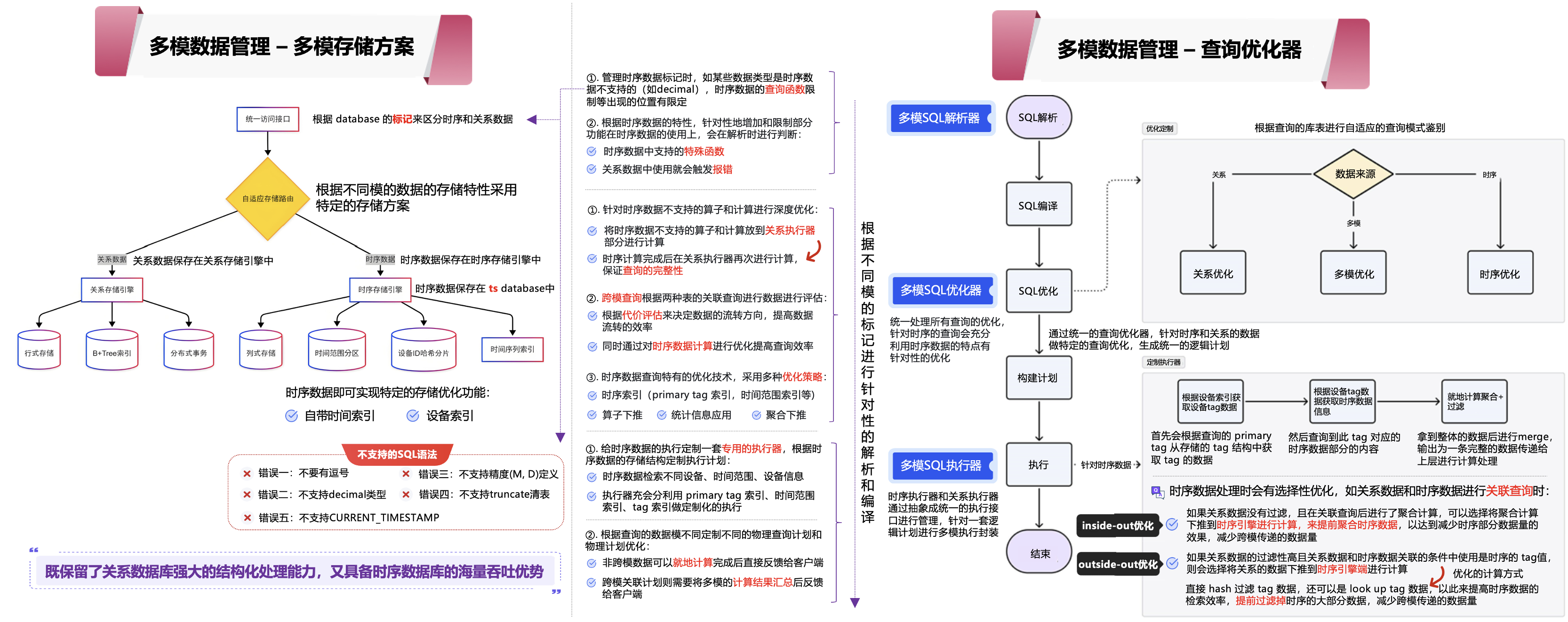
此时,KWDB 的多模方案是将关系数据和时序数据统一管理,采用自适应数据存储和查询的方案,这样既保留了关系数据库强大的结构化处理能力,又具备了时序数据库的海量吞吐优势。
五、KWDB源码分析:
在官网下载KWDB源码,项目围绕数据库系统展开,涵盖构建、部署、测试、监控等多个方面,具备一定的企业级应用特性。
5.1 核心组件与模块:
- ①. kwbase:包含项目关系型数据库的一些配置文件、构建脚本(如 builder.sh)、依赖管理(c-deps)等内容,还包含一些通用工具脚本和样本文件。
- ②. kwdbts2:包含时序数据库引擎、执行等核心代码逻辑。如 engine 目录下的 db.cpp、engine.cpp 等文件,负责数据库的核心功能实现;exec 目录处理执行相关的逻辑。
- ③. common:提供通用功能,包含日志(log)、线程(thread)、内存管理(mem)等模块,为整个项目提供基础支持。
- ④. cluster_start/utils.sh:集群启动过程中的实用脚本,用于完成一些初始化或辅助操作。
5.2 构建与部署:
- ①. CMakeLists.txt 和 Makefile:分别用于项目的构建配置,可能分别适用于不同的构建环境或工具链。
- ②. kaiwudb_install:包含部署相关的脚本,如 deploy.sh、add_user.sh 等,以及一些实用工具脚本,用于安装、升级、卸载数据库集群等操作。
5.3 测试相关:
- ①. qa:包含集成测试、性能测试、压力测试等脚本和配置文件。如 Integration 目录下的集成测试脚本,stress_tests 目录下的压力测试配置和测试代码。
- ②. kwdbts2/test:在核心代码的 kwdbts2 模块中也有测试相关目录,对引擎、执行等模块进行单元测试。
5.4 监控相关:
- ①. monitoring:包含 Grafana 仪表盘配置文件(grafana-dashboards)、Prometheus 配置文件(prometheus.yml)以及相关的监控规则(rules),用于对数据库系统进行监控。
5.5 包管理:
- ①. packages:包含生成不同格式软件包的配置文件,如 debpackage 用于生成 Debian 包,rpmpackage 用于生成 RPM 包。
应用层
│
├─ 关系型接口(kwbase)
│
└─ 时序接口(kwdbts2)
│
├─ 执行引擎(exec)
├─ 存储引擎(storage)
├─ 内存管理(mmap)
└─ 统计模块(statistic)
│
└─ 基础服务(common)
├─ 日志系统(log)
├─ 线程管理(thread)
├─ 错误处理(error)
└─ 跟踪系统(trace)
相关关键代码解释:
// TestConcurrentRaftSnapshots tests that snapshots still work correctly when
// Raft requests multiple non-preemptive snapshots at the same time. This
// situation occurs when two replicas need snapshots at the same time.
func TestConcurrentRaftSnapshots(t *testing.T) {
defer leaktest.AfterTest(t)()
// This test relies on concurrently waiting for a value to change in the
// underlying engine(s). Since the teeing engine does not respond well to
// value mismatches, whether transient or permanent, skip this test if the
// teeing engine is being used. See
// https://gitee.com/kwbasedb/kwbase/issues/42656 for more context.
if storage.DefaultStorageEngine == enginepb.EngineTypeTeePebbleRocksDB {
t.Skip("disabled on teeing engine")
}
mtc := &multiTestContext{
// This test was written before the multiTestContext started creating many
// system ranges at startup, and hasn't been update to take that into
// account.
startWithSingleRange: true,
}
defer mtc.Stop()
mtc.Start(t, 5)
repl, err := mtc.stores[0].GetReplica(1)
if err != nil {
t.Fatal(err)
}
key := roachpb.Key("a")
incA := int64(5)
incB := int64(7)
incAB := incA + incB
// Set up a key to replicate across the cluster. We're going to modify this
// key and truncate the raft logs from that command after killing one of the
// nodes to check that it gets the new value after it comes up.
incArgs := incrementArgs(key, incA)
if _, err := kv.SendWrapped(context.Background(), mtc.stores[0].TestSender(), incArgs); err != nil {
t.Fatal(err)
}
mtc.replicateRange(1, 1, 2, 3, 4)
mtc.waitForValues(key, []int64{incA, incA, incA, incA, incA})
// Now kill stores 1 + 2, increment the key on the other stores and
// truncate their logs to make sure that when store 1 + 2 comes back up
// they will require a non-preemptive snapshot from Raft.
mtc.stopStore(1)
mtc.stopStore(2)
incArgs = incrementArgs(key, incB)
if _, err := kv.SendWrapped(context.Background(), mtc.stores[0].TestSender(), incArgs); err != nil {
t.Fatal(err)
}
mtc.waitForValues(key, []int64{incAB, incA, incA, incAB, incAB})
index, err := repl.GetLastIndex()
if err != nil {
t.Fatal(err)
}
// Truncate the log at index+1 (log entries < N are removed, so this
// includes the increment).
truncArgs := truncateLogArgs(index+1, 1)
if _, err := kv.SendWrapped(context.Background(), mtc.stores[0].TestSender(), truncArgs); err != nil {
t.Fatal(err)
}
mtc.restartStore(1)
mtc.restartStore(2)
mtc.waitForValues(key, []int64{incAB, incAB, incAB, incAB, incAB})
}
验证在Raft集群中,当一个或多个节点故障后重启,它们能够通过快照或日志复制正确地同步数据。下面是对代码的详细解释:
-
测试准备和前置条件:
- ①. 使用defer leaktest.AfterTest(t)()来确保在测试结束后检查内存泄漏。
- ②. 检查当前使用的存储引擎是否为enginepb.EngineTypeTeePebbleRocksDB,如果是,则跳过测试。这是因为该测试依赖于值的变化,而TeePebbleRocksDB引擎在处理值不匹配时表现不佳。
-
初始化多测试上下文:
- ①. 创建一个multiTestContext实例,并设置startWithSingleRange为true,这意味着测试开始时只创建一个系统范围。
- ②. 使用defer mtc.Stop()确保在测试结束时停止所有节点。
- ③. 启动5个节点(mtc.Start(t, 5))。
-
获取副本和初始化键值:
- ①. 从第一个节点获取副本(repl)。
- ②. 定义一个键key和两个增量值incA和incB,以及它们的和incAB。
- ③. 使用incrementArgs函数构造增量操作的参数,并通过kv.SendWrapped发送给第一个节点,以增加键的值。
-
复制键值并验证:
- ①. 调用mtc.replicateRange方法,将键值复制到其他节点。
- ②. 使用mtc.waitForValues方法验证所有节点上的键值是否都更新为incA。
-
模拟节点故障并增量更新键值:
- ①. 停止第1和第2个节点(mtc.stopStore(1)和mtc.stopStore(2))。
- ②. 再次对键进行增量操作,这次增量值为incB,并发送到剩余节点。
- ③. 使用mtc.waitForValues验证剩余节点的键值是否更新为incAB,而停止的节点上的值仍然为incA。
-
截断日志并重启节点:
- ①. 获取副本的最后索引,并构造截断日志的参数,截断点设置为最后索引+1。
- ②. 发送截断日志的命令。
- ③. 重启之前停止的第1和第2个节点。
使用mtc.waitForValues再次验证所有节点上的键值是否都更新为incAB,确保重启的节点通过快照或日志复制正确地同步了数据。
总的来说,这个测试模拟了Raft集群中节点故障、数据更新、日志截断和节点重启的场景,验证了Raft快照机制在并发和故障恢复中的正确性。
// CreateEngines creates Engines based on the specs in cfg.Stores.
func (cfg *Config) CreateEngines(ctx context.Context) (Engines, error) {
engines := Engines(nil)
defer engines.Close()
if cfg.enginesCreated {
return Engines{}, errors.Errorf("engines already created")
}
if cfg.TsStores.Specs == nil {
cfg.TsStores = cfg.Stores
}
cfg.enginesCreated = true
var details []string
var cache storage.RocksDBCache
var pebbleCache *pebble.Cache
if cfg.StorageEngine == enginepb.EngineTypePebble || cfg.StorageEngine == enginepb.EngineTypeTeePebbleRocksDB {
details = append(details, fmt.Sprintf("Pebble cache size: %s", humanizeutil.IBytes(cfg.CacheSize)))
pebbleCache = pebble.NewCache(cfg.CacheSize)
defer pebbleCache.Unref()
}
if cfg.StorageEngine == enginepb.EngineTypeDefault ||
cfg.StorageEngine == enginepb.EngineTypeRocksDB || cfg.StorageEngine == enginepb.EngineTypeTeePebbleRocksDB {
details = append(details, fmt.Sprintf("RocksDB cache size: %s", humanizeutil.IBytes(cfg.CacheSize)))
cache = storage.NewRocksDBCache(cfg.CacheSize)
defer cache.Release()
}
var physicalStores int
for _, spec := range cfg.Stores.Specs {
if !spec.InMemory {
physicalStores++
}
}
openFileLimitPerStore, err := setOpenFileLimit(physicalStores)
if err != nil {
return Engines{}, err
}
log.Event(ctx, "initializing engines")
skipSizeCheck := cfg.TestingKnobs.Store != nil &&
cfg.TestingKnobs.Store.(*kvserver.StoreTestingKnobs).SkipMinSizeCheck
for i, spec := range cfg.Stores.Specs {
log.Eventf(ctx, "initializing %+v", spec)
var sizeInBytes = spec.Size.InBytes
if spec.InMemory {
if spec.Size.Percent > 0 {
sysMem, err := status.GetTotalMemory(ctx)
if err != nil {
return Engines{}, errors.Errorf("could not retrieve system memory")
}
sizeInBytes = int64(float64(sysMem) * spec.Size.Percent / 100)
}
if sizeInBytes != 0 && !skipSizeCheck && sizeInBytes < base.MinimumStoreSize {
return Engines{}, errors.Errorf("%f%% of memory is only %s bytes, which is below the minimum requirement of %s",
spec.Size.Percent, humanizeutil.IBytes(sizeInBytes), humanizeutil.IBytes(base.MinimumStoreSize))
}
details = append(details, fmt.Sprintf("store %d: in-memory, size %s",
i, humanizeutil.IBytes(sizeInBytes)))
if spec.StickyInMemoryEngineID != "" {
e, err := getOrCreateStickyInMemEngine(
ctx, spec.StickyInMemoryEngineID, cfg.StorageEngine, spec.Attributes, sizeInBytes,
)
if err != nil {
return Engines{}, err
}
engines = append(engines, e)
} else {
engines = append(engines, storage.NewInMem(ctx, cfg.StorageEngine, spec.Attributes, sizeInBytes))
}
} else {
if spec.Size.Percent > 0 {
fileSystemUsage := gosigar.FileSystemUsage{}
if err := fileSystemUsage.Get(spec.Path); err != nil {
return Engines{}, err
}
sizeInBytes = int64(float64(fileSystemUsage.Total) * spec.Size.Percent / 100)
}
if sizeInBytes != 0 && !skipSizeCheck && sizeInBytes < base.MinimumStoreSize {
return Engines{}, errors.Errorf("%f%% of %s's total free space is only %s bytes, which is below the minimum requirement of %s",
spec.Size.Percent, spec.Path, humanizeutil.IBytes(sizeInBytes), humanizeutil.IBytes(base.MinimumStoreSize))
}
details = append(details, fmt.Sprintf("store %d: RocksDB, max size %s, max open file limit %d",
i, humanizeutil.IBytes(sizeInBytes), openFileLimitPerStore))
var eng storage.Engine
var err error
storageConfig := base.StorageConfig{
Attrs: spec.Attributes,
Dir: spec.Path,
TsDir: cfg.TsStores.Specs[i].Path,
MaxSize: sizeInBytes,
Settings: cfg.Settings,
UseFileRegistry: spec.UseFileRegistry,
ExtraOptions: spec.ExtraOptions,
}
if cfg.StorageEngine == enginepb.EngineTypePebble {
// TODO(itsbilal): Tune these options, and allow them to be overridden
// in the spec (similar to the existing spec.RocksDBOptions and others).
pebbleConfig := storage.PebbleConfig{
StorageConfig: storageConfig,
Opts: storage.DefaultPebbleOptions(),
}
pebbleConfig.Opts.Cache = pebbleCache
pebbleConfig.Opts.MaxOpenFiles = int(openFileLimitPerStore)
eng, err = storage.NewPebble(ctx, pebbleConfig)
} else if cfg.StorageEngine == enginepb.EngineTypeRocksDB || cfg.StorageEngine == enginepb.EngineTypeDefault {
rocksDBConfig := storage.RocksDBConfig{
StorageConfig: storageConfig,
MaxOpenFiles: openFileLimitPerStore,
WarnLargeBatchThreshold: 500 * time.Millisecond,
RocksDBOptions: spec.RocksDBOptions,
}
eng, err = storage.NewRocksDB(rocksDBConfig, cache)
} else {
// cfg.StorageEngine == enginepb.EngineTypeTeePebbleRocksDB
pebbleConfig := storage.PebbleConfig{
StorageConfig: storageConfig,
Opts: storage.DefaultPebbleOptions(),
}
pebbleConfig.Dir = filepath.Join(pebbleConfig.Dir, "pebble")
pebbleConfig.Opts.Cache = pebbleCache
pebbleConfig.Opts.MaxOpenFiles = int(openFileLimitPerStore)
pebbleEng, err := storage.NewPebble(ctx, pebbleConfig)
if err != nil {
return nil, err
}
rocksDBConfig := storage.RocksDBConfig{
StorageConfig: storageConfig,
MaxOpenFiles: openFileLimitPerStore,
WarnLargeBatchThreshold: 500 * time.Millisecond,
RocksDBOptions: spec.RocksDBOptions,
}
rocksDBConfig.Dir = filepath.Join(rocksDBConfig.Dir, "rocksdb")
rocksdbEng, err := storage.NewRocksDB(rocksDBConfig, cache)
if err != nil {
return nil, err
}
eng = storage.NewTee(ctx, rocksdbEng, pebbleEng)
}
if err != nil {
return Engines{}, err
}
engines = append(engines, eng)
}
}
log.Infof(ctx, "%d storage engine%s initialized",
len(engines), util.Pluralize(int64(len(engines))))
for _, s := range details {
log.Info(ctx, s)
}
enginesCopy := engines
engines = nil
return enginesCopy, nil
}
一个 Go 函数 CreateEngines,用于初始化和创建数据库引擎(Engines)。以下是主要功能解释:
-
函数签名:
- ①. 接收一个上下文 ctx,返回一个 Engines 类型和错误 error
- ②. 函数会创建并管理数据库引擎实例
-
主要流程:
- ①. 检查是否已经创建过引擎(cfg.enginesCreated),如果是则返回错误
- ②. 如果时间序列存储配置未设置,则使用普通存储配置(cfg.TsStores = cfg.Stores)
- ③. 根据存储引擎类型(Pebble/RocksDB/TeePebbleRocksDB)设置缓存:
- ④. Pebble 引擎使用 pebble.Cache
- ⑤. RocksDB 引擎使用 storage.RocksDBCache
- ⑥. 计算物理存储数量(非内存存储)
- 设置打开文件限制(openFileLimitPerStore)
-
存储引擎创建逻辑:
- ①. 遍历所有存储配置(cfg.Stores.Specs):
- ②. 内存存储:
- 如果指定了百分比大小,则计算实际内存大小
- 检查是否满足最小存储大小要求
- 创建内存引擎(storage.NewInMem)或获取粘性内存引擎(getOrCreateStickyInMemEngine)
- ③. 磁盘存储:
- 如果指定了百分比大小,则计算实际磁盘大小
- 检查是否满足最小存储大小要求
- 根据存储引擎类型创建对应的引擎:
- Pebble 引擎:使用 storage.NewPebble
- RocksDB 引擎:使用 storage.NewRocksDB
- TeePebbleRocksDB 引擎:同时创建 Pebble 和 RocksDB 引擎,然后用 storage.NewTee 组合
-
日志记录:
- ①. 记录初始化过程中的详细信息
- ②. 最后记录创建的引擎数量
-
返回结果:
- ①. 返回创建的引擎集合
- ②. 使用 enginesCopy 返回结果,避免返回被关闭的引擎集合(engines = nil)
这段代码是数据库系统初始化的核心部分,负责根据配置创建不同类型的存储引擎实例,并进行必要的资源管理和错误检查。
// CreateTsEngine create ts engine
func (cfg *Config) CreateTsEngine(
ctx context.Context, stopper *stop.Stopper,
) (*tse.TsEngine, error) {
threadPoolSize, err := strconv.Atoi(cfg.ThreadPoolSize)
if err != nil {
return nil, err
}
taskQueueSize, err := strconv.Atoi(cfg.TaskQueueSize)
if err != nil {
return nil, err
}
bufferPoolSize, err := strconv.Atoi(cfg.BufferPoolSize)
if err != nil {
return nil, err
}
//TODO Use the rocksdb store directory +tsdb suffix
tsConfig := tse.TsEngineConfig{
Dir: cfg.TsStores.Specs[0].Path,
Settings: cfg.Settings,
ThreadPoolSize: threadPoolSize,
TaskQueueSize: taskQueueSize,
BufferPoolSize: bufferPoolSize,
LogCfg: cfg.LogConfig,
IsSingleNode: GetSingleNodeModeFlag(cfg.ModeFlag),
}
tsDB, err := tse.NewTsEngine(ctx, tsConfig, stopper)
if err != nil {
return nil, err
}
return tsDB, nil
}
-
构建时间序列引擎配置
创建一个 tse.TsEngineConfig 配置对象,包含以下内容:- Dir:时间序列数据库的存储路径,从 cfg.TsStores.Specs[0].Path 中获取。
- Settings:从 cfg.Settings 中获取的设置。
- ThreadPoolSize、TaskQueueSize、BufferPoolSize:解析后的线程池、任务队列和缓冲池大小。
- LogCfg:日志配置,从 cfg.LogConfig 中获取。
- IsSingleNode:是否为单节点模式,通过调用 GetSingleNodeModeFlag 函数根据 cfg.ModeFlag 判断。
-
创建时间序列引擎
使用 tse.NewTsEngine 函数,传入上下文、配置和停止器,创建时间序列引擎实例:
// InitNode parses node attributes and initializes the gossip bootstrap
// resolvers.
func (cfg *Config) InitNode(ctx context.Context) error {
cfg.readEnvironmentVariables()
// Initialize attributes.
cfg.NodeAttributes = parseAttributes(cfg.Attrs)
// Expose HistogramWindowInterval to parts of the code that can't import the
// server package. This code should be cleaned up within a month or two.
cfg.Config.HistogramWindowInterval = cfg.HistogramWindowInterval()
// Get the gossip bootstrap resolvers.
resolvers, err := cfg.parseGossipBootstrapResolvers(ctx)
if err != nil {
return err
}
if len(resolvers) > 0 {
cfg.GossipBootstrapResolvers = resolvers
}
return nil
}
这段代码是一个名为 InitNode 的方法,属于 Config 结构体,用于初始化节点配置,解析节点属性(如标签、元数据等),可以解析 Gossip 协议的引导节点(用于分布式系统的节点发现),如果解析引导解析器失败,直接返回错误,这段代码主要用于初始化节点相关的配置,包括环境变量、节点属性、Gossip 引导解析器等。
// Copyright 2015 The Cockroach Authors.
// Copyright (c) 2022-present, Shanghai Yunxi Technology Co, Ltd. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//
// This software (KWDB) is licensed under Mulan PSL v2.
// You can use this software according to the terms and conditions of the Mulan PSL v2.
// You may obtain a copy of Mulan PSL v2 at:
// http://license.coscl.org.cn/MulanPSL2
// THIS SOFTWARE IS PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF ANY KIND,
// EITHER EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO NON-INFRINGEMENT,
// MERCHANTABILITY OR FIT FOR A PARTICULAR PURPOSE.
// See the Mulan PSL v2 for more details.
syntax = "proto2";
package kwbase.kv.kvserver;
option go_package = "kvserver";
import "roachpb/errors.proto";
import "roachpb/metadata.proto";
import "kv/kvserver/storagepb/state.proto";
import "etcd/raft/raftpb/raft.proto";
import "gogoproto/gogo.proto";
// RaftHeartbeat is a request that contains the barebones information for a
// raftpb.MsgHeartbeat raftpb.Message. RaftHeartbeats are coalesced and sent
// in a RaftMessageRequest, and reconstructed by the receiver into individual
// raftpb.Message protos.
message RaftHeartbeat {
optional uint64 range_id = 1 [(gogoproto.nullable) = false,
(gogoproto.customname) = "RangeID",
(gogoproto.casttype) = "gitee.com/kwbasedb/kwbase/pkg/roachpb.RangeID"];
optional uint32 from_replica_id = 2 [(gogoproto.nullable) = false,
(gogoproto.customname) = "FromReplicaID",
(gogoproto.casttype) = "gitee.com/kwbasedb/kwbase/pkg/roachpb.ReplicaID"];
optional uint32 to_replica_id = 3 [(gogoproto.nullable) = false,
(gogoproto.customname) = "ToReplicaID",
(gogoproto.casttype) = "gitee.com/kwbasedb/kwbase/pkg/roachpb.ReplicaID"];
optional uint64 term = 4 [(gogoproto.nullable) = false];
optional uint64 commit = 5 [(gogoproto.nullable) = false];
optional bool quiesce = 6 [(gogoproto.nullable) = false];
// ToIsLearner was added in v19.2 to aid in the transition from preemptive
// snapshots to learner replicas. If a Replica learns its ID from a message
// which indicates that it is a learner and it is not currently a part of the
// range (due to being from a preemptive snapshot) then it must delete all of
// its data.
//
// TODO(ajwerner): remove in 20.2 once we ensure that preemptive snapshots can
// no longer be present and that we're never talking to a 19.2 node.
optional bool to_is_learner = 7 [(gogoproto.nullable) = false];
}
// RaftMessageRequest is the request used to send raft messages using our
// protobuf-based RPC codec. If a RaftMessageRequest has a non-empty number of
// heartbeats or heartbeat_resps, the contents of the message field is treated
// as a dummy message and discarded. A coalesced heartbeat request's replica
// descriptor's range ID must be zero.
message RaftMessageRequest {
optional uint64 range_id = 1 [(gogoproto.nullable) = false,
(gogoproto.customname) = "RangeID",
(gogoproto.casttype) = "gitee.com/kwbasedb/kwbase/pkg/roachpb.RangeID"];
// Optionally, the start key of the sending replica. This is only populated
// as a "hint" under certain conditions.
optional bytes range_start_key = 8 [(gogoproto.casttype) = "gitee.com/kwbasedb/kwbase/pkg/roachpb.RKey"];
optional roachpb.ReplicaDescriptor from_replica = 2 [(gogoproto.nullable) = false];
optional roachpb.ReplicaDescriptor to_replica = 3 [(gogoproto.nullable) = false];
optional raftpb.Message message = 4 [(gogoproto.nullable) = false];
// Is this a quiesce request? A quiesce request is a MsgHeartbeat
// which is requesting the recipient to stop ticking its local
// replica as long as the current Raft state matches the heartbeat
// Term/Commit. If the Term/Commit match, the recipient is marked as
// quiescent. If they don't match, the message is passed along to
// Raft which will generate a MsgHeartbeatResp that will unquiesce
// the sender.
optional bool quiesce = 5 [(gogoproto.nullable) = false];
// A coalesced heartbeat request is any RaftMessageRequest with a nonzero number of
// heartbeats or heartbeat_resps.
repeated RaftHeartbeat heartbeats = 6 [(gogoproto.nullable) = false];
repeated RaftHeartbeat heartbeat_resps = 7 [(gogoproto.nullable) = false];
// Is this a TIME SERIES request? if so, drop msg app while replica split.
optional bool req_type = 9 [(gogoproto.nullable) = false];
}
message RaftMessageRequestBatch {
repeated RaftMessageRequest requests = 1 [(gogoproto.nullable) = false];
}
message RaftMessageResponseUnion {
option (gogoproto.onlyone) = true;
optional roachpb.Error error = 1;
}
// RaftMessageResponse may be sent to the sender of a
// RaftMessageRequest. RaftMessage does not use the usual
// request/response pattern; it is primarily modeled as a one-way
// stream of requests. Normal 'responses' are usually sent as new
// requests on a separate stream in the other direction.
// RaftMessageResponse is not sent for every RaftMessageRequest, but
// may be used for certain error conditions.
message RaftMessageResponse {
optional uint64 range_id = 1 [(gogoproto.nullable) = false,
(gogoproto.customname) = "RangeID",
(gogoproto.casttype) = "gitee.com/kwbasedb/kwbase/pkg/roachpb.RangeID"];
optional roachpb.ReplicaDescriptor from_replica = 2 [(gogoproto.nullable) = false];
optional roachpb.ReplicaDescriptor to_replica = 3 [(gogoproto.nullable) = false];
optional RaftMessageResponseUnion union = 4 [(gogoproto.nullable) = false];
}
// SnapshotRequest is the request used to send streaming snapshot requests.
message SnapshotRequest {
enum Priority {
UNKNOWN = 0;
// RECOVERY is used for a Raft-initiated snapshots and for
// up-replication snapshots (i.e. when a dead node has been
// removed and the range needs to be up-replicated).
RECOVERY = 1;
// REBALANCE is used for snapshots involved in rebalancing.
REBALANCE = 2;
}
enum Strategy {
// KV_BATCH snapshots stream batches of KV pairs for all keys in a
// range from the sender the the receiver. These KV pairs are then
// combined into a large RocksDB WriteBatch that is atomically
// applied.
KV_BATCH = 0;
// TS_BATCH snapshots stream batches of bytes in a range from the
// sender the the receiver.
TS_BATCH = 1;
}
enum Type {
RAFT = 0;
LEARNER = 1;
reserved 2;
}
message Header {
reserved 1;
// The replica state at the time the snapshot was generated. Note
// that ReplicaState.Desc differs from the above range_descriptor
// field which holds the updated descriptor after the new replica
// has been added while ReplicaState.Desc holds the descriptor
// before the new replica has been added.
optional storagepb.ReplicaState state = 5 [(gogoproto.nullable) = false];
// The inner raft message is of type MsgSnap, and its snapshot data contains a UUID.
optional RaftMessageRequest raft_message_request = 2 [(gogoproto.nullable) = false];
// The estimated size of the range, to be used in reservation decisions.
optional int64 range_size = 3 [(gogoproto.nullable) = false];
// can_decline is set on preemptive snapshots, but not those generated
// by raft because at that point it is better to queue up the stream
// than to cancel it.
optional bool can_decline = 4 [(gogoproto.nullable) = false];
// The priority of the snapshot.
optional Priority priority = 6 [(gogoproto.nullable) = false];
// The strategy of the snapshot.
optional Strategy strategy = 7 [(gogoproto.nullable) = false];
// The type of the snapshot.
optional Type type = 9 [(gogoproto.nullable) = false];
// Whether the snapshot uses the unreplicated RaftTruncatedState or not.
// This is generally always true at 2.2 and above outside of the migration
// phase, though theoretically it could take a long time for all ranges
// to update to the new mechanism. This bool is true iff the Raft log at
// the snapshot's applied index is using the new key. In particular, it
// is true if the index itself carries out the migration (in which case
// the data in the snapshot contains neither key).
//
// See VersionUnreplicatedRaftTruncatedState.
optional bool unreplicated_truncated_state = 8 [(gogoproto.nullable) = false];
}
optional Header header = 1;
// A RocksDB BatchRepr. Multiple kv_batches may be sent across multiple request messages.
optional bytes kv_batch = 2 [(gogoproto.customname) = "KVBatch"];
// A TS data. Multiple kv_batches may be sent across multiple request messages.
optional bytes ts_batch = 5 [(gogoproto.customname) = "TSBatch"];
optional bytes ts_meta = 13 [(gogoproto.customname) = "TSMeta"];
// Init ts snapshot for write
optional bool init_ts_snapshot_for_write = 6 [(gogoproto.nullable) = false];
optional uint64 ts_table_id = 7 [(gogoproto.nullable) = false];
optional uint64 ts_snapshot_id = 8 [(gogoproto.nullable) = false];
// These are really raftpb.Entry, but we model them as raw bytes to avoid
// roundtripping through memory. They are separate from the kv_batch to
// allow flexibility in log implementations.
repeated bytes log_entries = 3;
optional bool final = 4 [(gogoproto.nullable) = false];
}
message SnapshotResponse {
enum Status {
UNKNOWN = 0;
ACCEPTED = 1;
APPLIED = 2;
ERROR = 3;
DECLINED = 4;
}
optional Status status = 1 [(gogoproto.nullable) = false];
optional string message = 2 [(gogoproto.nullable) = false];
reserved 3;
}
// ConfChangeContext is encoded in the raftpb.ConfChange.Context field.
message ConfChangeContext {
optional string command_id = 1 [(gogoproto.nullable) = false,
(gogoproto.customname) = "CommandID"];
// Payload is the application-level command (i.e. an encoded
// storagepb.RaftCommand).
optional bytes payload = 2;
}
这是KWDB分布式系统中的一个核心协议文件,主要用于定义Raft一致性协议相关的消息结构。其主要功能包括:
-
RaftHeartbeat
- ①. 实现节点间心跳机制
- ②. 包含range_id、term、commit等Raft协议核心参数
- ③. 用于检测节点存活和状态同步
-
RaftMessageRequest
- ①. Raft节点间通信的主要载体
- ②.支持普通消息和合并心跳消息的传输
- ③. 包含完整的节点描述信息
-
SnapshotRequest
- ①. 实现节点间数据快照传输
- ②. 支持多种优先级:
- RECOVERY: 用于Raft发起的快照和副本恢复
- REBALANCE: 用于负载均衡场景
- ③. 支持多种传输策略:
- KV_BATCH: KV对批量传输
- TS_BATCH: 时序数据批量传输
这个文件是KWDB实现分布式一致性的核心协议定义,确保了集群中各节点可以进行可靠的状态同步和数据复制。
六、企业数据化系统建设阶段后续:
随着技术的飞速发展,企业对数据的需求不断增长,数据已然成为企业的宝贵资产之一,但我们不仅要收集和存储数据,更要挖掘和利用数据。数据仓库已经成为了企业信息化建设的重要组成部分。将企业内部各个部门的数据整合在一起,形成一个统一的数据视图。这样,企业决策者可以更加方便地获取所需的信息,从而提高决策效率。
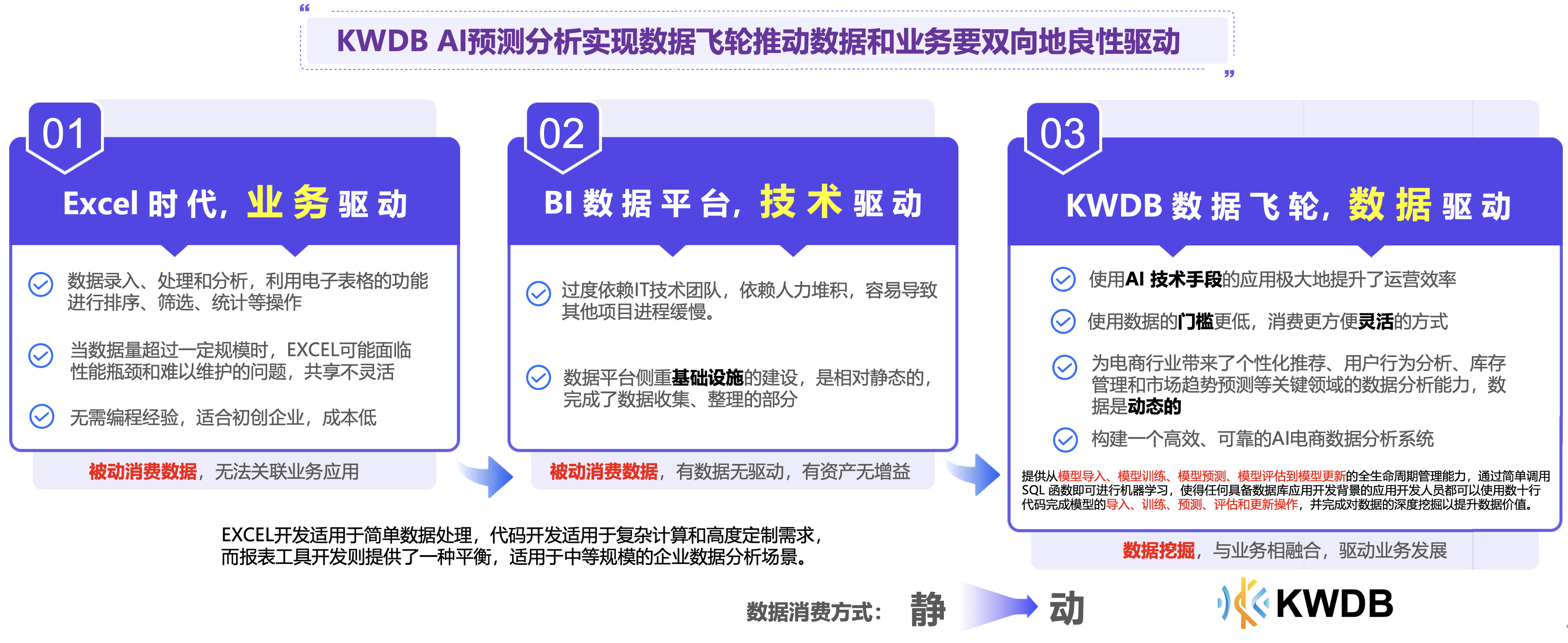
KWDB 提供可插拔的 AI 分析预测引擎,提供从模型导入、模型训练、模型预测、模型评估到模型更新的全生命周期管理能力,通过简单调用 SQL 函数即可进行机器学习相关操作,使得任何具备数据库应用开发背景的应用开发人员都可以使用数十行代码完成模型的导入、训练、预测、评估和更新操作,并完成对数据的深度挖掘以提升数据价值, 可以促进数据飞轮实现跨业务条线、跨系统的数据整合,为管理分析和业务决策提供统一的数据支持。
总结:
KWDB通过创新性的多模架构打破了传统数据库的边界限制,采用行列混存的存储架构与分布式高可用设计,实现了时序数据与关系数据的统一存储管理。其内核内置通用数据模型,支持两种数据模型的自动适配与联合查询,避免了传统方案中跨库关联的性能瓶颈。
KaiwuDB以多模融合内核统一时序与关系型数据模型,实现透明化数据管理,满足单一及复杂多模场景需求。采用无中心分布式架构,支持自动分片、EB级线性扩展,基于RAFT协议保障强一致性与高可用故障自愈。
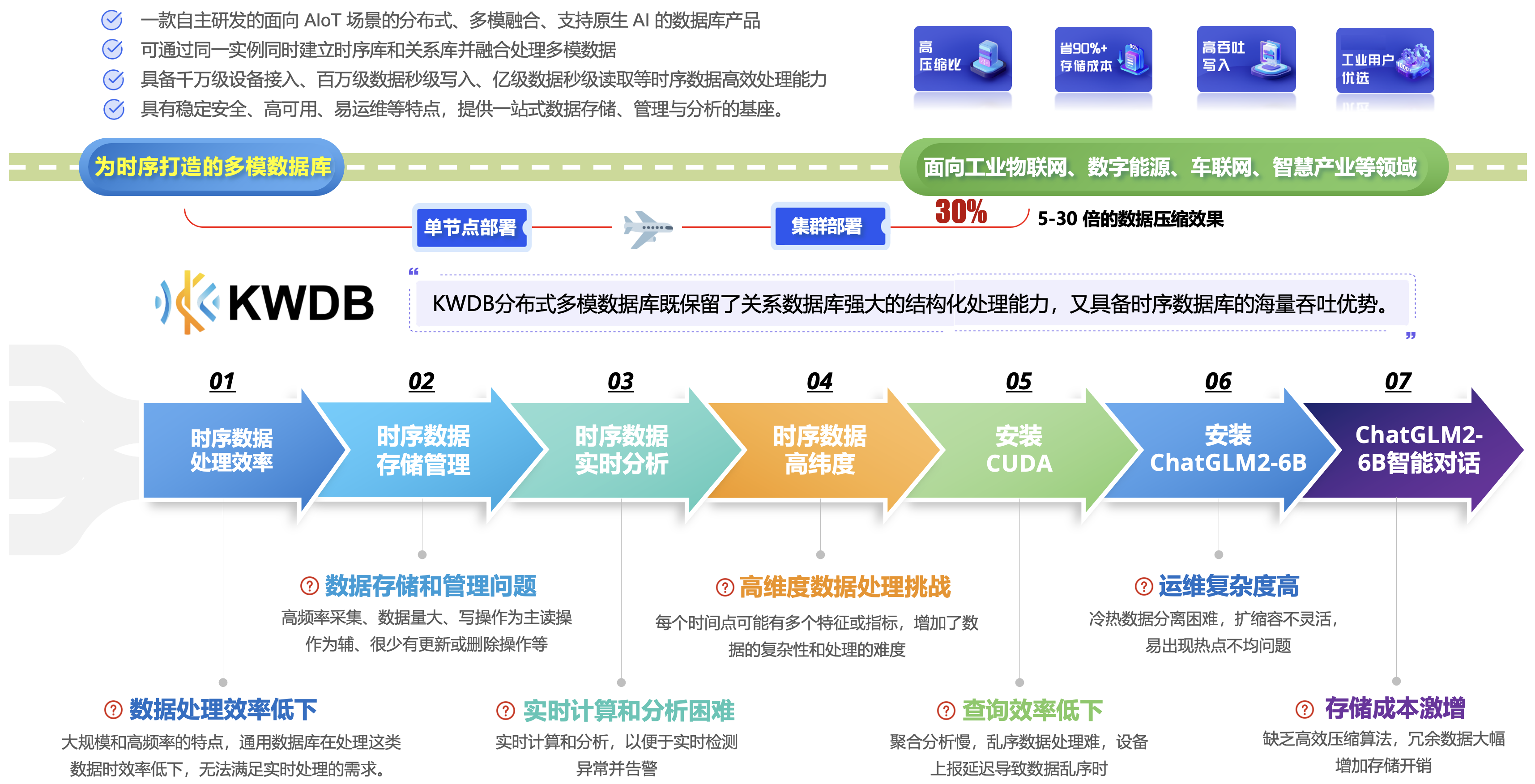
高性能读写达百万行/秒写入与纳秒精度,时序表优化结合就地计算技术,实现亿级数据聚合秒级响应。提供丰富时序函数与实时数据推送能力。低成本存储通过压缩算法(5-30倍压缩率)、冷热分级存储及生命周期管理显著降低存储成本。
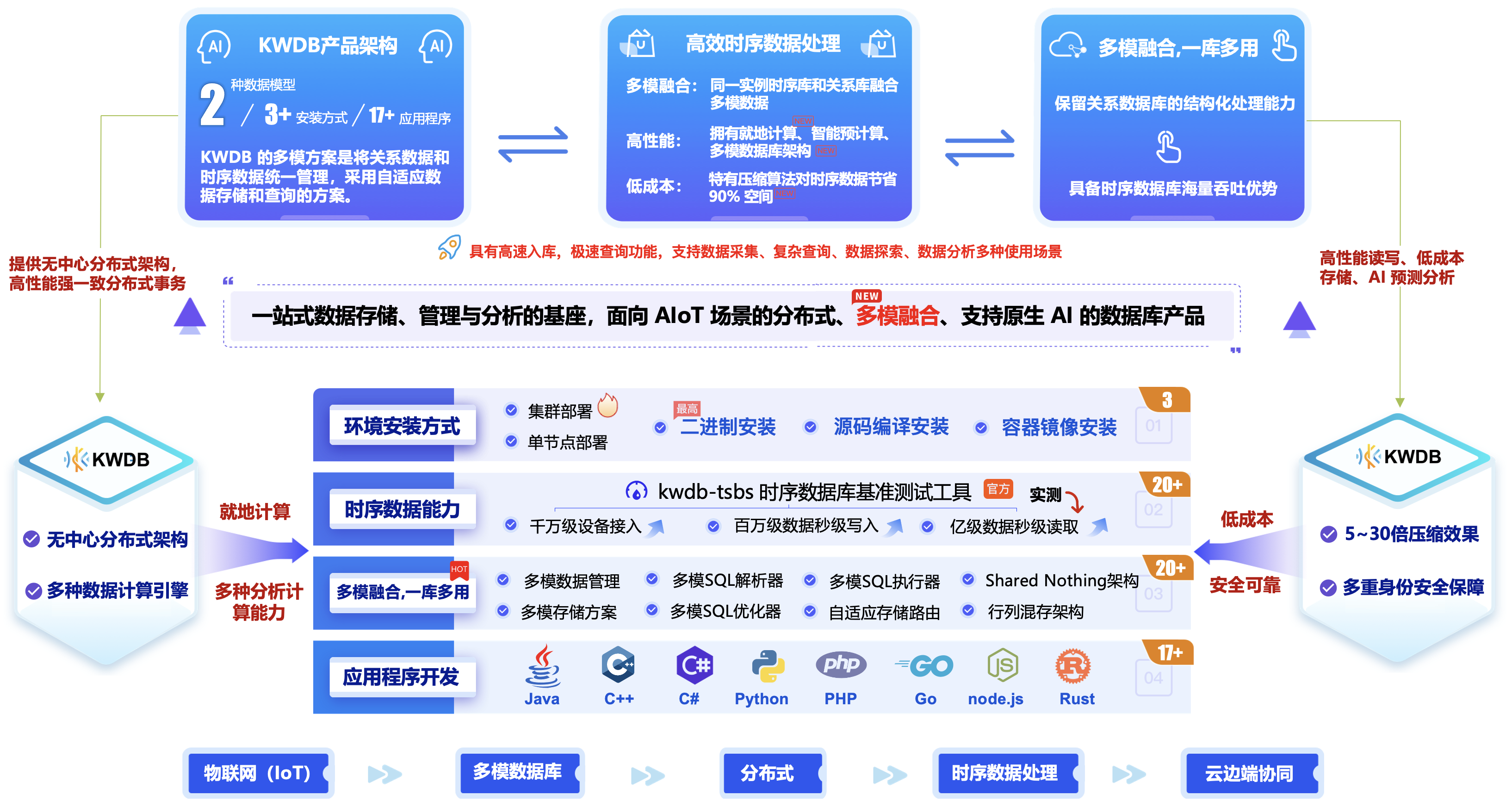
在净水机物联网场景中,KWDB可以替代原有的MySQL+MongoDB+PostgreSQL多库架构,将设备属性、用户合同等关系数据与实时水质监测时序数据进行一体化存储。通过内置的时序压缩算法(压缩比高达10:1)和分布式执行引擎,既能支撑每秒百万级数据写入,又可实现毫秒级跨模关联查询。
相比分层式数据中台架构,该方案精简了40%的硬件资源消耗,并通过Raft协议保障多副本数据一致性,使得故障切换时间缩短至秒级。这种"一库多用"的特性,为工业物联网场景提供了兼具实时处理能力与复杂事务支持的技术基座。
更多推荐
 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)